




 本文深入探讨了HashMap在不同JDK版本中的实现差异,包括数组+链表和数组+链表+红黑树的底层存储机制。详细分析了HashMap的关键属性如初始容量、最大容量、加载因子等,并解释了其内部数据结构Entry的组成。通过关键代码片段阐述了HashMap的基本操作如添加、获取和删除元素的过程,特别关注扩容机制及其实现细节。
本文深入探讨了HashMap在不同JDK版本中的实现差异,包括数组+链表和数组+链表+红黑树的底层存储机制。详细分析了HashMap的关键属性如初始容量、最大容量、加载因子等,并解释了其内部数据结构Entry的组成。通过关键代码片段阐述了HashMap的基本操作如添加、获取和删除元素的过程,特别关注扩容机制及其实现细节。
1.底层存储原理
JDK1.7 数组+链表
JDK1.8 数组+链表+红黑树
数组在内存中是需要一块连续的内存来存储,链表不需要
数组的特性: 由于数组在内存中是连续的且有索引(下标) 所以查询非常快复杂度O(1) 但是添加比较慢,最理想的状态就是O(1) 最不理想的状态是O(n)
O(1)的情况就是刚好插入到末尾 前面的数据都不需要移动
O(n)的情况是刚好插首位,其他的数据都需要向后移动一位
链表新增快,查询慢
查询需要遍历整个链表,最理想的状态就是第一个元素就是我们要找的O(1),
最差的状态就是最后一个使我们要查的元素 O(n)
链表的插入采用头插法 复杂度O(1)
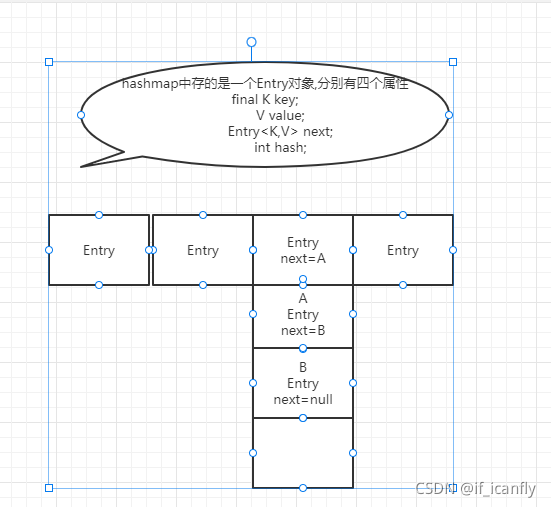
2.关键属性
// 默认初始容量 - 必须是 2 的幂。
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 最大容量 显示指定时也必须是2的幂
