




一、模型架构与技术特性
阿里巴巴最新发布的1.2.1位置系列视觉生成模型,标志着国产多模态AI技术的重大突破。该系列包含两大核心版本:
-
1.3B基础版
-
参数量:13亿
-
显存需求:最低12GB(FP32精度)
-
适用场景:个人开发者/中小型项目
-
生成速度:720P视频约3秒/帧
-
-
14B增强版
-
参数量:140亿
-
显存需求:最低48GB(FP16精度)
-
适用场景:企业级商业应用
-
生成速度:720P视频约7秒/帧(支持多卡并行)
-
技术亮点:
-
混合精度训练架构(支持FP32/FP16/BF16)
-
动态分辨率适配系统(480P/720P自动切换)
-
多模态输入融合引擎(文本+图像协同生成)
二、Ubuntu系统本地部署全流程
2.1 环境预配置
硬件要求:
-
显卡:NVIDIA RTX 16000(推荐48GB显存版)
-
存储:至少100GB SSD空间
-
内存:64GB DDR5
系统准备:
# 安装NVIDIA驱动(需匹配CUDA 11.8) sudo apt install nvidia-driver-525 # 验证驱动安装 nvidia-smi
2.2 Conda环境搭建
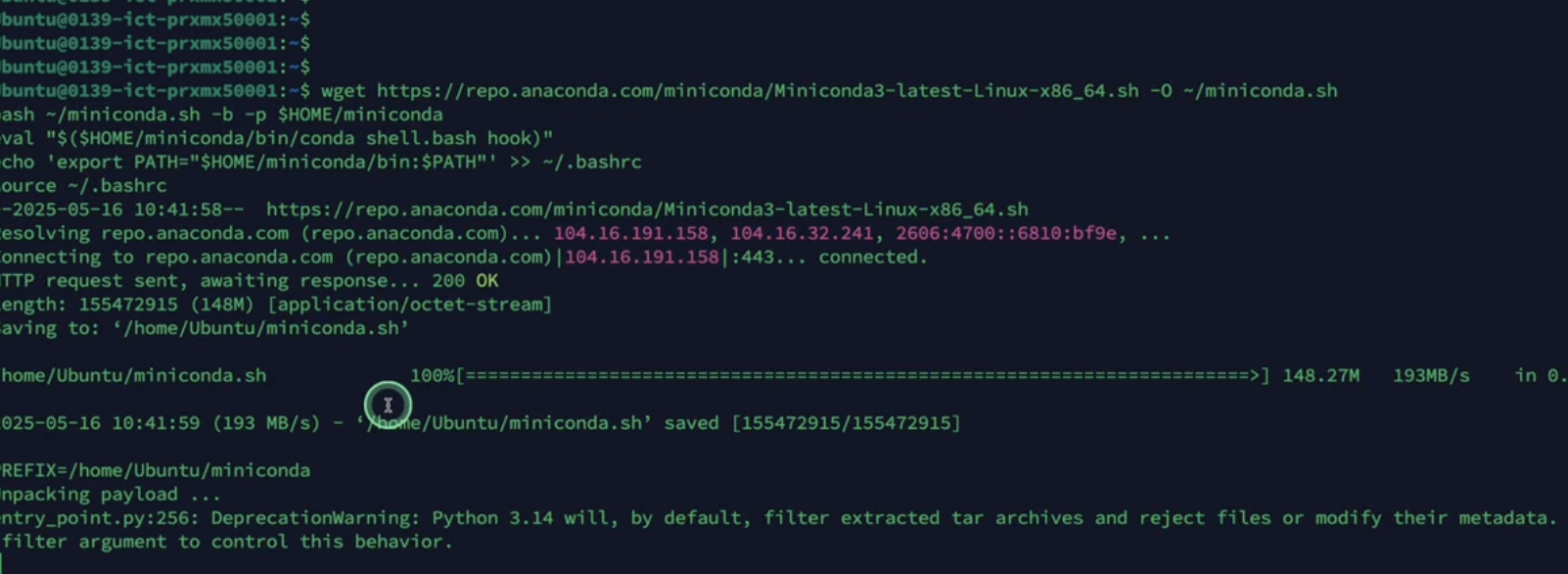
推荐使用Miniconda构建隔离环境:
# 下载安装包 wget https://repo.anac
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1739
1739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









