






本文介绍了目前 AI 生成视频较好的两种方法 AnimateDiff 及 SVD ,并包含文生视频、图生视频、视频生视频等等多种方法的工作流源文件及效果展示。
AnimateDiff
AnimateDiff 使用稳定扩散模型将文字提示转化为视频,使用控制模块来影响稳定扩散模型。 它通过各种视频短片进行训练。控制模块对图像生成过程进行调节,以生成一系列与其学习的视频片段相似的图像。与 ControlNet 一样,AnimateDiff 的控制模块可用于任何稳定扩散模型。目前仅支持 Stable Diffusion v1.5 模型。
在SD WebUI中的使用方法:

在ComfyUI中的使用方法:
一.提示词生成视频
1.方法
在提示词编写上,使用动词可以驱动AnimateDiff产生动画,例如walking、running、dancing等,类似wind会对头发和树叶产生影响。
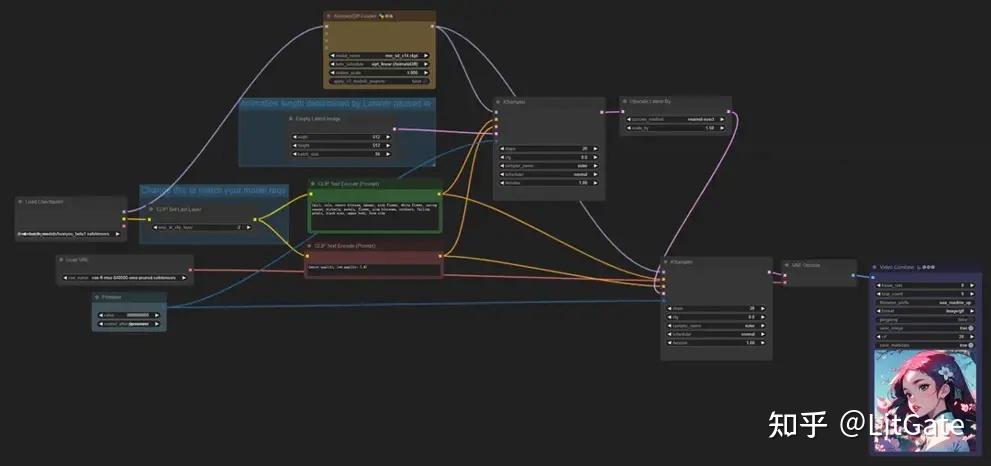
2.效果展示
对于单人角色比较简单的动作表现非常好,也适合制作风景类动画,对于多人物及一些复杂的动画比如格斗、跑步会略差一些。