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认加载因子 (也就是有3/4被使用则扩容 扩容2倍)
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//表格 真正用于存放数据的数组,根据需要调整大小。长度必须始终是 2 的幂。
transient Entry<K,V>[] table;
//map中已添加的数据总数
transient int size;
// 阈值 大于等于该值需要进行扩容
int threshold;
// 哈希表的负载因子 我们自己指定加载因子时 此参数会覆盖上面的默认加载因子
final float loadFactor;
Entry属性
// key
final K key;
// value
V value;
// 链表指向的下一个元素
Entry<K,V> next;
// hash值
int hash;
3.关键代码
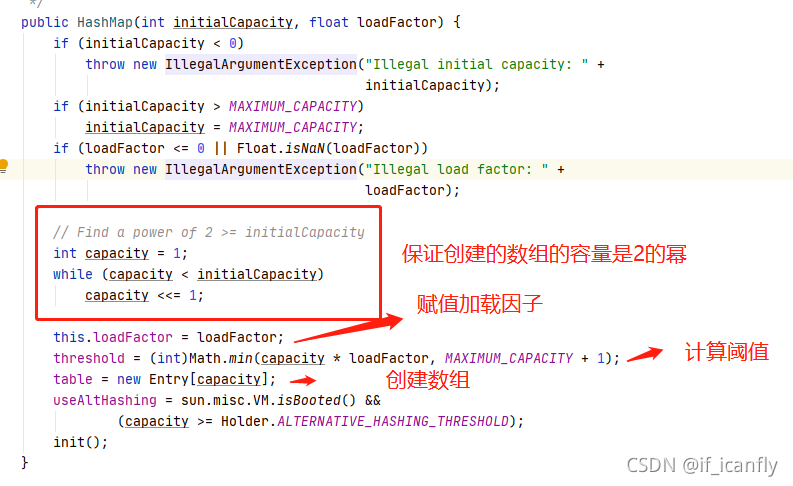
1.构造方法
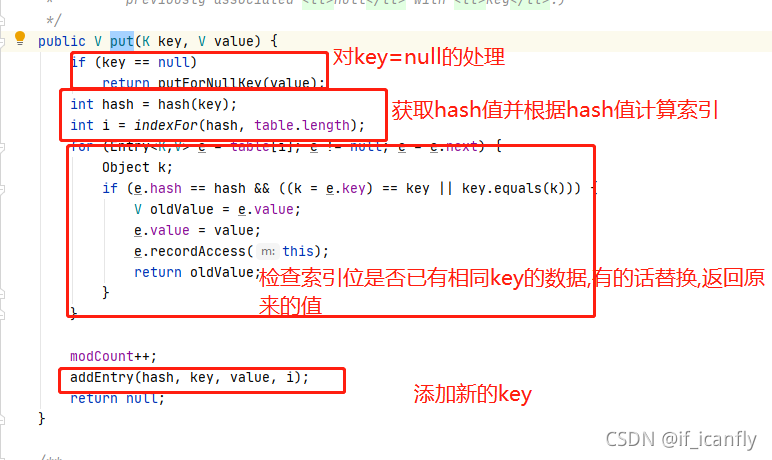
2.put方法
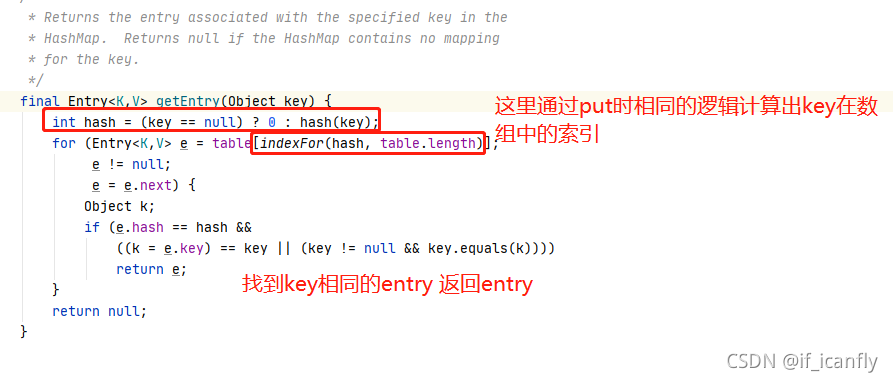
计算索引的关键代码

这里就为什么创建的数组的长度必须是2的幂的原因 因为2的幂次方减一换成二进制每一位都是1,不会存在0的情况,0与任何数&都是0,不能保证离散性.
打一个比方 如果数组长度设置成5 那么5-1=4的二进制就是100 那么不管key的hash值是多少 &计算后的索引只可能返回0 或者4 索引为1,2和3的位置一定不会有数据存入
addEntry逻辑
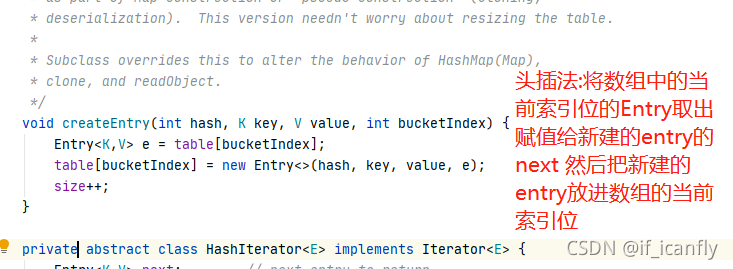
 createEntry
