







一种显著改进RAG中检索步骤的方法:上下文检
原文链接: https://www.anthropic.com/news/contextual-retrieval
为了使AI模型在特定环境下发挥作用,它通常需要访问背景知识。例如,客户支持聊天机器人需要了解其所用业务的具体信息,而法律分析机器人则需要了解大量过往案例。
开发人员通常使用检索增强生成 (RAG) 来增强AI模型的知识。RAG是一种从知识库中检索相关信息并将其添加到用户提示的方法,从而显著增强模型的响应能力。问题在于,传统的RAG解决方案在编码信息时会去除上下文,这往往会导致系统无法从知识库中检索相关信息。
In this post, we outline a method that dramatically improves the retrieval step in RAG. The method is called “Contextual Retrieval” and uses two sub-techniques: Contextual Embeddings and Contextual BM25. This method can reduce the number of failed retrievals by 49% and, when combined with reranking, by 67%. These represent significant improvements in retrieval accuracy, which directly translates to better performance in downstream tasks.
在这篇文章中,我们概述了一种显著改进RAG中检索步骤的方法。这种方法称为“上下文检索”,它使用了两种子技术:上下文嵌入和上下文BM25。此方法可以将检索失败的次数减少49%,结合重新排序后,则减少67%。这些都代表着检索准确性的显著提高,这直接转化为下游任务的更好性能。
关于直接使用更长提示的说明
有时候,最简单的解决方案就是最好的方案。如果你的知识库小于20万个token(大约500页资料),你可以直接将整个知识库包含在提供给模型的提示中,无需使用RAG或类似的方法。
ps: 这个有点夸张吧,不知道有无数据支撑。小伙伴懂得可以评论区留言。
A few weeks ago, we released prompt caching for Claude, which makes this approach significantly faster and more cost-effective. Developers can now cache frequently used prompts between API calls, reducing latency by > 2x and costs by up to 90% (you can see how it works by reading our prompt caching cookbook).
几周前,我们为 Claude 发布了 提示缓存 功能,这使得这种方法显著加快并降低了成本。开发人员现在可以在 API 调用之间缓存常用提示,从而将延迟降低 > 2 倍,并将成本降低高达 90%(您可以阅读我们的 提示缓存指南 来了解其工作原理)
然而,随着知识库的增长,您将需要更具可扩展性的解决方案。这就是上下文检索发挥作用的地方。
RAG入门:扩展到更大的知识库
对于无法容纳在上下文窗口中的大型知识库,检索增强生成 (RAG) 是典型的解决方案。RAG 通过以下步骤预处理知识库:
-
Break down the knowledge base (the “corpus” of documents) into smaller chunks of text, usually no more than a few hundred tokens;
将知识库(即文档“语料库”)分解成更小的文本块,通常不超过几tokens; -
Use an embedding model to convert these chunks into vector embeddings that encode meaning;
使用嵌入模型将这些片段转换为编码语义的向量嵌入; -
Store these embeddings in a vector database that allows for searching by semantic similarity.
将这些嵌入存储在一个允许根据语义相似性搜索的向量数据库中。
At runtime, when a user inputs a query to the model, the vector database is used to find the most relevant chunks based on semantic similarity to the query. Then, the most relevant chunks are added to the prompt sent to the generative model.
运行时,当用户向模型输入查询时,向量数据库用于根据与查询的语义相似性查找最相关的片段。然后,将最相关的片段添加到发送到生成模型的提示中。
While embedding models excel at capturing semantic relationships, they can miss crucial exact matches. Fortunately, there’s an older technique that can assist in these situations. BM25 (Best Matching 25) is a ranking function that uses lexical matching to find precise word or phrase matches. It’s particularly effective for queries that include unique identifiers or technical terms.
虽然嵌入式模型擅长捕捉语义关系,但它们可能会错过关键的精确匹配。幸运的是,有一种较旧的技术可以帮助解决这些情况。BM25(最佳匹配25)是一种使用词法匹配来查找精确单词或短语匹配的排序函数。它对于包含唯一标识符或技术术语的查询特别有效。
BM25 works by building upon the TF-IDF (Term Frequency-Inverse Document Frequency) concept. TF-IDF measures how important a word is to a document in a collection. BM25 refines this by considering document length and applying a saturation function to term frequency, which helps prevent common words from dominating the results.
BM25 基于 TF-IDF (词频-逆文档频率) 概念构建。TF-IDF 衡量某个词对文档集中的文档的重要性。BM25 通过考虑文档长度并对词频应用饱和函数来改进这一点,这有助于防止常用词支配结果。
Here’s how BM25 can succeed where semantic embeddings fail: Suppose a user queries “Error code TS-999” in a technical support database. An embedding model might find content about error codes in general, but could miss the exact “TS-999” match. BM25 looks for this specific text string to identify the relevant documentation.
