







 本文深入剖析Nginx的Hash表结构与实现原理,包括ngx_hash_elt_t、ngx_hash_t及ngx_hash_init_t的数据结构定义,展示了Nginx如何在初始化阶段优化内存分配与查询效率。
本文深入剖析Nginx的Hash表结构与实现原理,包括ngx_hash_elt_t、ngx_hash_t及ngx_hash_init_t的数据结构定义,展示了Nginx如何在初始化阶段优化内存分配与查询效率。
目录
Nginx的hash表结构和我们之前阅读memcached的时候看到的会有很大的差别。笔者在阅读Nginx的hash模块的时候,阅读了好几天,比较不容易理解,但是Nginx的hash模块包含了对内存利用最大化、CPU利用最大化的很多设计细节,非常值得推荐和学习。
Nginx的hash表结构主要几个特点:
- 静态只读。当初始化生成hash表结构后,是不能动态修改这个hash表结构的内容。
- 将内存利用最大化。Nginx的hash表,将内存利用率发挥到了极致,并且很多设计上面都是可以供我们学习和参考的。
- 查询速度快。Nginx的hash表做了内存对齐等优化。
- 主要解析配置数据。
一、数据结构定义
1. ngx_hash_elt_t hash表的元素结构
/**
* 存储hash的元素
*/
typedef struct {
void *value; /* 指向value的指针 */
u_short len; /* key的长度 */
u_char name[1]; /* 指向key的第一个地址,key长度为变长(设计上的亮点)*/
} ngx_hash_elt_t;2. ngx_hash_t hash表结构
/**
* Hash的桶
*/
typedef struct {
ngx_hash_elt_t **buckets; /* hash表的桶指针地址值 */
ngx_uint_t size; /* hash表的桶的个数*/
} ngx_hash_t;3. ngx_hash_init_t hash表初始化结构
/**
* hash表主体结构
*/
typedef struct {
ngx_hash_t *hash; /* 指向hash数组结构 */
ngx_hash_key_pt key; /* 计算key散列的方法 */
ngx_uint_t max_size; /* 最大多少个 */
ngx_uint_t bucket_size; /* 桶的存储空间大小 */
char *name; /* hash表名称 */
ngx_pool_t *pool; /* 内存池 */
ngx_pool_t *temp_pool; /* 临时内存池*/
} ngx_hash_init_t;二、数据结构图
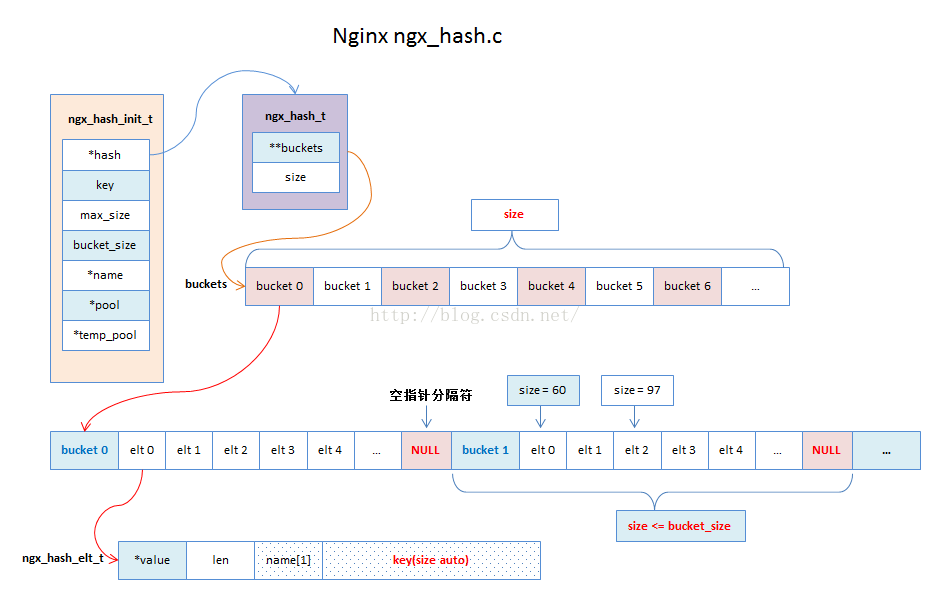
说明:
- Nginx的hash表主要存放在ngx_hash_t数据结构上。ngx_hash_t主要存放桶的指针值和桶的个数。
- Nginx的hash表中桶的个数会在初始化的时候进行“探测”,会探测出合适的痛的个数。
- Nginx的hash表在初始化的时候就决定了hash表的桶的个数以及元素个数和大小,所以所有元素都会被分配到一个大的连续的内存块上。
- 每个bucket的长度会根据元素个数的实际长度决定,并且每个bucket之间通过NULL指针进行分割。
- 每个桶都保存了桶的第一个元素ngx_hash_elt_t的指针值。
- NULL指针会在查找元素的时候用到,具体看下面的源码阅读。
- ngx_hash_elt_t存储每个元素的数据结构,并且key的长度是非定长的。
三、具体函数实现
1. 查找一个元素 ngx_hash_find
/**
* 从hash表中读取一个元素
*/
void *
ngx_hash_find(ngx_hash_t *hash, ngx_uint_t key, u_char *name, size_t len)
{
ngx_uint_t i;
ngx_hash_elt_t *elt;
#if 0
ngx_log_error(NGX_LOG_ALERT, ngx_cycle->log, 0, "hf:\"%*s\"", len, name);
#endif
/* 获取对应的桶 */
elt = hash->buckets[key % hash->size];
if (elt == NULL) {
return NULL;
}
/* 在桶的链表上,查找具体的值;elt元素最后一个elt->value==NULL */
while (elt->value) {
if (len != (size_t) elt->len) {
goto next;
}
for (i = 0; i < len; i++) {
if (name[i] != elt->name[i]) {
goto next;
}
}
return elt->value;
next:
/* 因为在内存池上申请内存,并且是自己处理整块内存,为了CPU读取速度更快,进行了内存对齐 */
elt = (ngx_hash_elt_t *) ngx_align_ptr(&elt->name[0] + elt->len,
sizeof(void *));
continue;
}
return NULL;
}2. 创建一个hash表 ngx_hash_init
获取元素大小的宏定义。
/**
* 获取元素的大小
* 元素大小主要是ngx_hash_elt_t结构,包括:
* 1. name的长度 (name)->key.len
* 2. len的长度 其中的"+2"是要加上该结构中len字段(u_short类型)的大小
* 3. value指针的长度 "sizeof(void *)"相当于 value的长度
*/
#define NGX_HASH_ELT_SIZE(name) \
