







 本文介绍 JDK 1.8 中新增的 Stream API 的使用方法,包括数据过滤、去重、转换、分页及统计等功能,并通过具体示例展示了如何利用这些功能高效处理集合数据。
本文介绍 JDK 1.8 中新增的 Stream API 的使用方法,包括数据过滤、去重、转换、分页及统计等功能,并通过具体示例展示了如何利用这些功能高效处理集合数据。
在JDK1.8中整个类集提供的接口出现大量default或则是static方法,以Collection的父类接口Iterator接口里面定义一个方法来观察:default void forEach(Consumer<? super T>action);
范例:
import java.util.ArrayList;
import java.util.List;
public class Demo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("Hello");
all.add("World");
all.add("God");
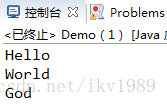
all.forEach(System.out::println);
}
}
==============分割线 ==============
除了使用Iterator迭代取出并处理数据外,在JDK1.8还提供了java.util.stream.Stream,这个类可以利用Collection提供的操作:
default Stream<E>stream
范例:取得Stream类对象
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("Hello");
all.add("World");
all.add("God");
Stream<String> stream = all.stream();// 取得Stream对象
System.out.println("数据个数为:" + stream.count());// 取得数据个数
}
}
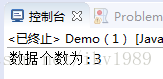
==============分割线 ==============
范例:取消重复数据
· Stream类提供有一个可以消除重复的方法:public Stream<T>distinct();
·收集器(最后使用收集):public <R,A>R collect(Collctor<?super T,A,R>collector);
|-Collector类:public static<T>Collector<T,?,List<T>>toList();
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("Hello");
all.add("Hello");
all.add("World");
all.add("Java");
// 1.取得Stream类对象
Stream<String> stream = all.stream();
// 2.去除掉所有重复数据后形成新的不包含重复数据的集合数据
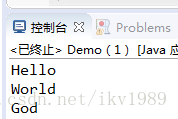
List<String> newAll = stream.distinct().collect(Collectors.toList());
newAll.forEach(System.out::println);
}
}
==============分割线 ==============
Stream类里面提供数据过滤操作public Stream<T>filter(Predicate<? super T>predicate);(但是无法区别大小写)
范例:
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("Java");
all.add("MySQL");
all.add("Oracle");
all.add("Android");
// 1.取得Stream类对象
Stream<String> stream = all.stream();
// 2.去除掉所有重复数据后形成新的不包含重复数据的集合数据
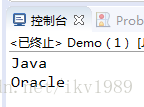
List<String> newAll = stream.distinct().filter((x)->x.contains("a")).collect(Collectors.toList());
newAll.forEach(System.out::println);
}
}
==============分割线 ==============
Stream类接口提供了数据专门的处理操作:public <R>Stream<R>map(Function<? super T,? extends R> mapper);
范例:
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("Java");
all.add("MySQL");
all.add("Oracle");
all.add("Android");
// 1.取得Stream类对象
Stream<String> stream = all.stream();
// 2.去除掉所有重复数据后形成新的不包含重复数据的集合数据
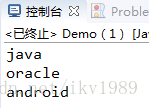
// 3.把数据中所有"A"字符转换成小写"a"过滤并保留。
List<String> newAll = stream.distinct().map((x) -> x.toLowerCase()).filter((x) -> x.contains("a"))
.collect(Collectors.toList());
newAll.forEach(System.out::println);
}
}
==============分割线 ==============
在Stream接口提供了进行集合数据分页的操作:
· 设置跳过的数据行数:public Stream<T>skip(long n);
· 设置取出数据个数:public Stream<T>limit (long maxSize)。
范例:
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("Java");
all.add("MySQL");
all.add("Oracle");
all.add("Android");
// 1.取得Stream类对象
Stream<String> stream = all.stream();
// 2.去除掉所有重复数据后形成新的不包含重复数据的集合数据
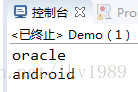
// 3.跳过2行数据后取出2个数据。
List<String> newAll = stream.distinct().map((x) -> x.toLowerCase()).skip(2).limit(2)
.collect(Collectors.toList());
newAll.forEach(System.out::println);
}
}
==============分割线 ==============
在Stream接口提供了进行集合数据分页的操作:
· 全匹配:public boolean allMatch(Predicate<? super T>predicate);
· 匹配任意一个:public boolean anyMatch(Predicate <? super T>predicate)。