BM25 在语义嵌入失败的地方如何成功:假设用户在一个技术支持数据库中查询“错误代码 TS-999”。嵌入模型可能会找到关于错误代码的一般性内容,但可能会错过精确的“TS-999”匹配。BM25 会查找此特定文本字符串以识别相关的文档。
RAG solutions can more accurately retrieve the most applicable chunks by combining the embeddings and BM25 techniques using the following steps:
RAG解决方案可以通过以下步骤结合嵌入和BM25技术,更准确地检索最适用的片段:
-
Break down the knowledge base (the “corpus” of documents) into smaller chunks of text, usually no more than a few hundred tokens;
将知识库(即文档“语料库”)分解成更小的文本块,通常不超过几百个token; -
Create TF-IDF encodings and semantic embeddings for these chunks;
为这些片段创建 TF-IDF 编码和语义嵌入; -
Use BM25 to find top chunks based on exact matches;
使用BM25算法根据精确匹配查找最佳片段; -
Use embeddings to find top chunks based on semantic similarity;
使用嵌入查找基于语义相似性的最佳片段; -
Combine and deduplicate results from (3) and (4) using rank fusion techniques;
使用rank fusion技术合并并去重步骤(3)和(4)的结果; -
Add the top-K chunks to the prompt to generate the response.
将前 K 个片段添加到提示中以生成回复。
通过结合 BM25 和嵌入模型,传统的 RAG 系统可以提供更全面、更准确的结果,平衡精确的术语匹配和更广泛的语义理解。
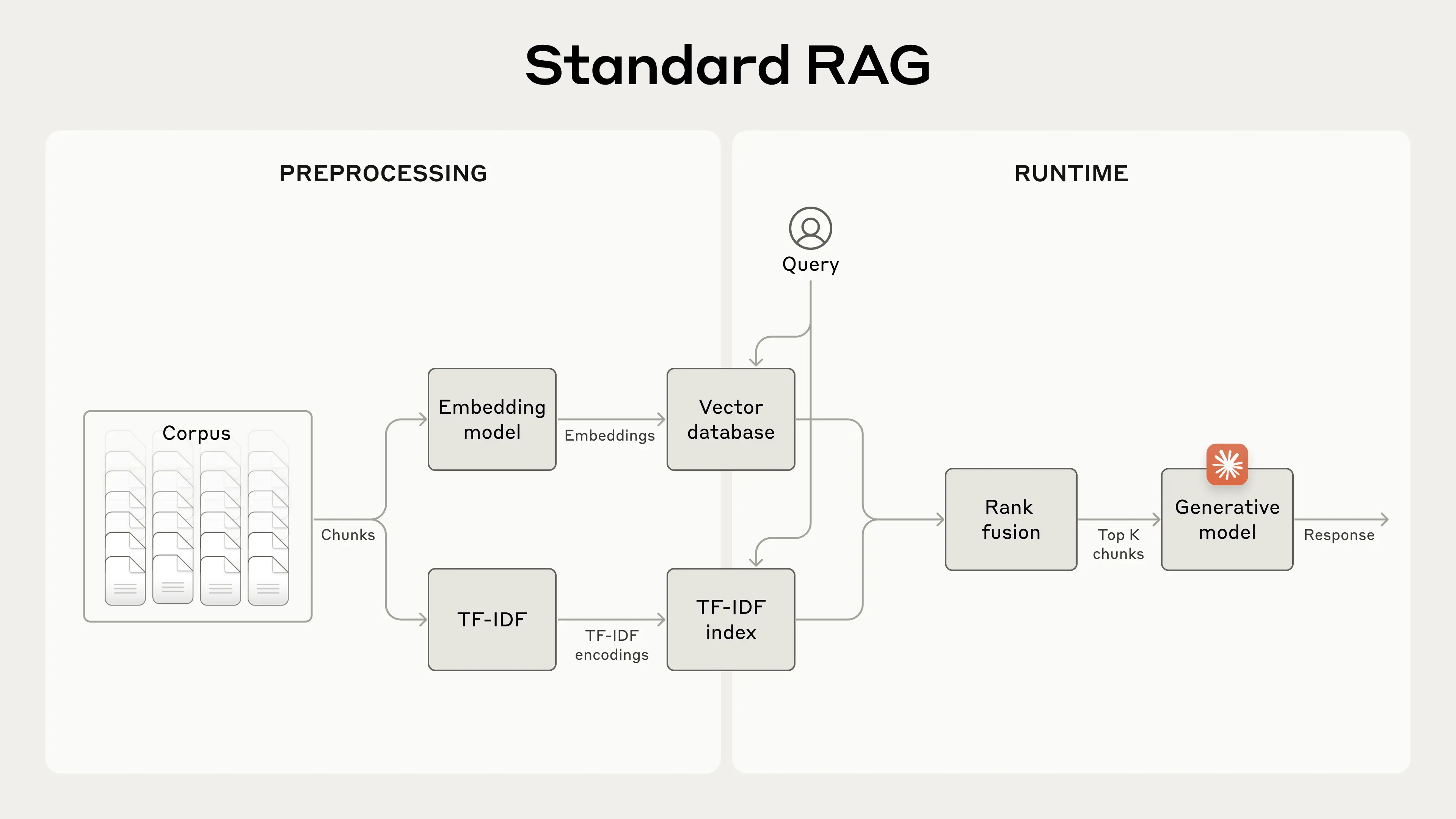
A Standard Retrieval-Augmented Generation (RAG) system that uses both embeddings and Best Match 25 (BM25) to retrieve information. TF-IDF (term frequency-inverse document frequency) measures word importance and forms the basis for BM25.