createEntry
3.get
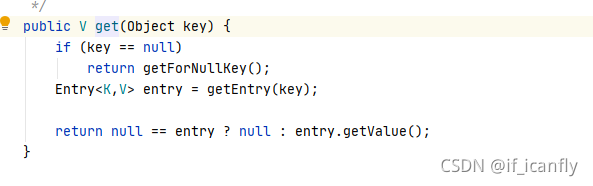
关键代码在getEntry(key)
4.containsKey
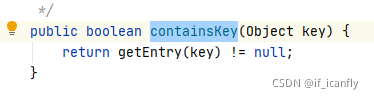
实际就是调用了getKey
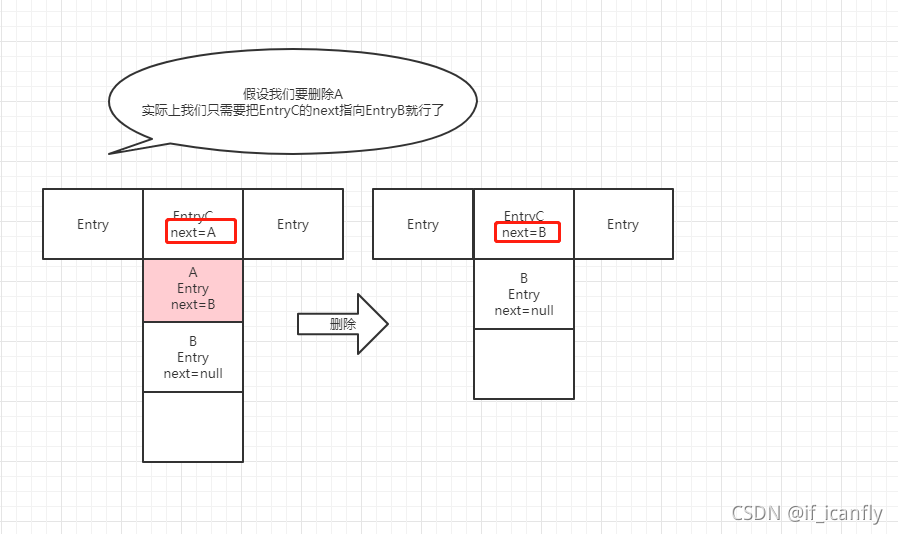
5.remove(key)
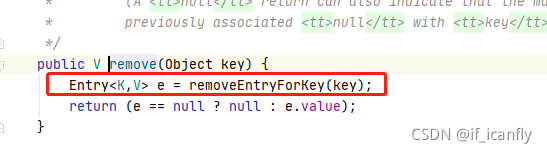

描述得不是很清楚 画个图
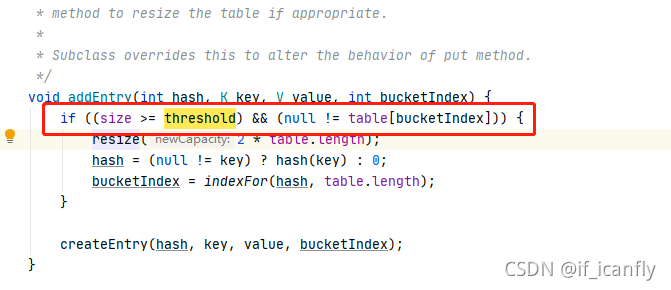
6.关于扩容
我们以new HashMap<>(4)为例
阈值 = 默认加载因子0.75x4= 3
以下情况都会先扩容
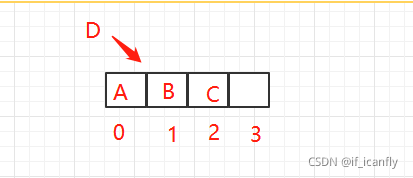
索引为0,1,2的位置都已经有数据了
当第四个数据D再put进来时 计算的数据在数组的索引是0,1,2都会满足上面的扩容条件 size = 3 满足>=threshold 且 table[bucketIndex] != null
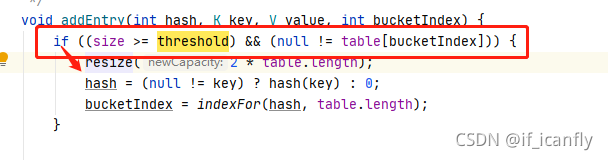
但是如果Dput进来的时候 计算的索引是3 那么不满足扩容条件 不扩容
下面这种情况
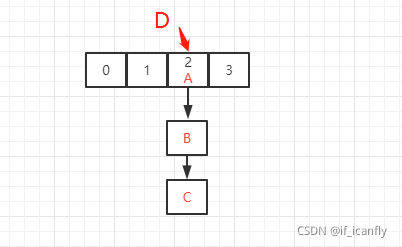
ABC组成的链表在索引为2的位置 且长度已经为3 当Dput进来时,如果根据D的KEY计算出来的索引不是2 就不会扩容 ,如果索引为2 就会扩容

















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









