




 本文介绍了哈希表的概念,通过散列函数将关键字映射到存储位置以加快查找速度。讨论了哈希冲突的现象和处理方法,包括直接寻址法、除留余数法等。同时,讲解了Java中hashCode函数的实现,强调了在自定义类中重写hashCode和equals方法的重要性,以及Java哈希表在处理哈希冲突时从链表到红黑树的转变。
本文介绍了哈希表的概念,通过散列函数将关键字映射到存储位置以加快查找速度。讨论了哈希冲突的现象和处理方法,包括直接寻址法、除留余数法等。同时,讲解了Java中hashCode函数的实现,强调了在自定义类中重写hashCode和equals方法的重要性,以及Java哈希表在处理哈希冲突时从链表到红黑树的转变。
1.01 哈希表
-散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
-给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
基本概念:
- 若关键字为k,则其值存放在f(k)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数,按这个思想建立的表为散列表。
- 对不同的关键字可能得到同一散列地址,即k1≠k2,而f(k1)=f(k2),这种现象称为冲突。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数f(k)和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为散列表,这一映射过程称为散列造表或散列,所得的存储位置称散列地址。
- 若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform Hash function),这就是使关键字经过散列函数得到一个“随机的地址”,从而减少冲突。
哈希函数:
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位。
实际工作中需视不同的情况采用不同的哈希函数,通常考虑的因素有:
· 计算哈希函数所需时间
· 关键字的长度
· 哈希表的大小
· 关键字的分布情况
· 记录的查找频率
1.直接寻址法:
取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a·key + b,
其中a和b为常数(这种散列函数叫做自身函数)。若其中H(key)中已经有值了,就往下
一个找,直到H(key)中没有值了,就放进去。
-
数字分析法:
分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位 数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位 表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突 的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。 -
平方取中法:
当无法确定关键字中哪几位分布较均匀时,可以先求出关键字的平方值,然后按 需要取平方值的中间几位作为哈希地址。这是因为:平方后中间几位和关键字中每 一位都相关,故不同关键字会以较高的概率产生不同的哈希地址。
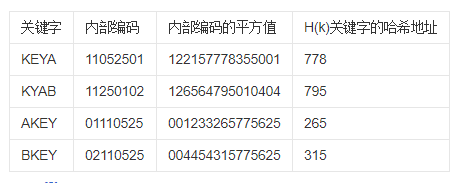
例:
我们把英文字母在字母表中的位置序号作为该英文字母的内部编码。例如K的内部编码为
11,E的内部编码为05,Y的内部编码为25,A的内部编码为01, B的内部编码为02。由此
组成关键字“KEYA”的内部代码为11052501,同理我们可以得到关键字“KYAB”、“AKEY”、
“BKEY”的内部编码。之后对关键字进行平方运算后,取出第7到第9位作为该关键字哈希地址,如下图所示
4. 折叠法:
将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和
(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是
将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回
折叠,然后对齐相加。
-
随机数法:
选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。 -
除留余数法:
取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p,p<=m。不仅可以对关键字直接取模,也可在折叠、平方 取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
哈希函数的设计:
-“键”通过哈希函数得到的“索引”分布越均匀越好
-对于一些特殊领域,有特殊领域的哈希函数设计方式,甚至有专门的论文
-我们只关注一般的哈希函数的设计

