




背景
在 Easysearch 的各种使用场景中,高写入吞吐量的场景占了很大一部分,由此也带来了一些使用上的问题,很多用户由于使用经验不足,对集群的写入压测进行的不够充分,不能很好的规划集群的写入量。
导致经常发生以下问题:
- 写入吞吐量过大对内存影响巨大,引发节点 OOM,节点掉线问题。
- 对 CPU 和内存的占用严重影响了其他的查询业务的响应。
- 以及磁盘 IO 负载增加,挤占集群的网络带宽等问题。
之前就有某金融保险类客户遇到了因业务端写入量突然猛增导致数据节点不停的 Full GC,进而掉入了不停的掉线,上线,又掉线的恶性循环中。当时只能建议用户增加一个类似“挡板”的服务,在数据进入到集群之前进行拦截,对客户端写入进行干预限流:
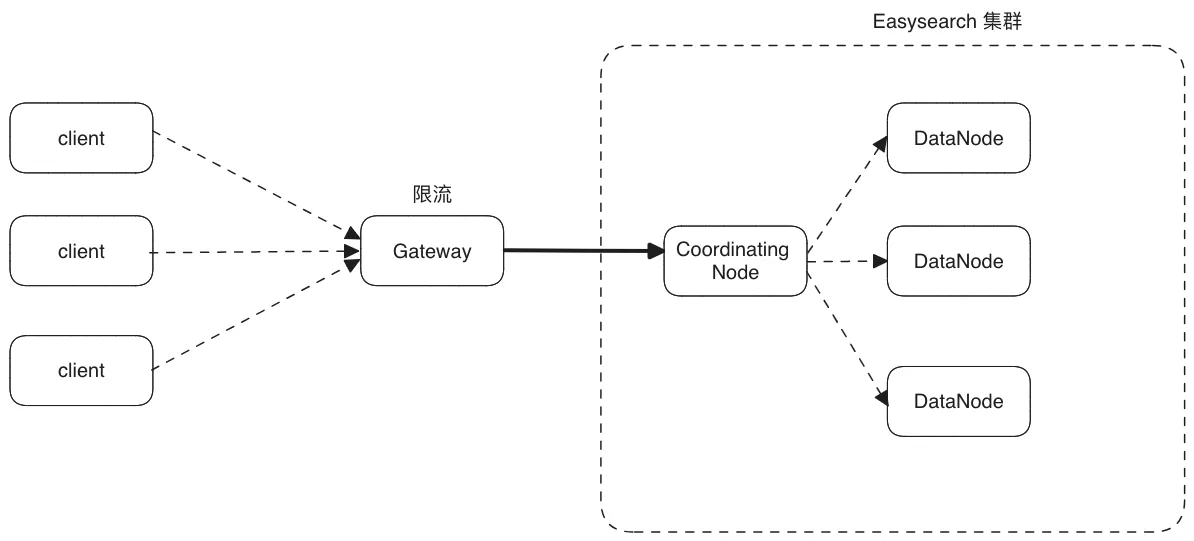
这样做虽然有效,但是也增加了整个系统的部署复杂性,提高了运维成本。
根据客户的实际场景,Easysearch 从 1.8.0 版本开始引入了节点和 Shard 级别的限流功能,不用依赖第三方就可以限制写入压力,并在 1.8.2 版本增加了索引级别的写入限流。
注意:所有写入限流都是针对各数据节点的 Primary Shard 写入进行限流的,算上副本的话吞吐量要乘以 2。
限流示意图:
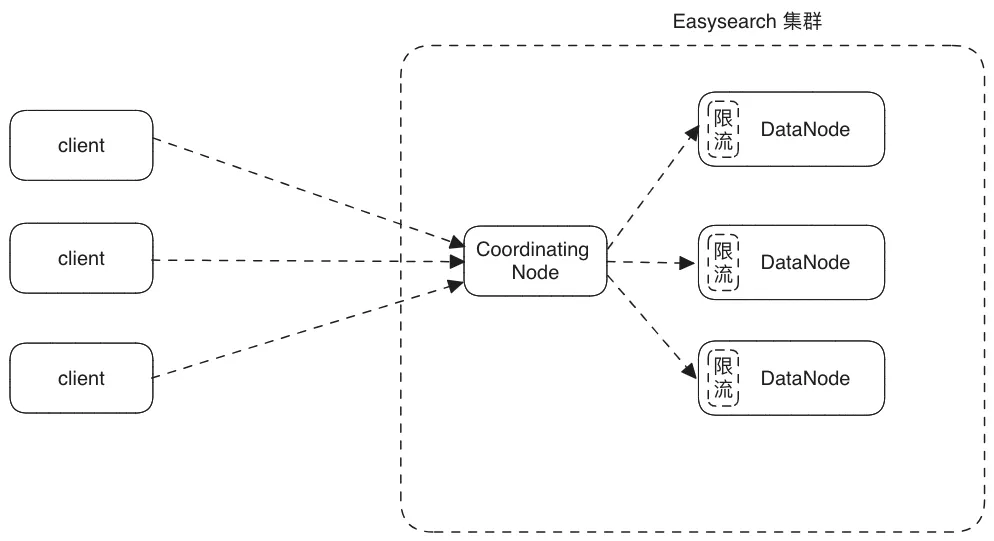
下面是限流前后相同数据节点的吞吐量和 CPU 对比:
测试环境:
ip name http port version role master
10.0.0.3 node-3 10.0.0.3:9209 9303 1.8.0 di 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1627
1627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









