 Stacking集成学习详解
Stacking集成学习详解





 本文详细介绍了Stacking集成学习的基本原理及其实现步骤。首先通过初级学习生成次级学习所需的训练集和测试集,然后利用这些数据进行次级学习与预测。文章还探讨了如何通过基模型的预测结果生成新的训练数据,并强调了使用交叉验证的重要性。
本文详细介绍了Stacking集成学习的基本原理及其实现步骤。首先通过初级学习生成次级学习所需的训练集和测试集,然后利用这些数据进行次级学习与预测。文章还探讨了如何通过基模型的预测结果生成新的训练数据,并强调了使用交叉验证的重要性。
第一步,进行初级学习,生成次级学习器的训练集(X_train_new,y_train)和测试集(X_test_new,y_test)
(篇幅所限,我们在此假设每个基模型都是经过参数调优处理的优良模型,具体如何进行参数优化请参见相关文献)
如上所述,次级学习器的训练集的X_train_new,测试集X_test_new是初级学习的预测结果组合生成,而y_train与y_test(其实在stacking中没什么用)并没有变化(搞清楚这一点很重要,很多文章中没有说明这一点)。我们来看一下X_train_new和X_test_new的生成过程。下图是非常著名的一张图。
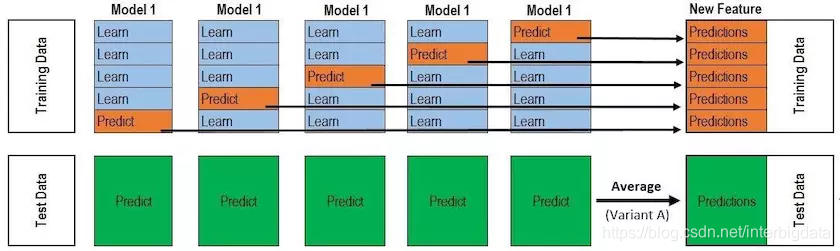
该图描绘了一个基模型是如何贡献X_train_new和X_test_new数据的(要注意,它只贡献了一部分,而非全部)。
为了保证样本数据的多样性,从而提高模型的泛化能力,stacking提倡每个基模型采用KFold交叉验证的方式产生预测值。如上图,Model1经过k轮训练后,每次在验证集上的预测结果汇集成了原始X_train上的预测结果y_pred_1;在k轮训练的同时,Model1也在原始测试集X_test上生成了k个预测结果,这些结果通过均值操作融合成一个测试集上的输出y_test_1。为什么y_pred_1是汇集而成的而y_test_1是均值而成的?(大家从上图参悟吧,重点看箭头)。
好了,我们对其余的基模型model2、model3、...、modeln采取上同述同样的操作,就会得到(y_pred_2、y_test_2)、(y_pred_3、y_test_3)、...、(y_pred_n、y_test_n)。
接下来最关键的一步到了,我们要组合上述结果,生成次级学习的训练集和测试集了。看下图,生成过程不再废话

第二步,进行次级学习与预测
次级学习是在数据集(X_train_new ,y_train)进行的,此时你就可以忘记第一步操作了。这一步的操作如同简单的机器学习操作,对于机器学习算法的选择,你可以从以上基模型中先一个性能最优的,也可以选一个不在基学习器集合中的算法/模型。
总之,我们在次级机器学习训练完毕后,就可以将X_test_new代入模型,得到预测结果了。
实验证明,stacking集成学习算法确实效果要好很多,笔者进行了有限次实验,结果对比如下:(橙色为单一boosting模型)
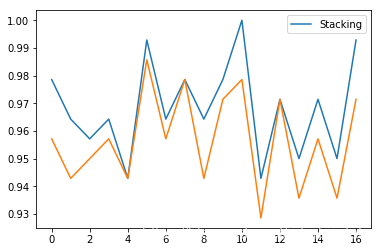
笔者还提供了完整的代码案例,详见第三部分


















 2799
2799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











