







转自:https://zhuanlan.zhihu.com/p/115183832
SyntaxSQLNet是第一个专门针对Spider数据集的算法,论文发布在arXiv的时间为2018年10月。这个算法在Spider任务上exact matching的准确率为19.7%,进行数据增强后准确率为27.2%。
以下对SyntaxSQLNet进行介绍,参考资料为论文原文[1]及其开源代码[2]。
1. 提出问题
之前的Text-to-SQL数据集,有的在任务定义上存在不足(如ATIS、GeoQuery),有的样本太少,有的任务定义过于简单(如WikiSQL)。Spider数据集克服了这些问题:在200个数据库上,人工标注了10181个问题,包含有跨表搜索、子查询等等复杂的任务,覆盖了主要的SQL语法;而且按照领域和复杂度对训练集和测试集进行了划分,更加严格地考察模型的泛化能力。Spider数据集提出了很多新的挑战,需要新的解决思路。
2. SyntaxSQLNet的思路
Spider任务对应的SQL结构比以前复杂得多,预测过程难以用一个简单的Schema来进行管理。但是SQL各个部分间存在逻辑关系,预测一个特定Token的时候,Token的选择范围、对上下文的依赖等等,在不同位置是不一样的。我们需要一个动态的Schema来管理这一切。SyntaxSQLNet的思路是:采用一个树形的语法结构,用递归的形式来管理SQL的生成(如下图所示)。
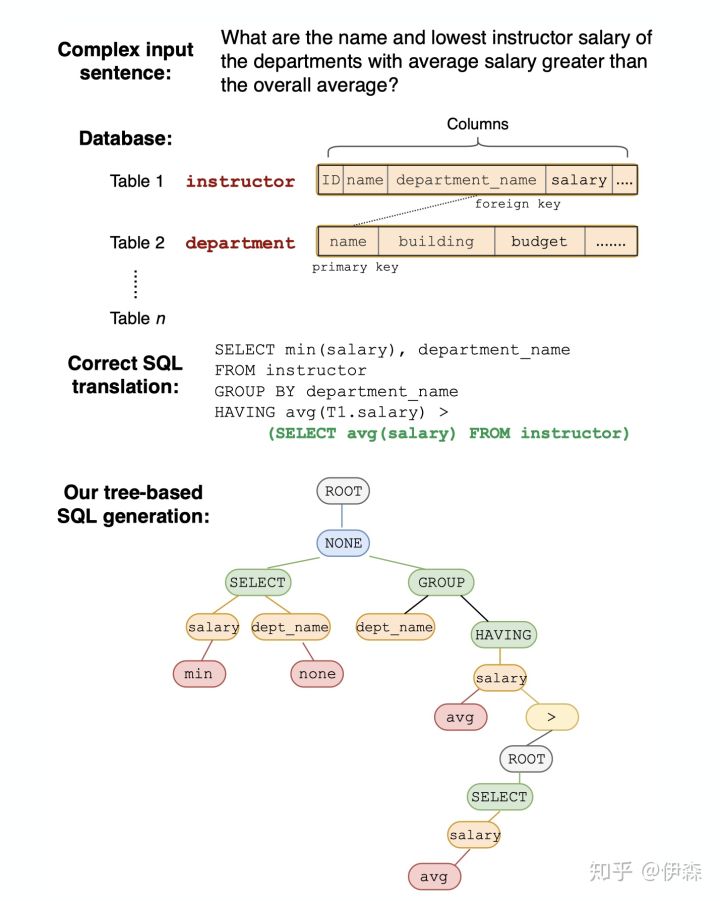
论文中有张图(如下)对SQL生成的整体思路进行了清晰的描述,这里主要围绕这张图进行说明。
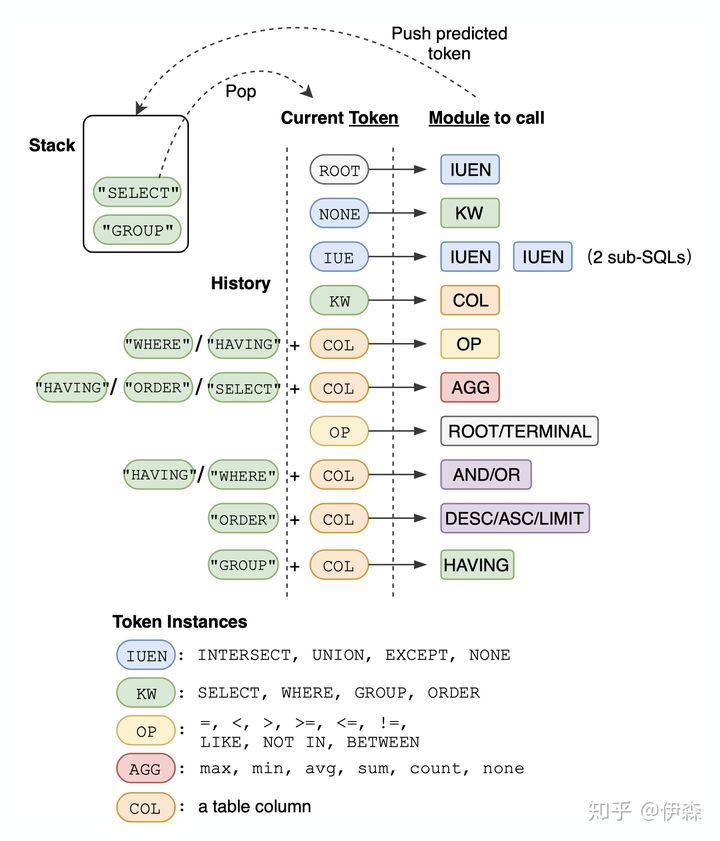
首先,看中间的“Current Token”部分,把SQL语句分成不同的Token:ROOT代表一个SELECT语句的开始;IUE代表INTERSECT,UNION,EXCEPT等。从“Current Token”出发,来决定要调用哪个算法模块预测后续的Token。
其次,看图中右边“Module to call”,各个方块表示不同的算法模块,调用不同模块可以生成相应的Token。共有9种不同类型的模块,这里只对部分模块进行解释:ROOT/TERMINAL,ROOT代表一个查询语句开始;DESC/ASC/LIMIT,这个模块只有前序已经生成了“ORDER BY”才会被触发;HAVING,这个模块只有前序已经生成了GROUP BY才会被触发。
然后,看图中左边“History”部分。具体应该调用哪个算法模块,除了看“Current Token”之外,SyntaxSQLNet还把Token之前的SQL语句也考虑进来,以改善预测准确率。同时,当SQL语句很长的时候,History也附带表示了不同语句之间的依赖信息。