范例:
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("Java");
all.add("MySQL");
all.add("Oracle");
all.add("Android");
Stream<String> stream = all.stream();
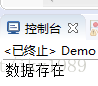
if (stream.anyMatch((x) -> x.contains("Java"))) {
System.out.println("数据存在");
} else {
System.out.println("数据不存在");
}
}
}
==============分割线 ==============
在断言性函数式接口提供如下方法:
· 或操作:default Predicate<T> or(Predicate<? super T>other);
· 与操作: default Predicate<T>and(Predicate<? super T>other)。
import java.util.ArrayList;
import java.util.List;
import java.util.function.Predicate;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("Java");
all.add("MySQL");
all.add("Oracle");
all.add("Android");
Predicate<String> p1 = "Java"::contains;//接口函数原本语法
Predicate<String> p2 = (x) -> x.contains("Oracle");//Lamda表达式
Stream<String> stream = all.stream();
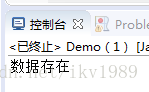
if (stream.anyMatch(p1.or(p2))) {
System.out.println("数据存在");
} else {
System.out.println("数据不存在");
}
}
}
==============分割线 ==============
如果要想更好的返回出Stream的操作优势,必须结合MapReduce观察、
· 数据分析方法: public Optional<T>reduce(BinaryOperator<T>accumulator)。
|-做数据统计使用
范例:
import java.util.ArrayList;
import java.util.List;
class Shop {
private String name;// 商品名称
private double price;// 商品价格
private int amount;// 购买数量
public Shop(String name, double price, int amount) {
this.name = name;
this.price = price;
this.amount = amount;
}
public String getName() {
return this.name;
}
public double getPrice() {
return this.price;
}
public int getAmount() {
return this.amount;
}
}
public class Demo {
public static void main(String[] args) throws Exception {
List<Shop>all=new ArrayList<>();
all.add(new Shop("充气娃娃", 999, 1));
all.add(new Shop("安卓手机", 2380, 20));
all.add(new Shop("苹果手机", 1999, 10));
all.add(new Shop("清朝尿壶", 888, 8));
double s=all.stream().map((x)->x.getPrice()*x.getAmount()).reduce((sum,m)->sum+m).get();
System.out.println("总价:"+s);
}
}
==============分割线 ==============
更完善的统计操作:
· 按照Double处理: public DoubleStream mapToDouble(ToDoubleFunction<? super T>mapper);
· 按照Int处理: public IntStream mapToInt(ToIntFunction<? super T>mapper);
· 按照Long处理:public LongStream mapToLong(ToLongFunction<? super T>mapper);
import java.util.ArrayList;
import java.util.DoubleSummaryStatistics;
import java.util.List;
class Shop {
private String name;// 商品名称
private double price;// 商品价格
private int amount;// 购买数量
public Shop(String name, double price, int amount) {
this.name = name;
this.price = price;
this.amount = amount;
}
public String getName() {
return this.name;
}
public double getPrice() {
return this.price;
}
public int getAmount() {
return this.amount;
}
}
public class Demo {
public static void main(String[] args) throws Exception {
List<Shop>all=new ArrayList<>();
all.add(new Shop("充气娃娃", 999, 1));
all.add(new Shop("安卓手机", 2380, 20));
all.add(new Shop("苹果手机", 1999, 10));
all.add(new Shop("清朝尿壶", 888, 8));
DoubleSummaryStatistics dss=all.stream().mapToDouble((sc)->sc.getAmount()*sc.getPrice()).summaryStatistics();
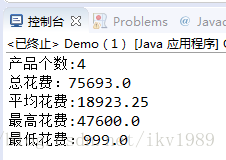
System.out.println("产品个数:"+dss.getCount());
System.out.println("总花费:"+dss.getSum());
System.out.println("平均花费:"+dss.getAverage());
System.out.println("最高花费:"+dss.getMax());
System.out.println("最低花费:"+dss.getMin());
}
}

















 5932
5932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









