



| 公司 | 支持 | 结论 |
| Ali | 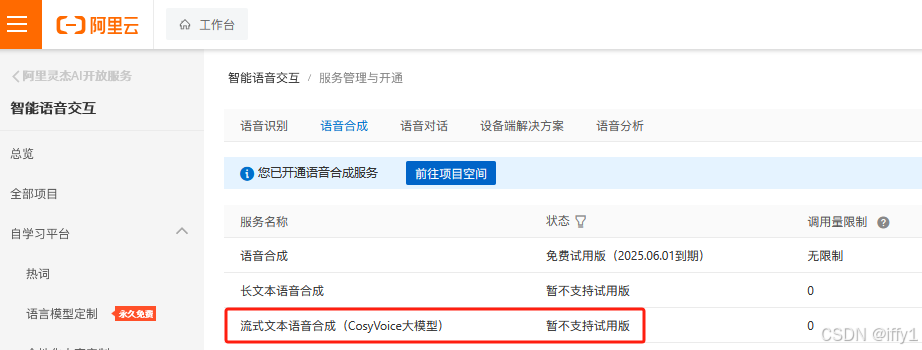 | 不能试用 |
| Baidu | 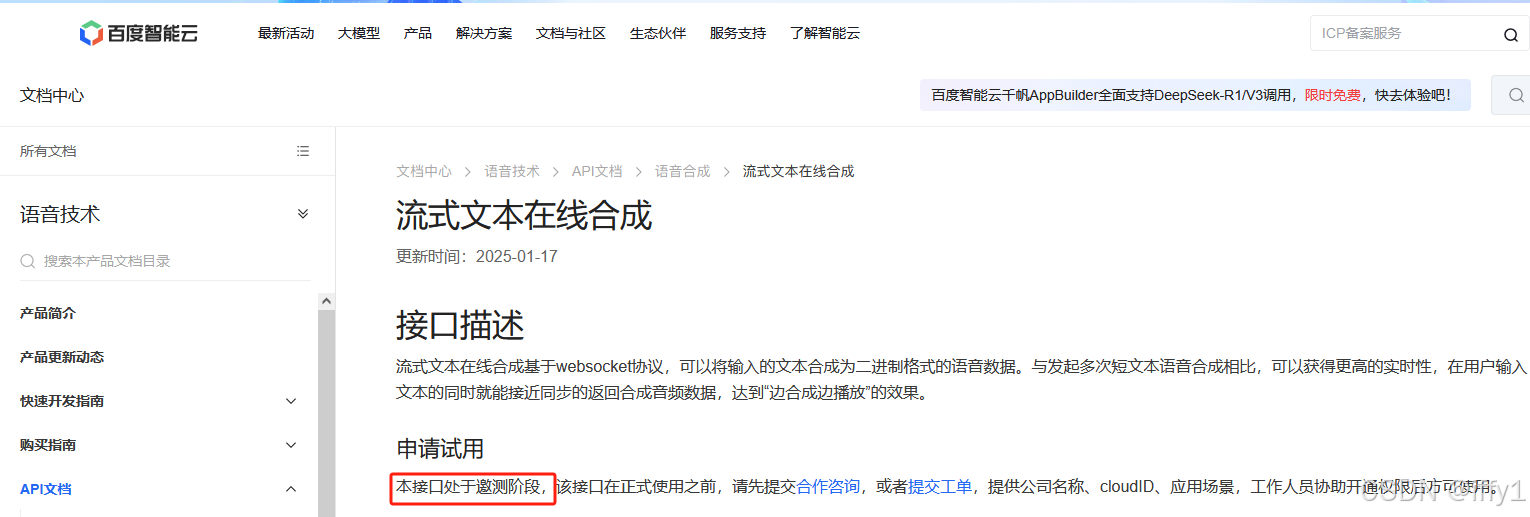 | 不能试用 |
| 腾讯 |  | |
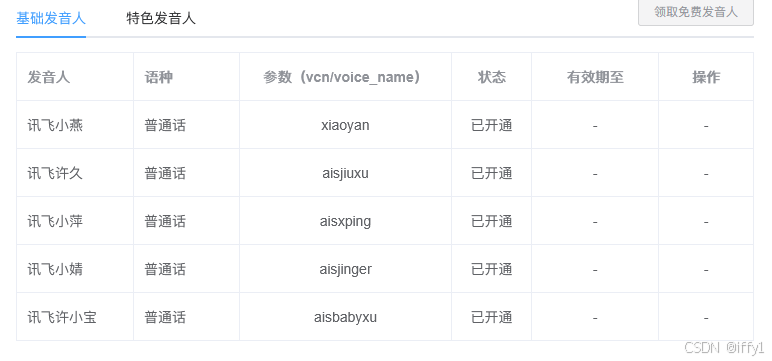
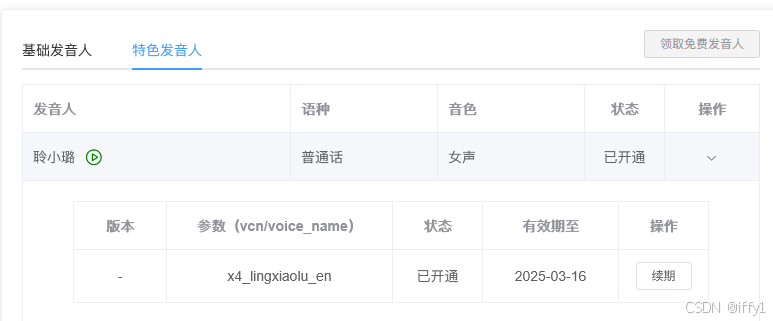
| 讯飞 |  |
基础发音人音质差
特色发音人 数码音也比较重
|
