




 本文详细介绍Pandas库中关键函数的使用方法,包括数据类型转换、列删除、列名修改、位置选择以及数据帧转置等操作,为数据处理提供实用技巧。
本文详细介绍Pandas库中关键函数的使用方法,包括数据类型转换、列删除、列名修改、位置选择以及数据帧转置等操作,为数据处理提供实用技巧。
1. astype
2. df.__delitem__
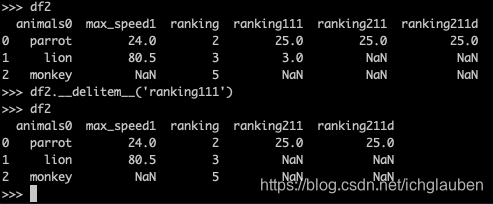
df.__delitem__是删除列数
>>> df2
animals0 max_speed1 ranking2
0 parrot 24.0 second
1 lion 80.5 1
2 monkey NaN None
>>> df2.__delitem__('ranking2')
>>> df2
animals0 max_speed1
0 parrot 24.0
1 lion 80.5
2 monkey NaN
############
>>> df2
animals0 max_speed1 ranking ranking111 ranking211 ranking211d
0 parrot 24.0 2 25.0 25.0 25.0
1 lion 80.5 3 3.0 NaN NaN
2 monkey NaN 5 NaN NaN NaN
>>> df2.__delitem__('ranking111')
>>> df2
animals0 max_speed1 ranking ranking211 ranking211d
0 parrot 24.0 2 25.0 25.0
1 lion 80.5 3 NaN NaN
2 monkey NaN 5 NaN NaN
3.df.columns 修改列label
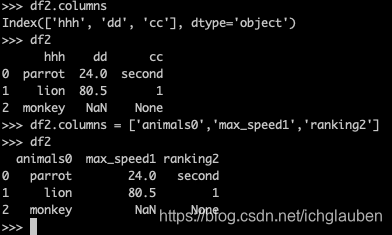
>>> df2.columns
Index(['hhh', 'dd', 'cc'], dtype='object')
>>> df2
hhh dd cc
0 parrot 24.0 second
1 lion 80.5 1
2 monkey NaN None
>>> df2.columns = ['animals0','max_speed1','ranking2']
>>> df2
animals0 max_speed1 ranking2
0 parrot 24.0 second
1 lion 80.5 1
2 monkey NaN None
4.iloc loc的位置
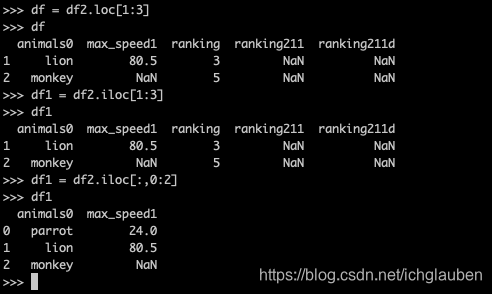
>>> df = df2.loc[1:3]
>>> df
animals0 max_speed1 ranking ranking211 ranking211d
1 lion 80.5 3 NaN NaN
2 monkey NaN 5 NaN NaN
>>> df1 = df2.iloc[1:3]
>>> df1
animals0 max_speed1 ranking ranking211 ranking211d
1 lion 80.5 3 NaN NaN
2 monkey NaN 5 NaN NaN
>>> df1 = df2.iloc[:,0:2]
>>> df1
animals0 max_speed1
0 parrot 24.0
1 lion 80.5
2 monkey NaN
5.pd.T
- 相当于转置
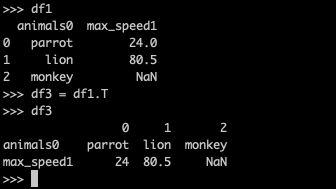
>>> df3 = df1.T
>>> df3
0 1 2
animals0 parrot lion monkey
max_speed1 24 80.5 NaN
>>>
6. df.as_matrix
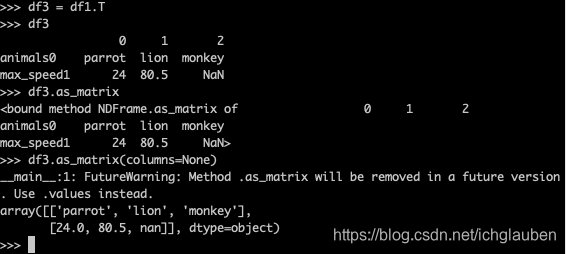
- df3转换为了
array[[xx],[yy]]
>>> df3
0 1 2
animals0 parrot lion monkey
max_speed1 24 80.5 NaN
>>> df3.as_matrix(columns=None)
__main__:1: FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.
array([['parrot', 'lion', 'monkey'],
[24.0, 80.5, nan]], dtype=object)

















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









