






 本文澄清了网上关于Java排序功能的误解,指出无论是集合还是数组,Java 1.8中均可使用比较符对基本数据类型进行排序。通过分析Collections.sort源码,揭示其内部将集合转化为数组,利用快速排序和优化的归并排序进行高效排序的原理。
本文澄清了网上关于Java排序功能的误解,指出无论是集合还是数组,Java 1.8中均可使用比较符对基本数据类型进行排序。通过分析Collections.sort源码,揭示其内部将集合转化为数组,利用快速排序和优化的归并排序进行高效排序的原理。
记得以前在网上一些人说sort只能对集合进行排序,不能对数组进行排序,说是sort里用的是方法比较排序而不是比较符比较排序,而基本数据类型是不能调用方法的。对此我特意看了下源码,不知道是不是jdk版本的问题,1.8里不管是集合的sort还是数组的sort本质上都可以用比较符对基本数据类型进行比较排序(1.7,1.8开始改的还是挺多的,比如1.8接口里还能有静态含有方法体的普通方法)
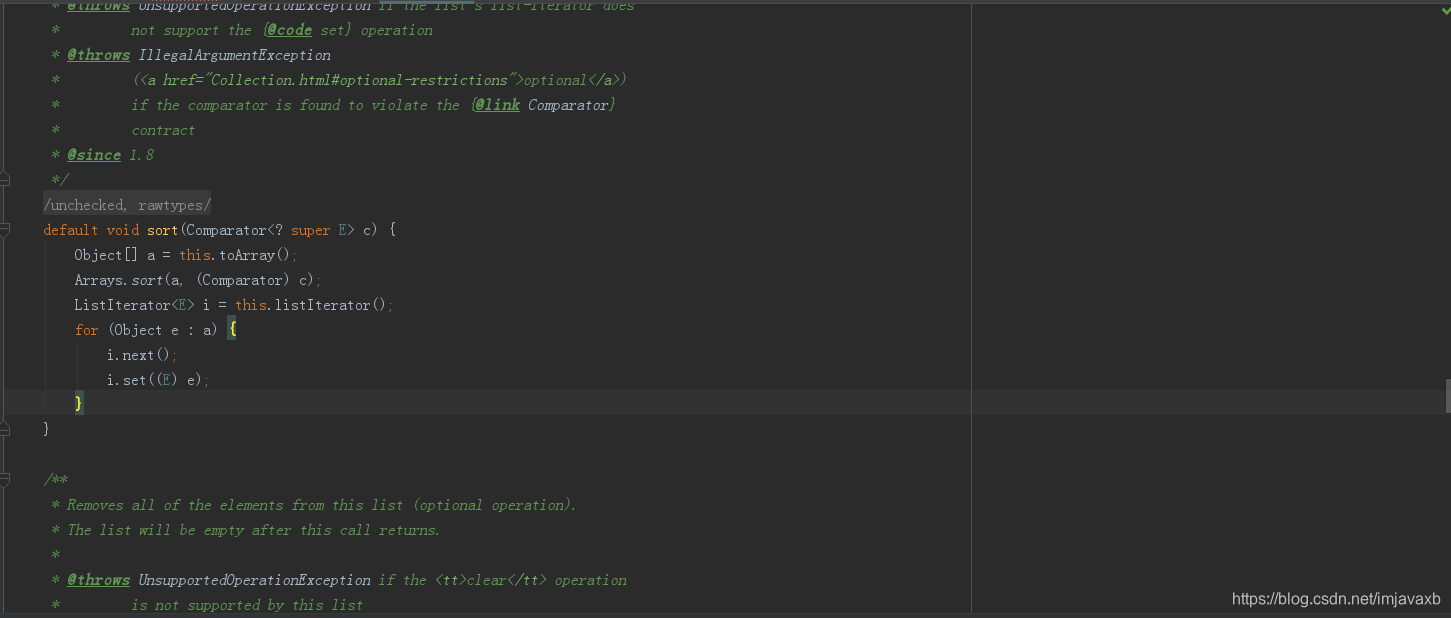
这是Collections.sort的源码,对集合进行排序,很明显,它是把集合转换为数组后用数组的Arrays.sort进行比较排序的(主要使用快速排序--》排序基本数据类型和优化的归并排序--》排序Object类型),排序完了之后再把数组塞进集合里,这就比较有意思了

















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