一种标准的检索增强生成 (RAG) 系统,它同时使用嵌入和最佳匹配 25 (BM25) 来检索信息。TF-IDF(词频-逆文档频率)衡量词语的重要性,并构成 BM25 的基础。
This approach allows you to cost-effectively scale to enormous knowledge bases, far beyond what could fit in a single prompt. But these traditional RAG systems have a significant limitation: they often destroy context.
此方法允许您经济高效地扩展到海量的知识库,远远超出单个提示符所能容纳的范围。但这些传统的 RAG 系统有一个显著的局限性:它们经常破坏上下文。
传统RAG中的上下文难题
在传统的RAG中,文档通常被分割成更小的块以提高检索效率。虽然这种方法适用于许多应用,但当单个块缺乏足够的上下文时,可能会导致问题。
For example, imagine you had a collection of financial information (say, U.S. SEC filings) embedded in your knowledge base, and you received the following question: “What was the revenue growth for ACME Corp in Q2 2023?”
例如,假设你的知识库中包含一些财务信息(例如,美国证券交易委员会的申报文件),你收到了以下问题:“ACME公司2023年第二季度的营收增长是多少?”
一个相关的片段可能包含文本:“该公司收入比上一季度增长了3%。” 但是,仅此片段本身并没有指明所指的是哪家公司,也没有说明相关的时间段,这使得难以检索到正确的信息或有效地使用这些信息。
引入上下文检索
Contextual Retrieval solves this problem by prepending chunk-specific explanatory context to each chunk before embedding (“Contextual Embeddings”) and creating the BM25 index (“Contextual BM25”).
上下文检索通过在嵌入之前为每个片段添加特定于片段的解释性上下文(“上下文嵌入”)并创建 BM25 索引(“上下文 BM25”)来解决这个问题。
我们回到SEC文件收集的例子。下面是一个片段转换的示例:
original_chunk = "The company's revenue grew by 3% over the previous quarter."
contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."
It is worth noting that other approaches to using context to improve retrieval have been proposed in the past. Other proposals include: adding generic document summaries to chunks (we experimented and saw very limited gains), hypothetical document embedding, and summary-based indexing (we evaluated and saw low performance). These methods differ from what is proposed in this post.
值得注意的是,过去已经提出了其他利用上下文改进检索的方法。其他方案包括:向片段添加通用文档摘要(我们进行了实验,但收益非常有限),假设文档嵌入,以及基于摘要的索引(我们进行了评估,发现性能较低)。这些方法与本文提出的方法有所不同。
上下文检索的实现
Of course, it would be far too much work to manually annotate the thousands or even millions of chunks in a knowledge base. To implement Contextual Retrieval, we turn to Claude. We’ve written a prompt that instructs the model to provide concise, chunk-specific context that explains the chunk using the context of the overall document. We used the following Claude 3 Haiku prompt to generate context for each chunk:
当然,手动标注知识库中数千甚至数百万个片段的工作量实在太大。为了实现上下文检索,我们求助于 Claude。我们编写了一个提示,指示模型提供简洁的、特定于片段的上下文,使用整个文档的上下文来解释该片段。我们使用了以下 Claude 3 Haiku 来为每个片段生成上下文:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
The resulting contextual text, usually 50-100 tokens, is prepended to the chunk before embedding it and before creating the BM25 index.
