




一、算法思想
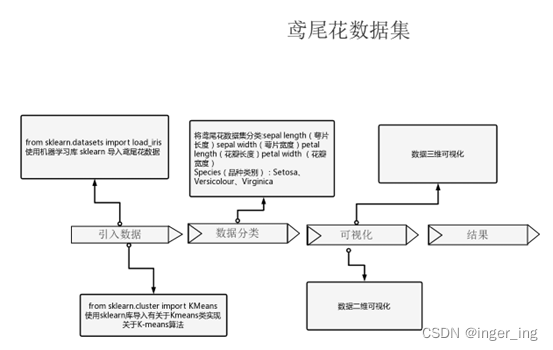
鸢尾花数据集:共收集了三类鸢尾花,即Setosa鸢尾花Versicolour鸢尾花和Virginica鸢尾花,每一类鸢尾花收集了50条样本记录,共计150条。数据集包括4个属性,四个属性的单位都是cm,属于数值变量,四个属性均不存在缺失值的情况,字段如下:sepal length(萼片长度)、sepal width(萼片宽度)、petal length(花瓣长度)、petal width (花瓣宽度)。
K-means算法:根据样本之间的距离或者说是相似性(亲疏性),把越相似、差异越小的样本聚成一(簇),最后形成多个簇,使同一个簇内部的样本想似度高,不同簇之间差异性高。
二、流程图
三、实验结果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3099
3099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