Java中的hashCode
1.Object中的hashCode
public native int hashCode();
- 任何子类的hashCode函数都继承自Object。
- 在子类没有重写该函数之时,子类的哈希值由Object的hashCode函数计算。
- 该函数默认将对象的物理内存地址当做哈希值。
2.基本数据类型中的hashCode
重写了Object的hashCode,都是转整型,没有%M。
3.String类中的hashCode
重写了Object的hashCode,没有%M
public int hashCode(){
int h=hash;
if(h==0&&value.length>0){
char val[]=value;
for(int i=0;i<value.length;i++){
h=31*h+val[i]; //字符串转成整型处理的公式
}
hash=h;
}
return h;
}
4.自定义类中的hashCode
public class Student{
int grade;
int cls;
String name;
public Student(int grade, int cls,String name){
super();
this.grade=grade;
this.cls=cls;
this.name=name;
}
public int hashCode(){
int B=31;
int hash=0;
hash=hash*B+grade;
hash=hash*B+cls;
hash=hash*B+name.toLowerCase().hashCode();
return hash;
}
//自动生成的hashCode推荐使用
public int hahsCode(){
final int prime=31;
int result=1;
result=prime*result+cls;
result=prime*result+grade;
result=prime*result+((name==null)?0:name.hashCode());
return result;
}
}
Java中的哈希表
Java中自带的HashSet集合和HashTable映射
hashCode()函数只能计算出元素对应在哈希表中的索引,但是正如上文所述,不同的元素也可能计算出相同的索引。如何处理?

如代码所示,s1和s2都是3年级2班的名称为"xiix"的学生
如果不重写Student类的hashCode函数的话,默认使用Object的,就用对象的地址作为哈希值
所以,s1和s2是两个对象,其地址肯定不同,所以哈希值也不同,则两者都能存入到哈希表中
但是,如果从业务逻辑考虑的话,年级相同,班级相同,姓名也相同的话,表示同一个人
那么此时s1和s2虽然是两个对象,是业务中的同一人,但是也能存在哈希表中,这样子不符合逻辑 如何处理呢?
这就是哈希冲突,目前解决的思路是:
如果哈希值相同,就比较内容,如何比较内容,就需要重写equals方法
内容相同,意味着 两个对象计算的哈希值一样 且内容一样 表示同一人 哈希表不存s2
内容不相同,意味着 两个对象计算的哈希值一样 但内容不一样 表示两个人 哈希表存s2
public boolean equals(Object obj){
if(this==obj) //跟自身比较
return true;
if(obj==null) //判断是否为空
return false;
if(getClass()!=obj.getClass()) //比较是否是相同类型
return false;
Student other=(student) obj;
if(cls!=other.cls)
return false;
if(grade!=other.grade)
return false;
if(name==other.name){
if(other.name!=name)
return false;
}else if(!name.equals(other.name))
return false;
return true;
}
所以,对于Java中自带的哈希表,计算步骤如下
- 先调用对象的hashCode计算哈希值
- 通过哈希值寻表中的位置
- 如果该位置中没有元素,则直接存入
- 如果该位置中已有元素,则调用后者的equals和已存在元素进行比较
a. 内容相同,后者不存如
b. 内容不同,后者存入(链地址法 )
哈希冲突的处理 链地址法(Seperate Chaining)
哈希表的本质就是一个数组,一个位置如果存放多个元素 使用链表挂接的方法 。


这样子的话,相当于数组中每个位置存的是一个查找表,可以是链表也可以是数组,但是这样的话,在该位置查找元素时,时间复杂度为O(n),倒不如存一颗树,红黑树即可。
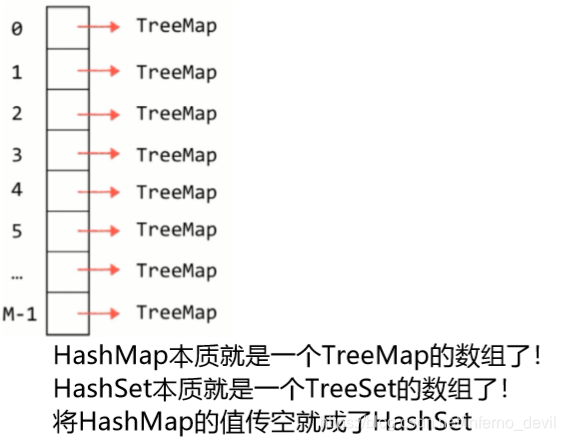
注意:
Java8之前,每一个位置对应一个链表
Java8之后,当哈希冲突达到一定程度,每一个位置从链表转成红黑树

















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









