




 这篇博客主要围绕Java内存管理展开,讨论了在Java 7中FullGC后Heap空间的字符保留情况。同时,博主列举了一系列关于垃圾收集器、面向对象编程优点、线程安全、矩阵存储优化、数组操作以及线性表存储结构的问题,旨在帮助读者巩固这些关键概念和技巧。
这篇博客主要围绕Java内存管理展开,讨论了在Java 7中FullGC后Heap空间的字符保留情况。同时,博主列举了一系列关于垃圾收集器、面向对象编程优点、线程安全、矩阵存储优化、数组操作以及线性表存储结构的问题,旨在帮助读者巩固这些关键概念和技巧。
01.
static String str0="0123456789";
static String str1="0123456789";
String str2=str1.substring(5);
String str3=new String(str2);
String str4=new String(str3.toCharArray());
str0=null;
假定str0,…,str4后序代码都是只读引用。
Java 7中,以上述代码为基础,在发生过一次FullGC后,上述代码在Heap空间(不包括PermGen)保留的字符数为()
解析:
java中内存区域分为4类:
栈内存空间,存放引用的堆内存空间的地址
堆内存空间,存放new出来的对象
全局数据区,保存static类型属性和全局变量
全局代码区,保存所有方法的定义
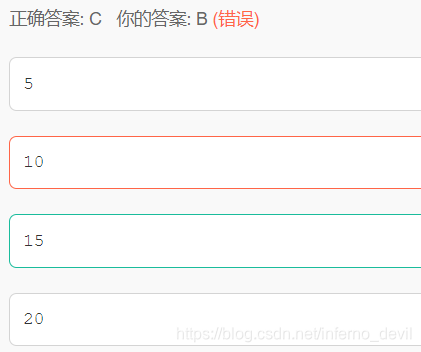
所有str0和str1不会在堆区,str2和str3和str4分别在堆内存开辟空间,所以是15
垃圾回收主要针对的是堆区的回收,因为栈区的内存是随着线程而释放的。
堆区分为三个区:年轻代(Young Generation)、年老代(Old Generation)、永久代(Permanent Generation,也就是方法区)。
年轻代:对象被创建时(new)的对象通常被放在Young(除了一些占据内存比较大的对
象),经过一定的Minor GC(针对年轻代的内存回收)还活着的对象会被移动到年老代(一
些具体的移动细节省略)。
年老代:就是上述年轻代移动过来的和一些比较大的对象。Minor GC(FullGC)是针对年老代的回收
永久代:存储的是final常量,static变量,常量池。
str3,str4都是直接new的对象,而substring的源代码其实也是new一个string对象返回。
经过fullgc之后,年老区的内存回收,则年轻区的占了15个,不算PermGen。所以答案选C
02.下列哪项不属于jdk1.6垃圾收集器?
解析:
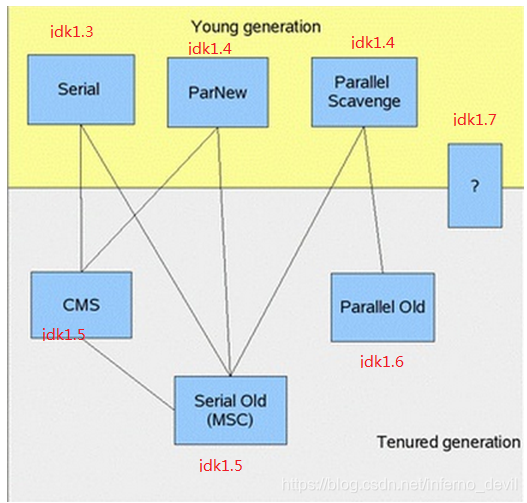
1.Serial收集器
单线程收集器,收集时会暂停所有工作线程(我们将这件事情称之为Stop The World,
下称STW),使用复制收集算法,虚拟机运行在Client模式时的默认新生代收集器。
2.ParNew收集器
ParNew 收集器就是Serial的多线程版本,除了使用多条收集线程外,其余行为包括算法、
STW、对象分配规则、回收策略等都与Serial收集器一摸一样。对应的这种收集器是虚拟
机运行在Server模式的默认新生代收集器,在单CPU的环境中,ParNew收集器并不会比
Serial收集器有更好的效果。
3.Parallel Scavenge收集器
Parallel Scavenge收集器(下称PS收集器)也是一个多线程收集器,也是使用复制
算法,但它的对象分配规则与回收策略都与ParNew收集器有所不同,它是 以吞吐量最大
化(即GC时间占总运行时间最小)为目标的收集器实现,它允许较长时间的STW换取总吞吐量最大化。
4.Serial Old收集器
Serial Old是单线程收集器,使用标记-整理算法,是老年代的收集器,上面三种都是
使用在新生代收集器。
5.Parallel Old收集器
老年代版本吞吐量优先收集器,使用多线程和标记-整理算法,JVM 1.6提供,在此之前,
新生代使用了PS收集器的话,老年代除Serial Old外别无选择,因为PS无法与CMS收集器配合工作。
6.CMS(Concurrent Mark Sweep)收集器
CMS 是一种以最短停顿时间为目标的收集器,使用CMS并不能达到GC效率最高(总体GC
时间最小),但它能尽可能降低GC时服务的停顿时间,这一点对于实时或者高交互性应用
(譬如证券交易)来说至关重要,这类应用对于长时间STW一般是不可容忍的。CMS收集器
使用的是标记-清除算法,也就是说它在运行期间会 产生空间碎片,所以虚拟机提供了参
数开启CMS收集结束后再进行一次内存压缩。
03.面向对象程序设计方法的优点包含:

04.以下各类中哪几个是线程安全的?( )