份完整版的comfyui整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

二.图生视频
1.方法
输入第一帧和结束帧的图像制作动画
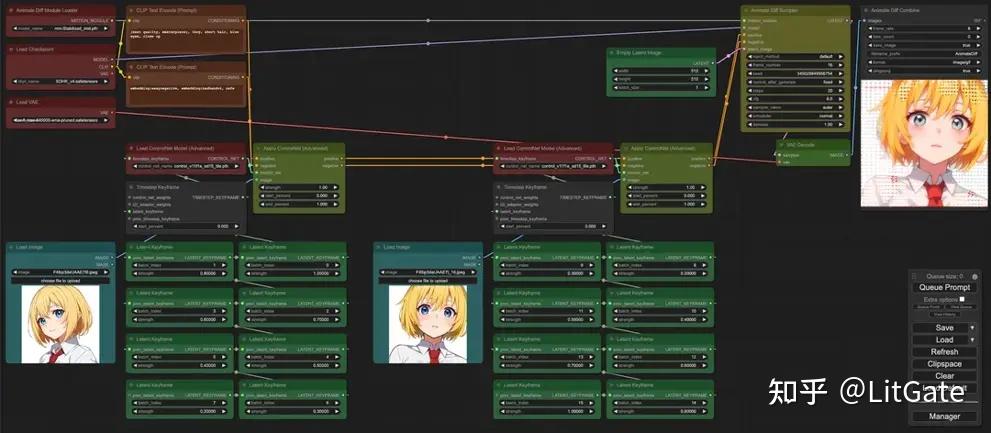
2.效果展示





三.提示词游历
1.方法
用Prompt Travel提示词游历语法,可以设置在不同的时间段使用不同的提示词产生不同的动画,适用于制作一些变形动画效果。
语法编写规则1:
帧数1:提示词1
帧数2:提示词2
以四季变换动画的提示词为例:
“0” :“spring day, cherryblossoms”,
“25” :“summer day, vegetation”,
“50” :“fall day, leaves blowing in the wind”,
“75” :“winter, during a snowstorm, earmuffs”
语法编写规则2:
在提示词前后增加公共提示词
以模特换衣服动画的提示词为例:前部分控制模特容貌稳定,后部分让模特衣服变化
1 girl model,zend4y4,long hair,catwalking on the runway,stage lighting background,best
quality,masterpiece,hand painted textures,intricate details,realistic,<lora:add detail:0.8>
0: plaid_shirt,jeans,
16: plaid shirt,jeans,beret,
32: hooded track jacket,hot_pants,
48: white dress _shirt,buruma,
64: off-shoulder_dress,high_heel boots,
2.效果展示
能够生成时间较长的视频,且过渡效果丝滑。


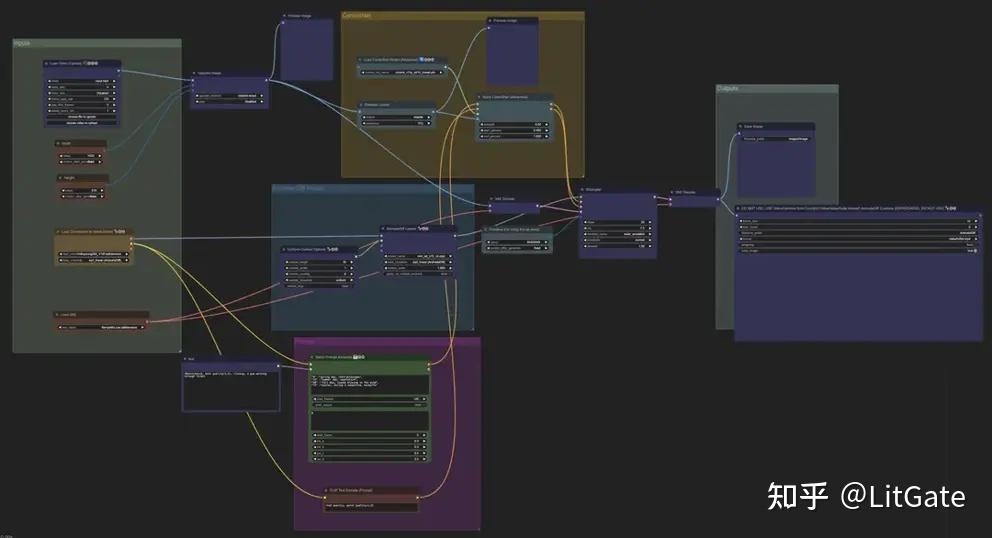
四.ComfyUI+AnimateDiff+Controlnet 控制视频
1.AnimateDiff+Lineart控制