| 火山 | 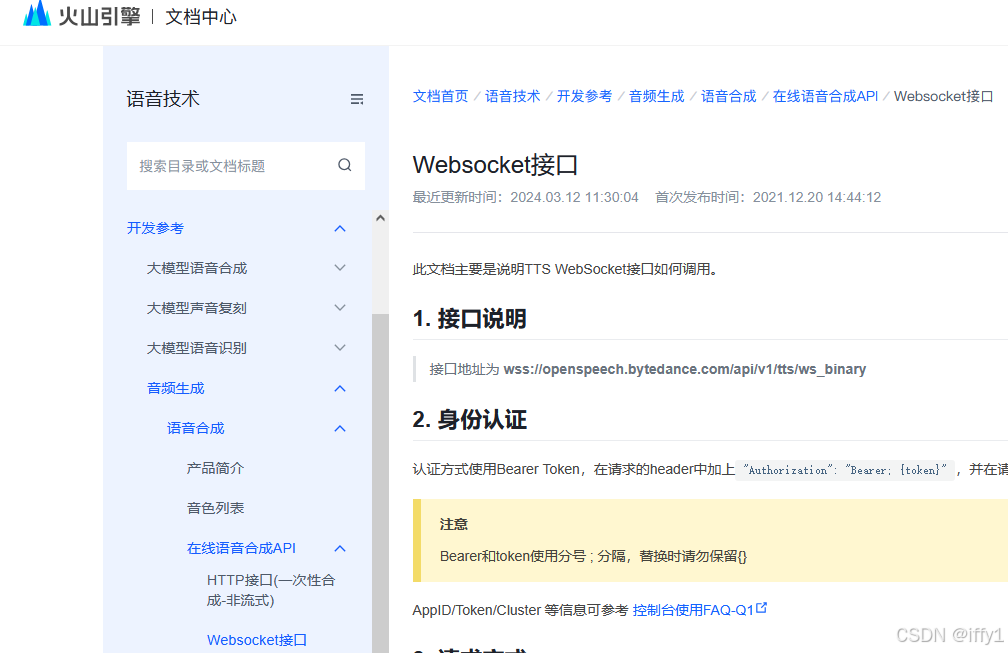 |
接口不规范 接口没有调通 |
在线流式TTS
于 2025-03-01 18:25:18 首次发布
部署运行你感兴趣的模型镜像


您可能感兴趣的与本文相关的镜像

HunyuanVideo-Foley
语音合成
HunyuanVideo-Foley是由腾讯混元2025年8月28日宣布开源端到端视频音效生成模型,用户只需输入视频和文字,就能为视频匹配电影级音效


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