解析:
集合框架:
Collection:
List:(有序,可重)
ArrayList: 有序,可重复;底层使用数组,查询快,增删慢;线程不安全,效率高;容量不足时扩增为当前容量*1.5 + 1;
Vector: 有序,可重复;底层使用数组,查询快,增删慢;线程安全,效率低;容量不足时扩增为当前容量*2;
LinkedList:有序,可重复;底层使用双向循环链表,查询慢,增删快;线程不安全,效率高;不存容量不足的情况;
Set
HashSet: 底层采用HashMap实现,故性质和HashMap类似
TreeSet: 底层采用TreeMap实现
LinkedHashSet:底层采用LinkedHashMap实现
Map
HashMap: 无序,不可重复(但可以为null),底层采用数组和链表结合的数据结构;线程不安全,效率高;容量一直为2的n次方,即每次都是扩充为原来的2倍
Hashtable: 无序,不可重复(不可以为null),底层采用数组和链表结合的数据结构;线程安全,效率高;容量一直为2的n次方,即每次都是扩充为原来的2倍
TreeMap: 无序,不可重复,底层采用二叉树实现;线程不安全
LinkedHashMap:底层采用链表和哈希表实现,有序,不可重复
故线程安全的有Vector,Hashtable,Stack因继承Vector也是线程安全的。
05.下列说法错误的有( )

解析:
java不允许单独的方法,过程或函数存在,需要隶属于某一类中。——AB错
java语言中的方法属于对象的成员,而不是类的成员。不过,其中静态方法属于类的成员。——C错
匿名函数的没有名字 ——D错
06.在一般情况下,采用压缩存储后,对称矩阵是所有特殊矩阵中存储空间节约最多的,这样的说法正确吗?

解析:
对称矩阵关于主对角线对称,因此只需存储下三角部分(包括主对角线)即可。这样原来
需要存储n×n个存储单元,现在只需要n×(n+1)/2个存储单元,节约了大约一半的存储单
元。当n较大时,这是比较可观的一部分存储单元。
稀疏矩阵,0元素远多于非0元素且非0元素分布没有规律。比如一个矩阵只有零散的两个
1,其他元素都是0,那压缩存储的时候只需要记录这两个非0元素的位置(行,列)还有
值(1)就可以了,其他元素都是0。
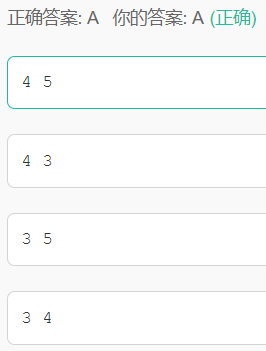
07.int A[2][3]={1,2,3,4,5,6}; 则A[1][0]和((A+1)+1)的值分别是()**
解析:
数组A一共2行3列,第0行为123,第1行为456
A[1][0]为第1行第0列数字4
*(A+1)指向数组第1行第0个元素
*(A+1)+1指向数组第1行第1个元素
再取*则为第1行第1个元素的值5
因此为4,5
08.对于一个线性表既要求能够进行较快速地的插入和删除,又要求存储结构能反映数据之间的逻辑关系,则应该用()
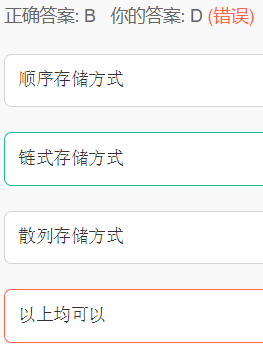
解析:
要求能够进行较快速地的插入和删除,则可选范围为链式存储和散列存储,而再加上要求
存储结构能反映数据之间的逻辑关系,则只能选择链式存储了,因为散列技术的记录数据
之间不存在什么逻辑关系,它只和关键字有关联。
散列存储方式即为哈希hash存储。
09.设有一个n行n列的对称矩阵A,将其下三角部分按行存放在一个一维数组B中,A[0][0]存放于B[0]中,那么第i行的对角元素A[i][i]存放于B中()处
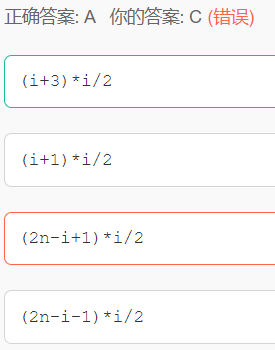
解析:
上三角时选C。
如果是上三角,A[i][i]作为矩阵中第i+1行第i+1列元素,其实是第i+1行上三角的
第1个元素,前面i行已经排满了,前面是n+(n-1)+...+[n-(i-1)]={n+[n-(i-1)]}*i/2=(2n-i+1)/2,
再加上第i+1行上三角的第一个元素,所以是(2n-i+1)/2+1。但是因为从0开始计坐标,
所以还要减去1,最终是(2n-i+1)/2。
上三角(2n-i+1)*i/2
下三角(i+3)*i/2
10.下面的说法那个正确
#define NUMA 10000000
#define NUMB 1000
int a[NUMA], b[NUMB];
void pa()
{
int i, j;
for(i = 0; i < NUMB; ++i)
for(j = 0; j < NUMA; ++j)
++a[j];
}
void pb()
{
int i, j;
for(i = 0; i < NUMA; ++i)
for(j = 0; j < NUMB; ++j)
++b[j];
}

解析:
从运行上来说应该是大的在里面可能好一点,可以减少跨循环层的次数。但是从内存上来
讲,pb是要1000万个1000连续内存,和一个1000万的,内存申请较为轻松,而pa是要
1000个1000万连续的内存和一个1000的,其中可能没那么多1000万连续的地址,所以
就有不少缺页(访问失败而重新分配地址)导致运行速度下降。
所以当大小循环相差过大时(临界值不明,10万以上吧估计),大循环放外面比较快。


















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