生成的上下文文本,通常为 50-100 个tokens,会在嵌入之前和创建 BM25 索引之前添加到chunk块的前面。
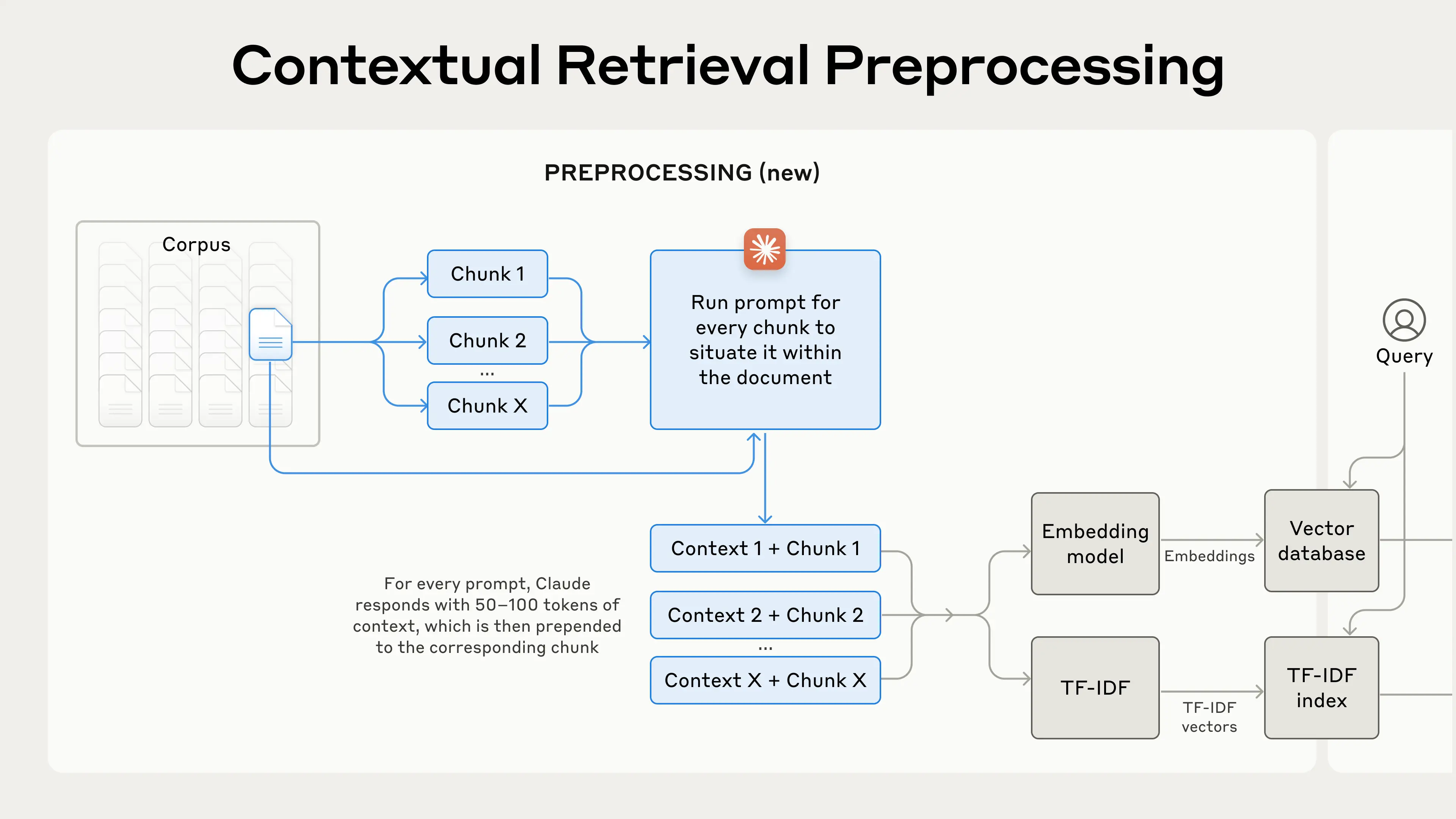
Contextual Retrieval is a preprocessing technique that improves retrieval accuracy.
上下文检索是一种提高检索精度的预处理技术。
If you’re interested in using Contextual Retrieval, you can get started with our cookbook.
如果你对使用上下文检索感兴趣,可以参考我们的教程。https://github.com/anthropics/anthropic-cookbook/tree/main/skills/contextual-embeddings
使用提示缓存降低上下文检索的成本
Contextual Retrieval is uniquely possible at low cost with Claude, thanks to the special prompt caching feature we mentioned above. With prompt caching, you don’t need to pass in the reference document for every chunk. You simply load the document into the cache once and then reference the previously cached content. Assuming 800 token chunks, 8k token documents, 50 token context instructions, and 100 tokens of context per chunk, the one-time cost to generate contextualized chunks is $1.02 per million document tokens.
借助我们上面提到的特殊提示缓存功能,Claude 可以以低成本独家实现上下文检索。有了提示缓存,您无需为每个片段都传入参考文档。您只需将文档一次性加载到缓存中,然后引用之前缓存的内容。假设有 800 个 token 的片段,8000 个 token 的文档,50 个 token 的上下文指令,以及每个片段 100 个 token 的上下文,生成上下文片段的一次性成本为每百万个文档 token 1.02 美元。
Methodology方法论
We experimented across various knowledge domains (codebases, fiction, ArXiv papers, Science Papers), embedding models, retrieval strategies, and evaluation metrics. We’ve included a few examples of the questions and answers we used for each domain in Appendix II.