(sizeof(void *) + ngx_align((name)->key.len + 2, sizeof(void *)))ngx_hash_init初始化一个hash表
- Nginx的hash表是只读的,所以在初始化的时候就会生成固定的hash表。
- 初始化过程中,先会根据实际key的大小来进行“探测”,得出一个合适的桶的个数。
- 然后根据元素的大小,来确定每个桶具体的大小,并且分配完整的元素大内存块。
- 然后将元素切割成ngx_hash_elt_t的结构,装入每一个bucket桶上。
- 每个bucket的结尾都会有一个NULL空指针作为标识符号,该标识符号会强制换成ngx_hash_elt_t结构,并且设置value=NULL,在查询的时候用于判断桶的结尾部分。
/**
* 初始化一个hash表
*/
ngx_int_t ngx_hash_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names,
ngx_uint_t nelts)
{
u_char *elts;
size_t len;
u_short *test;
ngx_uint_t i, n, key, size, start, bucket_size;
ngx_hash_elt_t *elt, **buckets;
/**
* 先检查每个元素是否会超过bucket_size的限制
* 如果超过限制,则说明需要重新处理
* hash表的每一个bucket桶中的元素elt都是被分配到一块完整的内存块上的,
* 每个bucket的内存块结尾会有一个void *的空指针作为表示符号用于分隔bucket
*/
for (n = 0; n < nelts; n++) {
if (hinit->bucket_size
< NGX_HASH_ELT_SIZE(&names[n]) + sizeof(void *)) {
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build the %s, you should "
"increase %s_bucket_size: %i", hinit->name,
hinit->name, hinit->bucket_size);
return NGX_ERROR;
}
}
/*
* test是用来做探测用的,探测的目标是在当前bucket的数量下,冲突发生的是否频繁。
* 过于频繁则需要调整桶的个数。
* 检查是否频繁的标准是:判断元素总长度和bucket桶的容量bucket_size做比较
*/
test = ngx_alloc(hinit->max_size * sizeof(u_short), hinit->pool->log);
if (test == NULL) {
return NGX_ERROR;
}
/**
* 每个桶的元素实际所能容纳的空间大小
* 需要减去尾部的NULL指针结尾符号
*/
bucket_size = hinit->bucket_size - sizeof(void *);
/**
* 通过一定的小算法,计算得到从哪个桶开始test(探测)
*/
start = nelts / (bucket_size / (2 * sizeof(void *)));
start = start ? start : 1;
if (hinit->max_size > 10000 && nelts && hinit->max_size / nelts < 100) {
start = hinit->max_size - 1000;
}
/**
* 这边就是真正的探测逻辑
* 探测会遍历所有的元素,并且计算落到同一个bucket上元素长度的总和和bucket_size比较
* 如果超过了bucket_size,则说明需要调整
* 最终会探测出比较合适的桶的个数 :size
*/
for (size = start; size < hinit->max_size; size++) {
ngx_memzero(test, size * sizeof(u_short));
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
key = names[n].key_hash % size;
test[key] = (u_short)(test[key] + NGX_HASH_ELT_SIZE(&names[n]));
#if 0
ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0,
"%ui: %ui %ui \"%V\"",
size, key, test[key], &names[n].key);
#endif
/* 比较bucket_size和落到该bucket上的元素长度总和*/
if (test[key] > (u_short) bucket_size) {
goto next;
}
}
goto found;
next:
continue;
}
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build the %s, you should increase "
"either %s_max_size: %i or %s_bucket_size: %i", hinit->name,
hinit->name, hinit->max_size, hinit->name, hinit->bucket_size);
ngx_free(test);
return NGX_ERROR;
/**
* 探测成功,则size为bucket桶的个数
*/
found:
/**
* 为了确定bucket的实际长度,初始化每个桶的长度计数器,初始值为一个NULL空指针长度
