






背景
在单体应用中,项目直接部署到一台机器上,所有的访问都流向此机器。而为了增强单体应用服务能力,会通过在代码中使用多线程,从而给服务更好的处理能力。在此情况下,如果有大量请求访问,那么对于单体应用中涉及数据的操作(增删改)部分,容易造成线程之间的对于资源的争抢而产生脏数据或数据不一致,此时我们可以通过加锁来解决,JUC包下提供了各种锁,来避免上述情况。
如果我们将此应用部署到多台服务器上(从单体应用变成分布式服务),如图所示:
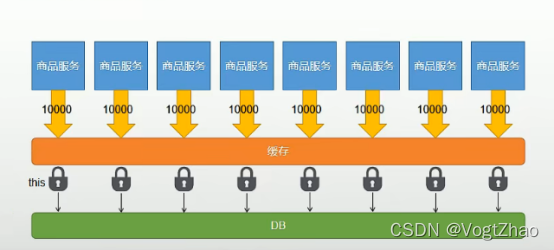
该商品服务部署到多台服务器上,通过负载均衡方式将流量分发到不同的机器上,由于使用的锁只是本地锁,无法保证在分布式部署的情况下只有一个请求或线程访问数据库和缓存。
再此情景下,引入分布式锁,通过分布式锁,针对某一数据或服务,控制分布式应用在高并发的情况下,仍只有一个服务访问数据库或缓存。
自定义分布式锁
原理
如下图所示:
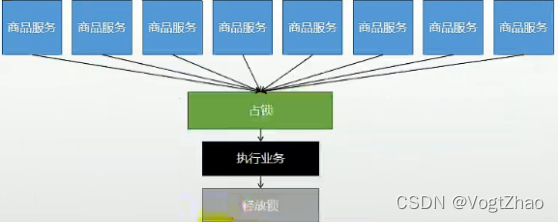
当有多个应用请求同一个服务时,让多个服务去获取锁(占锁),获取到锁的应用才去执行业务,业务执行完成之后,释放锁。
这里,我们使用redis实现分布式锁。当应用请求时,首先向redis中写入一个key 为lock的键值对(value任意),当其他应用在请求时,首先会检查redis中是否存在这个key值,如果存在,则等待key已经被删除之后在执行。创建该key的应用首先会执行,执行完成之后,删除key,交由其他线程执行。流程图如下:
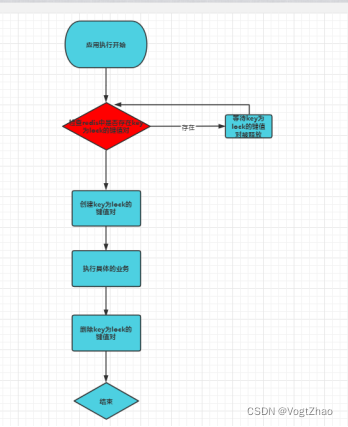
原始代码:
public Map<String,Object> getCateLogJsonWithRedisLock() throws Exception {
return this.getCategoryFromDb();
}
public Map<String,Object> getCategoryFromDb() throws Exception {
Map<String, Object> result = new HashMap<>();
String key = "cate:log:json";
// 如果缓存中存在,则直接从缓存中提取数据;
if (redisTemplate.hasKey(key)) {
String cateLogJSON = redisTemplate.opsForValue().get(key);
result = JSON.parseObject(cateLogJSON, new com.alibaba.fastjson.TypeReference<Map<String, Object>>() {
});
return result;
}
// 如果缓存中不存在数据,则从数据库中查询,并将结果写到缓存中;
result = getCateLogJson2();
redisTemplate.opsForValue().set(key, JSON.toJSONString(result), 1, TimeUnit.SECONDS);
return result;
}
自定义分布式锁--- 阶段一
原理图:
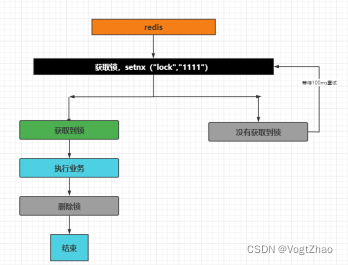
如上图所示,这里我们使用redis实现分布式锁,redis中string类型操作setnx操作,表示当前redis中不存在指定key时,向redis中写入内容;该方法在代码中体现为:
redisTemplate.opsForValue().setIfAbsent("lock", "1111")
表示为当redis中不存在key为lock的值时,将它写入到缓存中,并且value为 1111;
按照原理图修改代码后:
public Map<String,Object> getCateLogJsonWithRedisLock() throws Exception {
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "1111",10,TimeUnit.SECONDS);
Map<String, Object> result = new HashMap<>();
if (!lock) {
// 加锁不成功,执行
try{
Thread.sleep(100);
}catch (Exception ex) {
ex.printStackTrace();
}
// 表示加锁不成功的情况下,尝试在100ms后重新获取锁;
result = getCateLogJsonWithRedisLock();
} else {
result = this.getCategoryFromDb();
// 业务执行完成,尝试删除锁;
redisTemplate.delete("lock");
}
return result;
}
思考:
如果我们的业务代码:this.getCategoryFromDb()在执行过程中宕机或出现异常,导致无法删除锁,从而导致锁无法被删除引起死锁的现象;
解决方案:
在使用方法setIfAbsent 设置值时,可以使用给key设置过期时间;
代码调整:
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "1111",10,TimeUnit.SECONDS);
自定义分布式锁---阶段二
在阶段一中,我们保证了加锁的一致性,我们通过代码
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "1111",10,TimeUnit.SECONDS);
保证了加锁的一致性,但在删错锁方面,仍存在问题。试想,如果设置锁过期的时间为10s,但业务代码的执行时间需要20s(大于锁过期的时间)那么在业务代码执行完成之后,删除的锁一定是自己当初自己上的那把锁吗?