2D动画

Logo动画

Logo动画

Logo动画

Logo动画
2.AnimateDiff+Openpose+Depth控制
**方法:**选择一段质量较高的源视频,视频中的人物与背景易于区分,姿势可以用提示词清晰描述,使用艺术风格简洁的打模型和lora,最好使用 “提示词游历”,随着视频的变化而改变提示词。提示词的细节对于让动画变得栩栩如生十分关键,比如加入:表情、眨眼等描述。
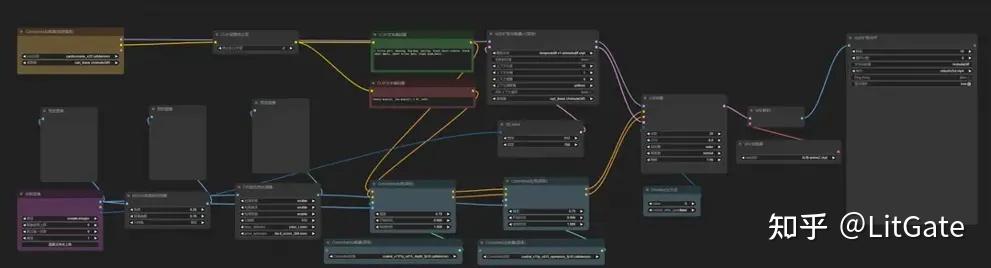

3.AnimateDiff+ControlNet+IPAdapter视频转风格重绘

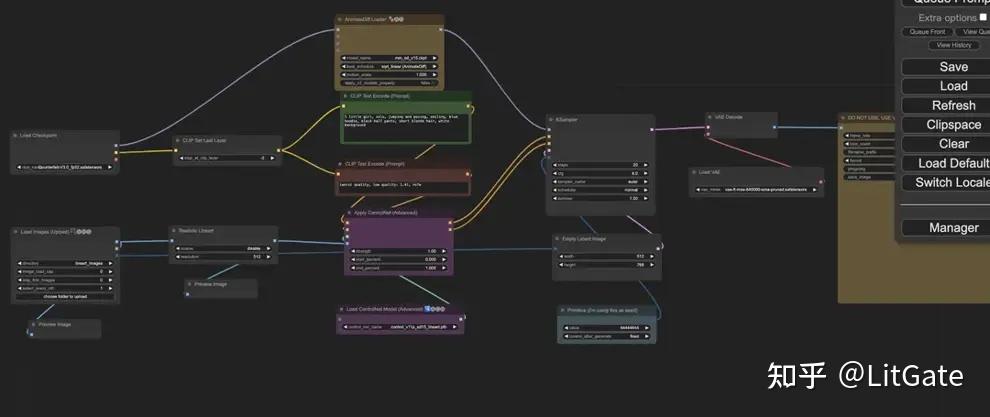
五.局部视频
1.方法
用提示词游历的方法可以让动画生成更准确,这里以眨眼动画为例:
“0” :“masterpiece, best quality, 1girl, solo, blue eyes, face closeup”,
“6” :“masterpiece, best quality, 1girl, solo, face closeup, (closed_eyes:1.2)”,
“11” :“masterpiece, best quality, 1girl, solo, face closeup, (closed_eyes:1.2),(smile:1.2)”,
“15” :“masterpiece, best quality, 1girl, solo, blue eyes, face closeup”
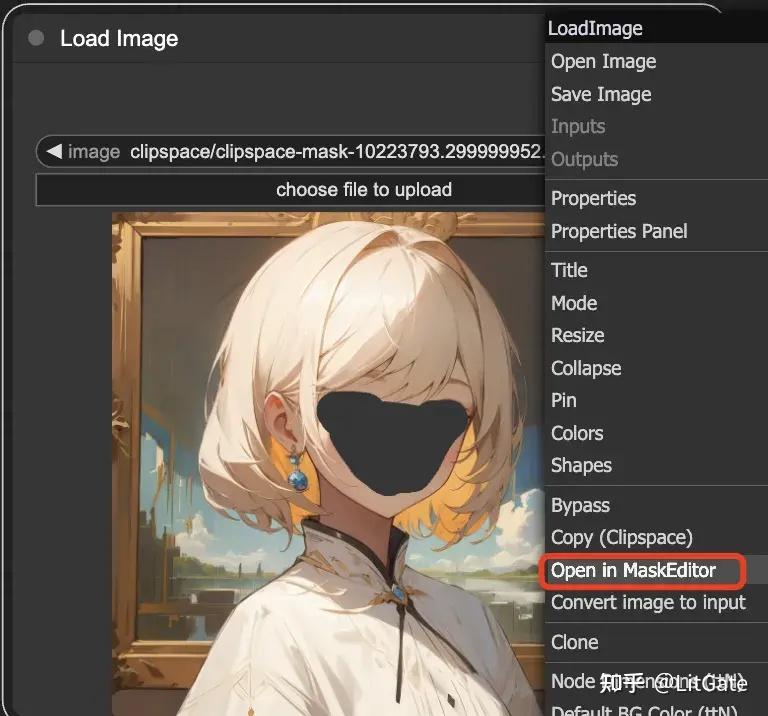
在Load Image节点中导入图片后,右键选择Open in MaskEditor即可涂抹重绘部分。
2.效果展示