最后,看图的左上角“Stack”部分。Stack用于辅助递归来生成SQL语法树。举个例子,在刚开始的时候,算法会在堆栈里初始化一个ROOT Token,接着从堆栈里推出ROOT Token触发IUEN模块,如果IUEN预测产生NONE Token,算法会把预测出的NONE推入堆栈,这一步完成;下一步,将NONE Token推出,作为“Current Token”触发后面的模块……按此递归,直到Stack变空,预测结束。
3. 其他
1)Encoder
模型输入有Question,Table Schema,SQL History三个部分。Question用BiLSTM进行encoding。
对于Table Schema,和SQLNet只使用了Column Name来做encoding不同,针对Spider任务的复杂性,SyntaxSQLNet把Table Name,Column Name,Column Type一起作为输入,然后通过Bi-LSTM把Table和Column的信息都在一个encoding里来表示。
对于SQL Histroy,需要对当前Token的前序SQL语句进行编码。这里对训练阶段(train)和推断阶段(test)的处理有所区别:training的时候,会直接使用标注数据中提供的gold query来作为SQL History;而在test数据上,会使用前序预测出来的SQL语句来替代。
另外,在进行具体Token预测的时候,Question和SQL History的不同词起到作用是不一样的。为解决这个问题,SyntaxSQLNet在各个模块中使用了Attention机制来提高预测准确率。
2)数据增强
SyntaxSQLNet论文中给出了通过数据增强来提升模型表现的方法。首先在Spider的标注样本上分析提炼出通用的Question-SQL模板,将一些过于简单模板过滤掉后,得到280个复杂度较高的模板。然后利用WikiSQL数据集,对每个数据表任意挑10个模板,随机选择表格中的Columns进行填充。同时,填充的时候会考虑所选择Column的数据类型与需要填充的Slot的数据类型是匹配的,比如都是数值型。这样共产生了约98000个Question-SQL样本用于训练。
参考
- ^SyntaxSQLNet论文 https://arxiv.org/abs/1810.05237
- ^论文作者开源的代码 https://github.com/taoyds/syntaxSQL

















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