我们在不同的知识领域(代码库、小说、ArXiv论文、科学论文)、嵌入模型、检索策略和评估指标上进行了实验。我们在附录二中包含了一些我们针对每个领域使用的问答示例。
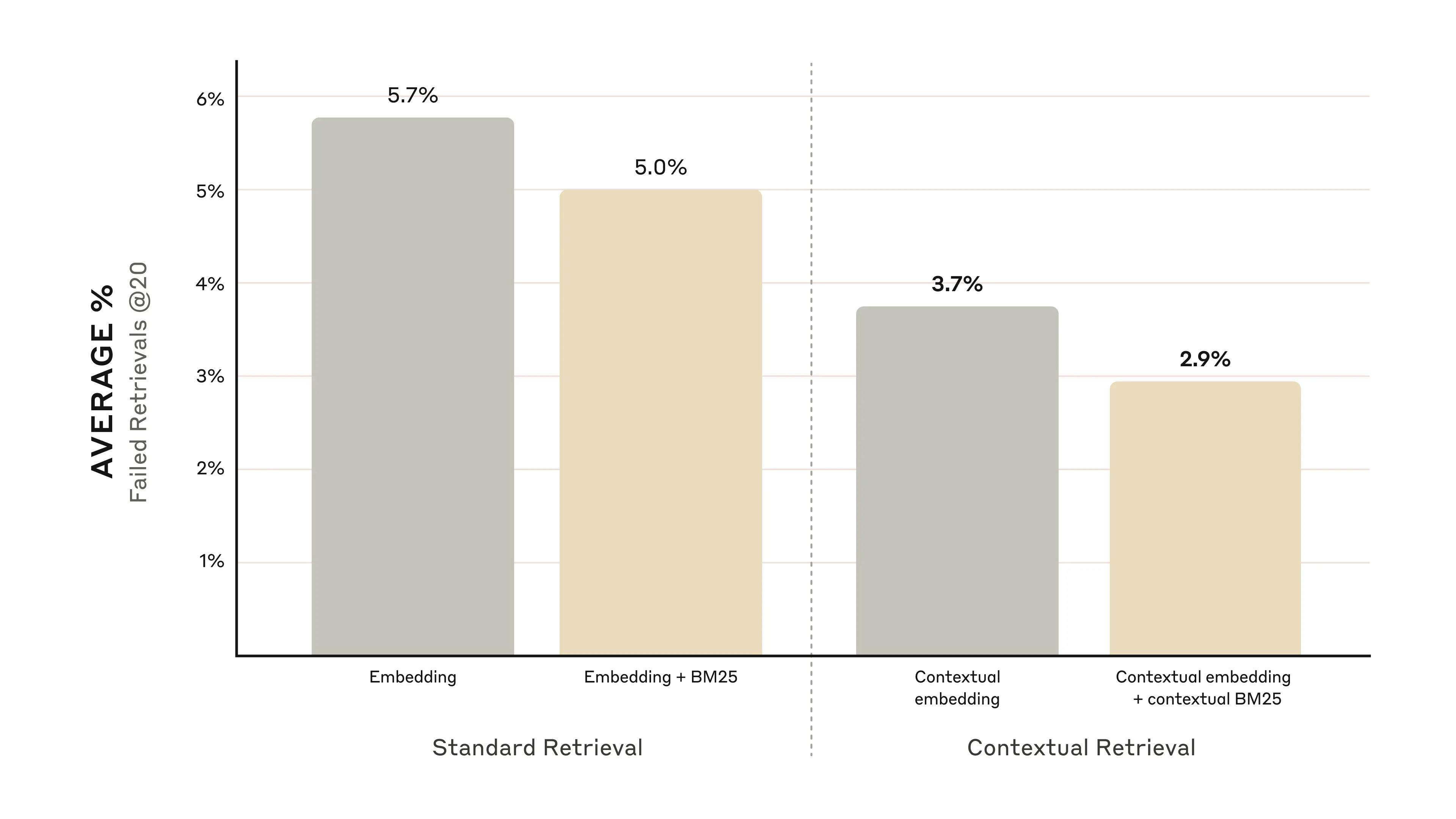
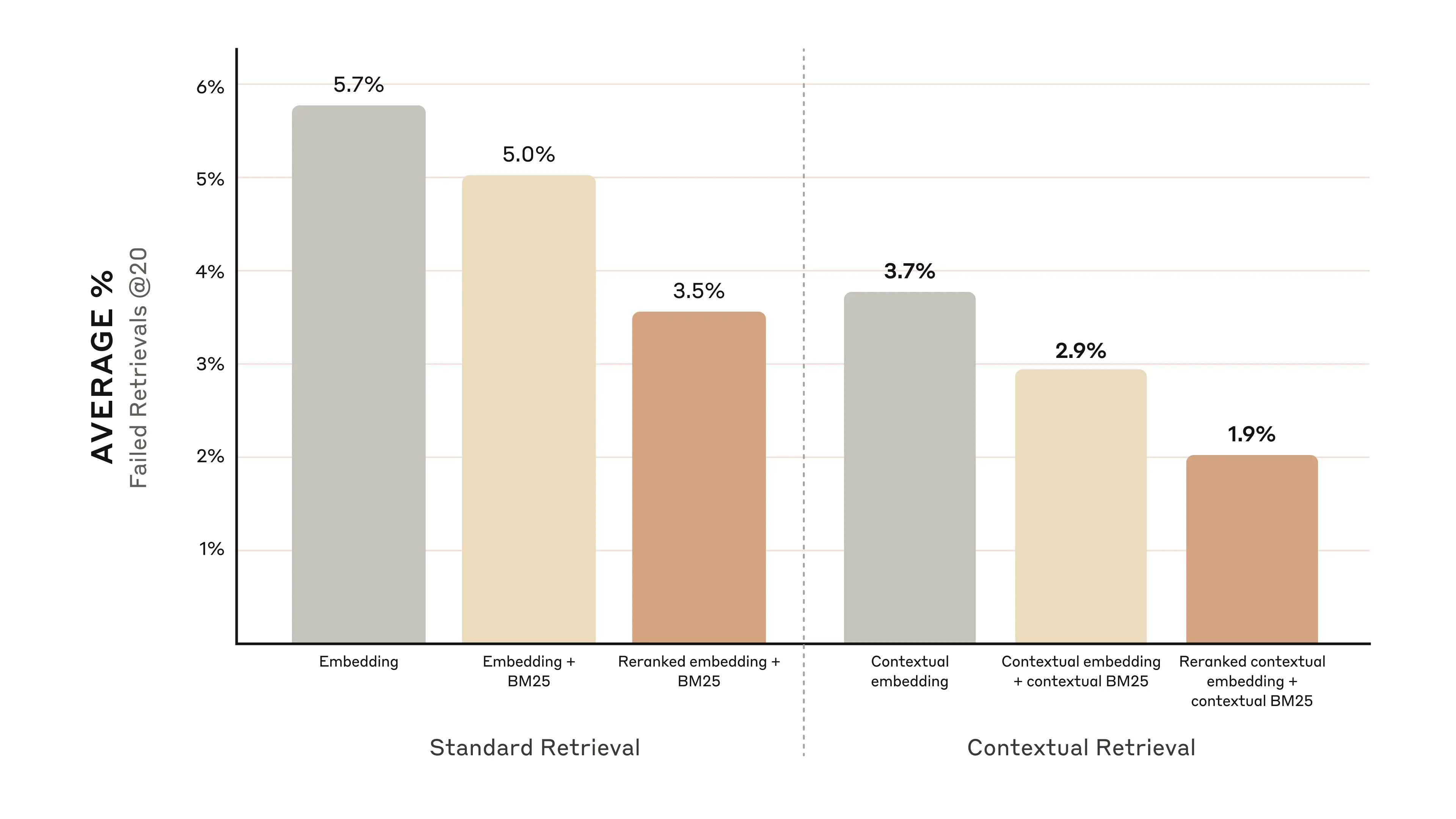
The graphs below show the average performance across all knowledge domains with the top-performing embedding configuration (Gemini Text 004) and retrieving the top-20-chunks. We use 1 minus recall@20 as our evaluation metric, which measures the percentage of relevant documents that fail to be retrieved within the top 20 chunks. You can see the full results in the appendix - contextualizing improves performance in every embedding-source combination we evaluated.
下图显示了所有知识领域在最佳嵌入配置(Gemini Text 004)和检索前 20 个片段时的平均性能。我们使用 1 减去召回率@20 作为评估指标,该指标衡量的是未能检索到前 20 个片段中相关文档的百分比。完整的实验结果见附录——在所有我们评估的嵌入源组合中,语境化都提高了性能。
性能提升
我们的实验表明:
Contextual Embeddings reduced the top-20-chunk retrieval failure rate by 35% (5.7% → 3.7%).
上下文嵌入使前20个片段的检索失败率降低了35% (5.7% → 3.7%).
Combining Contextual Embeddings and Contextual BM25 reduced the top-20-chunk retrieval failure rate by 49% (5.7% → 2.9%).
结合上下文嵌入和上下文BM25将前20个片段的检索失败率降低了49% (5.7% → 2.9%).
实现方面的考虑
上下文检索的实现需要考虑以下几点:
Chunk boundaries: Consider how you split your documents into chunks. The choice of chunk size, chunk boundary, and chunk overlap can affect retrieval performance1.
