









准备工作
我们首先需要安装谷歌驱动:
根据自己浏览器版本去选择对应的驱动安装就可以了。
访问如下链接下载浏览器驱动即可:
安装selinum
pip install seleniumselinum介绍
Selenium 是一个用于 Web 应用程序测试的工具,它提供了一组 API,可以与浏览器交互,模拟用户在浏览器中的操作行为。虽然最初设计用于自动化测试,但它也被广泛应用于 Web 数据采集、网页截图、模拟用户登录等场景。
以下是 Selenium 的一些主要特点和用途:
1.浏览器自动化:Selenium 可以模拟用户在各种主流浏览器(如 Chrome、Firefox、Safari)中的操作,包括点击、填写表单、下拉滚动、提交等操作。
2.跨平台支持:Selenium 支持 Windows、Mac 和 Linux 等多个操作系统,并且与各种编程语言(如 Python、Java、JavaScript)兼容。
3.灵活性:Selenium 提供了多种操作浏览器的方法,包括原生的 WebDriver API、Selenium IDE(用于录制和回放操作)、Selenium Grid(用于并行测试)等。
4.网页数据采集:除了用于测试,Selenium 也可以用于从网页中提取数据。通过模拟用户操作,可以访问动态加载的内容并提取信息。
5.自动化任务:Selenium 可以用于自动化执行重复的任务,比如定期检查网站内容、自动填写表单、自动化提交等。
虽然 Selenium 是一个强大的工具,但也有一些局限性。比如它需要启动一个真实的浏览器实例来执行操作,因此可能会消耗较多的系统资源和时间。另外,对于一些复杂的网站,由于页面结构的变化或安全性限制,可能会导致测试脚本的稳定性和可维护性降低。
总的来说,Selenium 是一个非常有用的工具,可以帮助开发人员和测试人员自动化浏览器操作,并用于各种 Web 应用程序测试和数据采集的场景。
项目背景
本次抓取boss直聘数据用于后续的数据分析,将针对不同岗位挖掘出他们其中的价值 ,基于机器学习算法对招聘数据进行分析,深度剖析市场招聘现状。
编码工作
导入相关依赖包
import time
from selenium.webdriver import Chrome, ActionChains
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import logging
from crawler.BossCsv import Csv
定义类并初始化
class BossCrawler:
def __init__(self):
service = Service(executable_path='./chromedriver.exe')
self.driver = Chrome(service=service)
self.csv_row = Csv()
self.driver.set_page_load_timeout(time_to_wait=5)
编写登录函数,访问登录url,用户登录之后手动在控制台输入y
def login(self):
login_url = 'https://www.zhipin.com/web/user/?ka=header-login'
self.driver.get(login_url)
print('请手动完成登录!')
is_login = input('是否登录(y/n)').lower()
print(is_login)
if is_login == 'y':
return True
else:
return False
爬取全国地区所有招聘数据
本次使用xpath表达式进行元素定位的,打开F12开发者工具即可进行调试xpath:
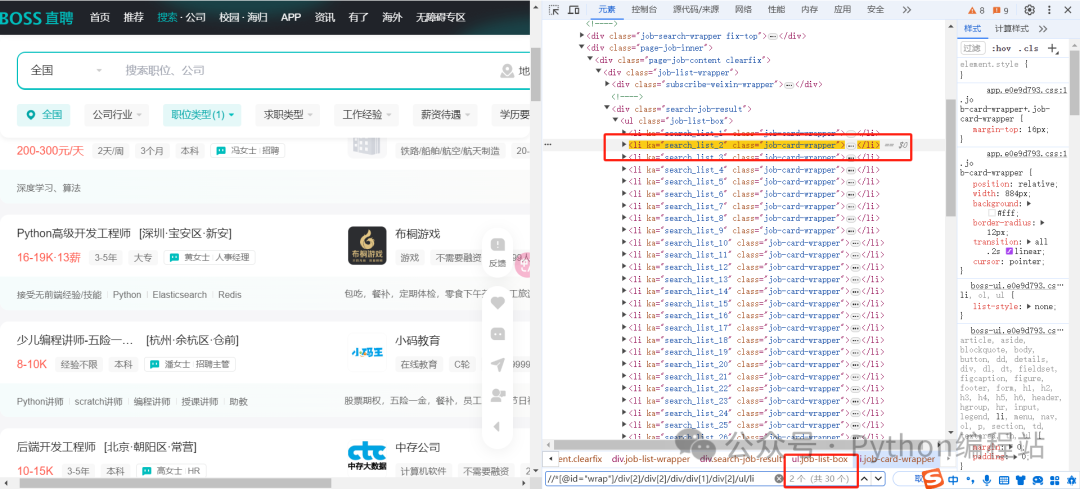
本次采集的岗位有:运维,测试,将爬取的数据字段有:
['岗位名称', '工作地点', '公司名称', '所属行业', '融资情况', '人员规模', '岗位薪资', '工作年限' '学历要求', '岗位标签', '岗位福利', '岗位描述']
def getPlaces(self):
keywords = ['运维', '测试']
pages = range(29, 30)
for keyword in keywords:
for page in pages:
print(f'-------------{keyword} - 第{page}页--------------------')
job_url = f'https://www.zhipin.com/web/geek/job?query={keyword}&city=100010000&page={page}'
self.driver.get(job_url)
time.sleep(3)
job_lis = self.driver.find_elements(value='//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/ul/li',
by=By.XPATH)
# print(job_lis)
for item in job_lis:
try:
# 岗位名称/div[1]/a/div[1]/span[1]
job = item.find_element(value='./div[1]/a/div[1]/span[1]', by=By.XPATH) # .text
job_name = job.text if job else ''
# 工作地点
job_area = item.find_element(value='./div[1]/a/div[1]/span[2]/span', by=By.XPATH)
job_area = job_area.text if job_area else ''
# 公司
job_company = item.find_element(value='./div[1]/div/div[2]/h3/a', by=By.XPATH)