举个例子,当前请求A执行时,在redis中增加key为lock的键值对作为锁。请求B 、请求C在执行时,检查到已经上锁操作,那么会进入等待并不断获取到锁。如果请求A在执行过程中由于业务时间过长,导致lock自动过期,请求B获取到锁,并开始执行业务逻辑。在业务A执行完成后,删除key,此时删除的lock是B设置的锁,依此类推,每个请求在执行完成后,删除的锁不是自己设置的。依然会导致出现脏数据或者数据不一致;
解决方案如下图所示:
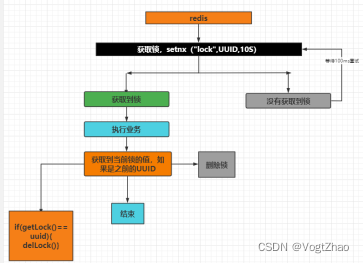
代码调整:
public Map<String,Object> getCateLogJsonWithRedisLock() throws Exception {
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,10,TimeUnit.SECONDS);
Map<String, Object> result = new HashMap<>();
if (!lock) {
// 加锁不成功,执行
try{
Thread.sleep(100);
}catch (Exception ex) {
ex.printStackTrace();
}
result = getCateLogJsonWithRedisLock();
} else {
result = this.getCategoryFromDb();
// 业务执行完成,尝试删除锁;
String lockValue = redisTemplate.opsForValue().get("lock");
if (lockValue.equals(uuid)) {
redisTemplate.delete("lock");
}
}
return result;
}
思考:如果我们删除锁的时候,遇到如下情况:
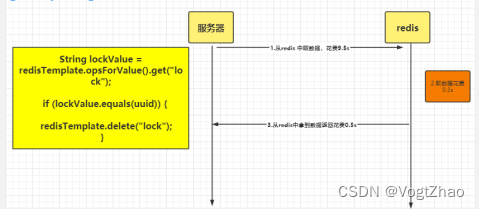
lock在redis中保存的时间为10s,当服务A拿到数据时,redis已经将对应的key删除。尽管在执行代码lockValue.equals(uuid)比对成功,执行删除操作,但此前由于网络等问题导致在获取数据比对前,当前服务创建的lock被删除掉,服务B开始抢占锁并创建自己对应的key为lock的键值对。所以,此时服务A删除的锁,是服务B 创建的;
解决方案: 获取值对比 + 对比成功删除 => 这两项操作合在一起必须得是原子操作;
在这里我们使用lua脚本实现锁的原子删除,将需要比对的值放到redis一侧进行比较,当比对成功后直接删除;代码调整如下:
public Map<String,Object> getCateLogJsonWithRedisLock() throws Exception {
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,10,TimeUnit.SECONDS);
Map<String, Object> result = new HashMap<>();
if (!lock) {
// 加锁不成功,执行
try{
Thread.sleep(100);
}catch (Exception ex) {
ex.printStackTrace();
}
result = getCateLogJsonWithRedisLock();
} else {
result = this.getCategoryFromDb();
// 业务执行完成,尝试删除锁;
String script = "if redis.call(\"get\", KEYS[1]) == ARGV[1] then\n" +
"\n" +
"return redis.call(\"del\", KEYS[1])\n" +
"\n" +
"else\n" +
"\n" +
"return 0\n" +
"\n" +
"end"; // 删除锁的lua脚本;
Integer redisExecuteResult = redisTemplate.execute(new DefaultRedisScript<Integer>(script, Integer.class), Arrays.asList(new String[]{"lock"}), uuid);
}
return result;
}
redisTemplate.execute 负责执行lua脚本:
第一个参数是需要执行的脚本对象;
第二个参数是需要操作的key的集合;
第三个参数是需要在redis一端比对值;
new DefaultRedisScript<Integer>(script, Integer.class) 传递参数:
script 表示当前需要执行的lua脚本文件;
Integer.class 表示当前需要执行的脚本文件后返回的值;
思考: 如果我的业务执行时间很长,导致删除lock时,lock已经不存在,那么删除操作依然失败。
解决方案:
- 最简单的方式是增加lock的存活时间;
2. 最复杂的方法是增加看门狗机制,在业务执行完成以前,不断给lock续期;
总结
综上,使用redis作为分布式锁,必须满足以下两点:
- 加锁保证原子性;
- 解锁或删除锁必须保证原子性;


















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