分块边界: 考虑如何将文档分割成块。分块大小、分块边界和分块重叠的选择会影响检索性能1。
Embedding model: Whereas Contextual Retrieval improves performance across all embedding models we tested, some models may benefit more than others. We found Gemini and Voyage embeddings to be particularly effective.
嵌入模型: 虽然上下文检索提高了我们测试的所有嵌入模型的性能,但有些模型可能受益更多。我们发现Gemini和Voyage嵌入特别有效。
Custom contextualizer prompts: While the generic prompt we provided works well, you may be able to achieve even better results with prompts tailored to your specific domain or use case (for example, including a glossary of key terms that might only be defined in other documents in the knowledge base).
自定义上下文提示词: 我们提供的通用提示词效果很好,但您可以通过针对特定领域或用例定制提示词来获得更好的结果(例如,包含可能仅在知识库中其他文档中定义的关键术语词汇表)。
Number of chunks: Adding more chunks into the context window increases the chances that you include the relevant information. However, more information can be distracting for models so there’s a limit to this. We tried delivering 5, 10, and 20 chunks, and found using 20 to be the most performant of these options (see appendix for comparisons) but it’s worth experimenting on your use case.
分块数量: 向上下文窗口中添加更多分块可以增加包含相关信息的可能性。但是,过多的信息可能会分散模型的注意力,因此对此有所限制。我们尝试了 5、10 和 20 个分块,发现使用 20 个分块的性能最佳(参见附录中的比较),但值得根据您的用例进行试验。
通过重排序进一步提升性能
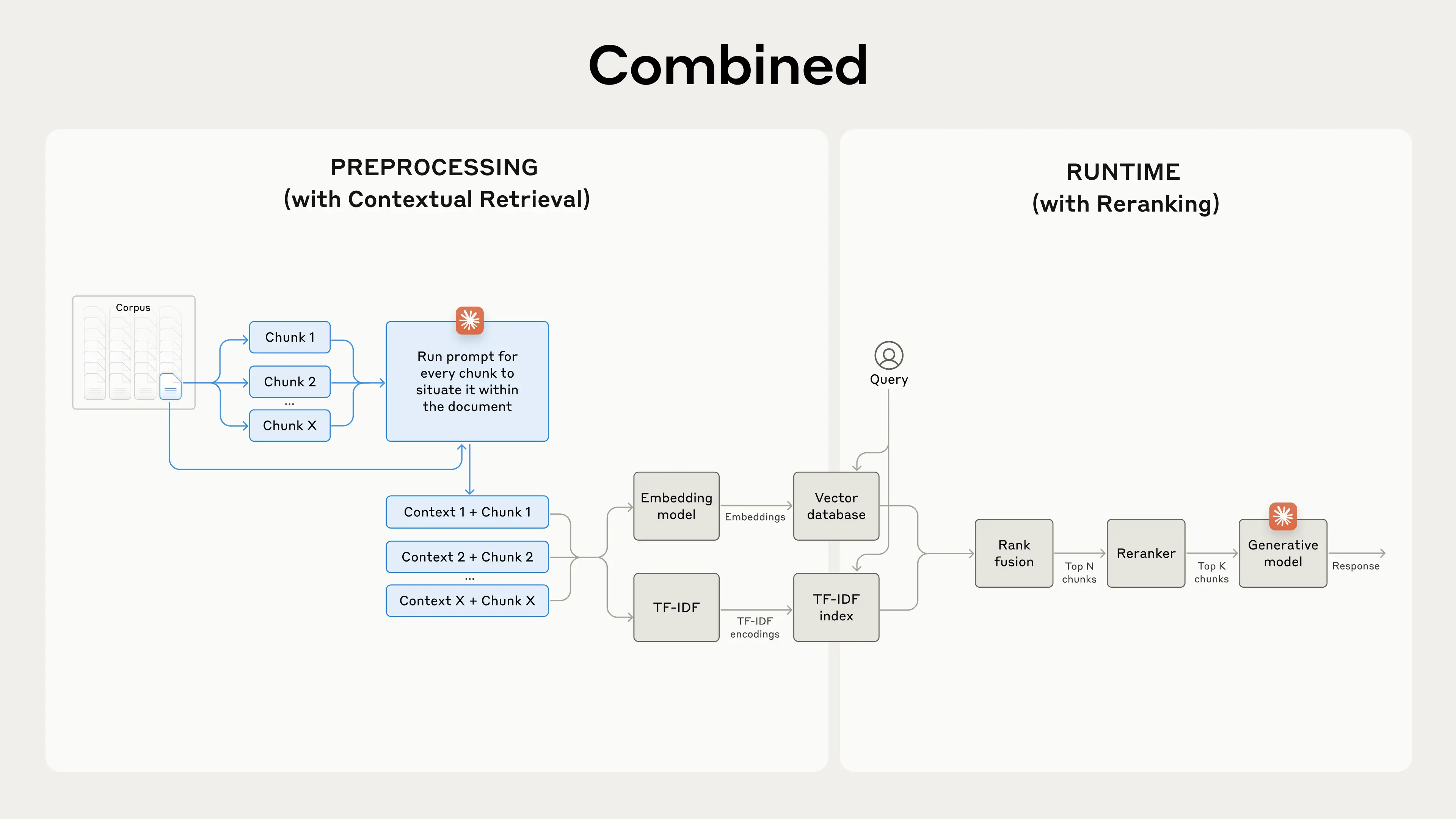
最后一步,我们可以将上下文检索与另一种技术结合起来,以获得更高的性能提升。在传统的 RAG 中,AI 系统会搜索其知识库以查找可能相关的的信息片段。对于大型知识库,这种初始检索通常会返回许多片段——有时数百个——这些片段的相关性和重要性各不相同。
重排序是一种常用的过滤技术,用于确保只有最相关的片段被传递到模型。重排序可以提供更好的响应,并降低成本和延迟,因为模型处理的信息更少。
Perform initial retrieval to get the top potentially relevant chunks (we used the top 150);
执行初始检索以获取前 N 个潜在相关的片段(我们使用了前 150 个);
Pass the top-N chunks, along with the user’s query, through the reranking model;
将前 N 个片段以及用户的查询传递给重排序模型;
Using a reranking model, give each chunk a score based on its relevance and importance to the prompt, then select the top-K chunks (we used the top 20);
使用重排序模型,根据每个片段与提示的相关性和重要性为其评分,然后选择前 K 个片段(我们使用了前 20 个);
Pass the top-K chunks into the model as context to generate the final result.
将前 K 个片段作为上下文传递到模型中以生成最终结果。
性能提升