* 前面说过,每个bucket的内存块之间,使用一个NULL空指针进行分割,所以长度需要加上去
*/
for (i = 0; i < size; i++) {
test[i] = sizeof(void *);
}
/**
* 通过遍历,计算每个桶的大小。并且将每个桶的大小存储在test[n]数组上
*/
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
key = names[n].key_hash % size;
test[key] = (u_short)(test[key] + NGX_HASH_ELT_SIZE(&names[n]));
}
len = 0;
/**
* 获取所有元素需要分配的内存的总大小
* len = 总的内存大小,所有的桶都会放在一块内存上,并且做了手工内存对齐
*/
for (i = 0; i < size; i++) {
if (test[i] == sizeof(void *)) {
continue;
}
/* 总内存大小,需要通过内存对齐函数 */
test[i] = (u_short)(ngx_align(test[i], ngx_cacheline_size));
len += test[i];
}
/**
* 分配一块内存空间,存储:ngx_hash_t *hash和ngx_hash_elt_t *
* ngx_hash_elt_t用于存储桶。指针指向元素地址
*/
if (hinit->hash == NULL) {
hinit->hash = ngx_pcalloc(hinit->pool,
sizeof(ngx_hash_wildcard_t) + size * sizeof(ngx_hash_elt_t *));
if (hinit->hash == NULL) {
ngx_free(test);
return NGX_ERROR;
}
buckets = (ngx_hash_elt_t **) ((u_char *) hinit->hash
+ sizeof(ngx_hash_wildcard_t));
} else {
buckets = ngx_pcalloc(hinit->pool, size * sizeof(ngx_hash_elt_t *));
if (buckets == NULL) {
ngx_free(test);
return NGX_ERROR;
}
}
/**
* 分配一个桶,用于存储所有元素数据
*/
elts = ngx_palloc(hinit->pool, len + ngx_cacheline_size);
if (elts == NULL) {
ngx_free(test);
return NGX_ERROR;
}
elts = ngx_align_ptr(elts, ngx_cacheline_size); //内存对齐
/**
* 将elts元素的内存,分割到buckets桶上
*/
for (i = 0; i < size; i++) {
if (test[i] == sizeof(void *)) {
continue;
}
buckets[i] = (ngx_hash_elt_t *) elts;
elts += test[i];
}
/**
* 将test清空,利用test于元素填充计数器
*/
for (i = 0; i < size; i++) {
test[i] = 0;
}
/**
* 往bucket的元素位上填充数据
*/
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
/* 计算在哪个桶上 */
key = names[n].key_hash % size;
elt = (ngx_hash_elt_t *) ((u_char *) buckets[key] + test[key]);
elt->value = names[n].value;
elt->len = (u_short) names[n].key.len;
/* 拷贝key数据,并且小写 */
ngx_strlow(elt->name, names[n].key.data, names[n].key.len);
/* test计数器计算新元素需要存放的位置 */
test[key] = (u_short)(test[key] + NGX_HASH_ELT_SIZE(&names[n]));
}
/**
* 设置bucket桶上最后一个元素设置为value为NULL
*/
for (i = 0; i < size; i++) {
if (buckets[i] == NULL) {
continue;
}
/**
* 这边的设计 Nice!!!
* test[i] 其实是bucket的元素块的结束位置
* 由于前面bucket的处理中多留出了一个指针的空间,而此时的test[i]是bucket中实际数据的共长度,
* 所以bucket[i] + test[i]正好指向了末尾null指针所在的位置。处理的时候,把它当成一个ngx_hash_elt_t结构看,
* 在该结构中的第一个元素,正好是一个void指针,我们只处理它,别的都不去碰,所以没有越界的问题。
*/
elt = (ngx_hash_elt_t *) ((u_char *) buckets[i] + test[i]);
elt->value = NULL;
}
ngx_free(test);
hinit->hash->buckets = buckets;
hinit->hash->size = size;
return NGX_OK;
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