job_company = job_company.text if job_company else ''
# 公司所属行业
job_ind_com = item.find_element(value='./div[1]/div/div[2]/ul/li[1]', by=By.XPATH)
job_ind_com = job_ind_com.text if job_ind_com else ''
# 是否融资
is_sit = item.find_elements(value='./div[1]/div/div[2]/ul/li', by=By.XPATH)
if len(is_sit) > 2:
# 企业融资情况
job_situation = item.find_element(value='./div[1]/div/div[2]/ul/li[2]', by=By.XPATH)
job_situation = job_situation.text if job_situation else ''
# 公司人员规模
job_per_size = item.find_element(value='./div[1]/div/div[2]/ul/li[3]', by=By.XPATH)
job_per_size = job_per_size.text if job_per_size else ''
else:
# 企业融资情况
job_situation = ''
# 公司人员规模
job_per_size = item.find_element(value='./div[1]/div/div[2]/ul/li[2]', by=By.XPATH)
job_per_size = job_per_size.text if job_per_size else ''
# 岗位薪资
job_salary = item.find_element(value='./div[1]/a/div[2]/span', by=By.XPATH)
job_salary = job_salary.text if job_salary else ''
# 学历要求
job_edu = item.find_element(value='./div[1]/a/div[2]/ul/li[1]', by=By.XPATH)
job_edu = job_edu.text if job_edu else ''
# 工作经验
job_exp = item.find_element(value='./div[1]/a/div[2]/ul/li[2]', by=By.XPATH)
job_exp = job_exp.text if job_exp else ''
# 岗位标签
job_tag = item.find_element(value='./div[2]/ul', by=By.XPATH)
job_tag = job_tag.text if job_tag else ''
# 岗位福利
job_bonus = item.find_element(value='./div[2]/div', by=By.XPATH)
job_bonus = job_bonus.text if job_bonus else ''
# actions = ActionChains(self.driver)
#
# # 将鼠标移动到要悬停的标签上
# actions.move_to_element(job).perform()
# 岗位描述
# job_detail = item.find_element(value='./div[1]/a/div[3]/div[2]', by=By.XPATH).text
# 点击 job 对象
job.click()
# 获取当前窗口句柄
main_window = self.driver.current_window_handle
# 等待新标签页打开
time.sleep(2)
# 切换到新标签页
for handle in self.driver.window_handles:
if handle != main_window:
self.driver.switch_to.window(handle)
break
# 在新标签页执行想要的操作
window_title = self.driver.title
# print(window_title)
# 岗位描述
job_desc = self.driver.find_element(value='//*[@id="main"]/div[3]/div/div[2]/div[1]/div[2]',
by=By.XPATH).text
job_desc = job_desc if job_desc else ''
# print(job_desc)
# 切换回原来的窗口
self.driver.close()
# 切换回原来的句柄
self.driver.switch_to.window(main_window)
row = [job_name, job_area, job_company, job_ind_com, job_situation, job_per_size, job_salary,
job_edu,
job_exp, job_tag, job_bonus, job_desc]
self.csv_row.insert(row)
print(row)
except Exception as e:
print(e)
logging.error(e)
input('enter')
self.csv_row.close()关注公众号获取更多技术文章、源码,同时可以结识更多志同道合的大佬!


















 1612
1612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