There are several reranking models on the market. We ran our tests with the Cohere reranker. Voyage also offers a reranker, though we did not have time to test it. Our experiments showed that, across various domains, adding a reranking step further optimizes retrieval.
市面上有多种重排序模型。我们使用Cohere重排序器进行了测试。Voyage也提供重排序器,但我们没有时间进行测试。我们的实验表明,在各个领域,添加重排序步骤可以进一步优化检索。
Specifically, we found that Reranked Contextual Embedding and Contextual BM25 reduced the top-20-chunk retrieval failure rate by 67% (5.7% → 1.9%).
具体而言,我们发现重新排序的上下文嵌入和上下文 BM25 将前 20 个片段的检索失败率降低了 67%(5.7% → 1.9%)。
成本和延迟考虑
One important consideration with reranking is the impact on latency and cost, especially when reranking a large number of chunks. Because reranking adds an extra step at runtime, it inevitably adds a small amount of latency, even though the reranker scores all the chunks in parallel. There is an inherent trade-off between reranking more chunks for better performance vs. reranking fewer for lower latency and cost. We recommend experimenting with different settings on your specific use case to find the right balance.
重新排序的一个重要考虑因素是其对延迟和成本的影响,尤其是在重新排序大量片段时。由于重新排序在运行时添加了一个额外的步骤,因此它不可避免地会增加少量延迟,即使重新排序器并行对所有片段进行评分。在为了获得更好的性能而重新排序更多片段与为了降低延迟和成本而重新排序更少片段之间存在固有的权衡。我们建议您针对您的具体用例尝试不同的设置,以找到合适的平衡点
Conclusion结论
我们运行了大量的测试,比较了上述所有技术的不同组合(嵌入模型、BM25 的使用、上下文检索的使用、重排序器的使用以及检索到的 top-K 结果的总数),涵盖了各种不同的数据集类型。以下是我们的发现总结:
-
Embeddings+BM25 is better than embeddings on their own;
嵌入+BM25优于单独使用嵌入; -
Voyage and Gemini have the best embeddings of the ones we tested;
我们测试过的模型中,Voyage和Gemini的嵌入效果最好; -
Passing the top-20 chunks to the model is more effective than just the top-10 or top-5;
将前20个片段传递给模型比只传递前10个或前5个更有效; -
Adding context to chunks improves retrieval accuracy a lot;
为片段添加上下文信息可大幅提高检索准确率;
Reranking is better than no reranking; -
重新排序总比不重新排序好;
All these benefits stack: to maximize performance improvements, we can combine contextual embeddings (from Voyage or Gemini) with contextual BM25, plus a reranking step, and adding the 20 chunks to the prompt.
所有这些优势叠加:为了最大限度地提高性能,我们可以将上下文嵌入(来自 Voyage 或 Gemini)与上下文 BM25 相结合,再加上一个重新排序步骤,并将 20 个chunks添加到提示中。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











