




 本文探讨了SQL优化的重要性,强调高并发低消耗的查询优化对系统整体性能的影响大于低并发高消耗的查询。通过开启MySQL的general_log日志,可以找出执行频繁的SQL,分析其执行效率,并在项目中定位并优化这些SQL,以提升系统性能。注意,general_log不应长期开启以避免影响MySQL性能。此外,文章还提到了第三方工具可能导致未执行过的SQL出现在日志中,这通常是工具自身执行的结果。
本文探讨了SQL优化的重要性,强调高并发低消耗的查询优化对系统整体性能的影响大于低并发高消耗的查询。通过开启MySQL的general_log日志,可以找出执行频繁的SQL,分析其执行效率,并在项目中定位并优化这些SQL,以提升系统性能。注意,general_log不应长期开启以避免影响MySQL性能。此外,文章还提到了第三方工具可能导致未执行过的SQL出现在日志中,这通常是工具自身执行的结果。
sql优化需要从对整个系统的影响来考虑,哪个sql的优化能给系统整体带来更大的收益,就更需要优化,一般来讲,高并发低消耗的影响>低并发高消耗的影响.
一个频繁执行的高并发 Query 的危险性比一个低并发的 Query 要大很多,当一个低 并发的 Query 执行计划有误时,所带来的影响只是该 Query 请求者的体验会变差,对整 体系统的影响并不会特别突出,但是,如果一个高并发的 Query 执行计划有误,它带来的 后果很可能就是灾难性的。
还有就是我们在做项目的阶段,让项目跑起来才是目标,开发阶段数据量少一般不会出现性能的问题,
对于我们的系统,找到并发并较高的sql尤为重要.
下面介绍一下如何查询系统中哪些sql执行次数比较多
-- 查看日志是否开启
SHOW VARIABLES LIKE '%general%';
-- 将记录插入到表中
SET GLOBAL log_output='TABLE'
-- 打开日志记录
SET GLOBAL general_log=1
-- 关闭日志记录
SET GLOBAL general_log=0
-- 查看记录表
SELECT * FROM mysql.general_log
-- 按sql分组统计查询
SELECT argument, COUNT(*) AS number FROM mysql.general_log GROUP BY argument ORDER BY number DESC;
这个general_log日志不建议一直开启,开启几天找到sql就可以了,否则会影响mysql性能.
找到执行频率高的sql,拉出来执行一下,看一下执行的效率,如果效率不理想需要优化,我们就需要找到这些sql在我们项目中的位置,再进行优化和修改即可.
关于在第三方工具测试时 查询到很多你没有执行过的sql数据的解释:
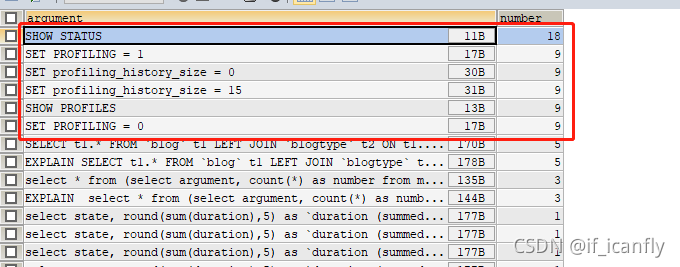
这是由于我们使用的第三方工具执行了这些sql造成的,比如我用的sqlyog,打开工具,历史记录可以看到如下信息
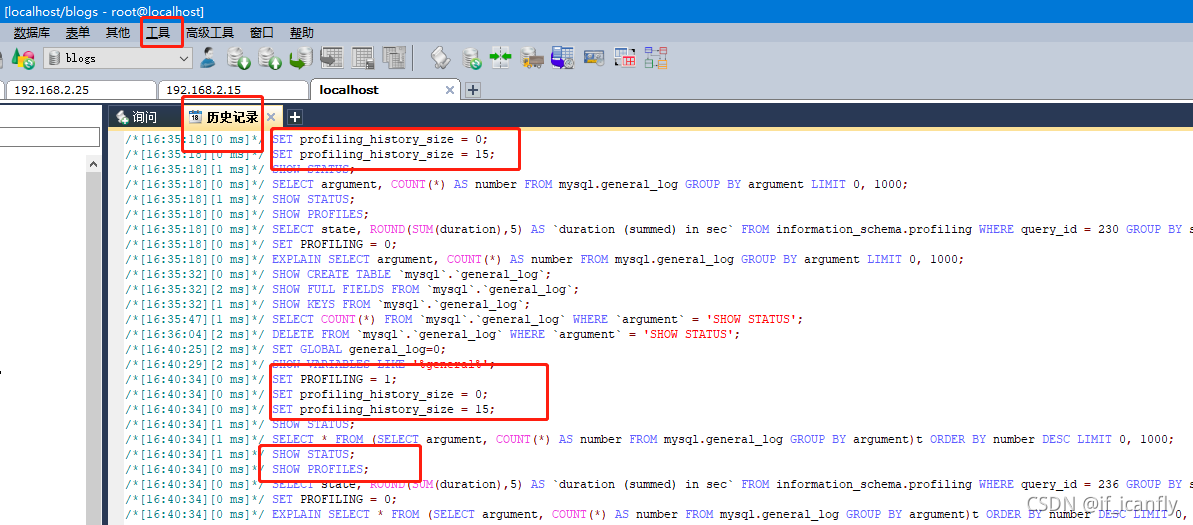
这里有很多sql都是我们工具类执行的

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