Stable Video Diffusion(只能通过ComfyUI进行使用)
一.核心参数
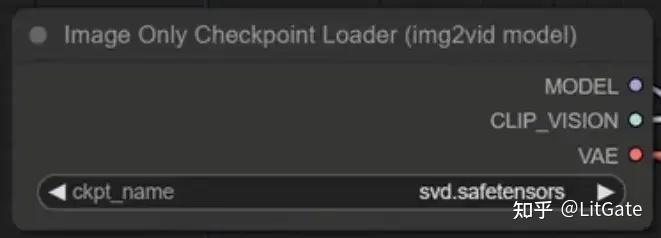
1.SVD模型下载,模型通过此节点调用,svd.safetensors可在 576×1024 分辨率下生成 14 帧运动片段,svd_image_decoder.safetensors可在相同分辨率下生成 25 帧运动片段
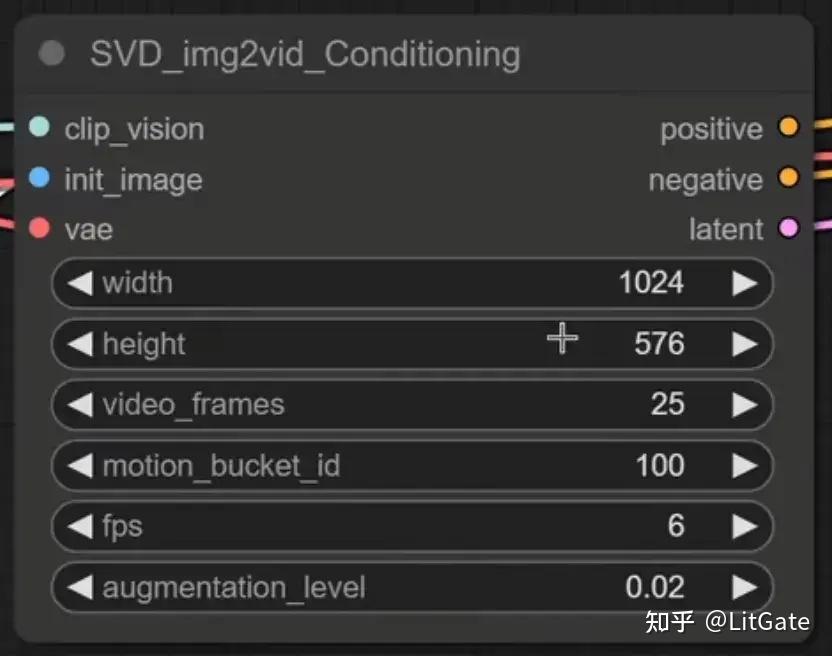
2.SVD img2vid Conditioning 节点
a.分辨率只可选择1024576或5761024,
b.video_frames: 要生成的视频顿数;
c.motion bucket id: 数字越大,视频中的运动越多;
d.fps: fps 越高,视频的断断续续就越少;
e.augmentation level: 添加到初始图像的噪声量,越高,视频看起来就越不像初
始图像。增加它以获得更多运动。
二.使用方法
1.文字转视频
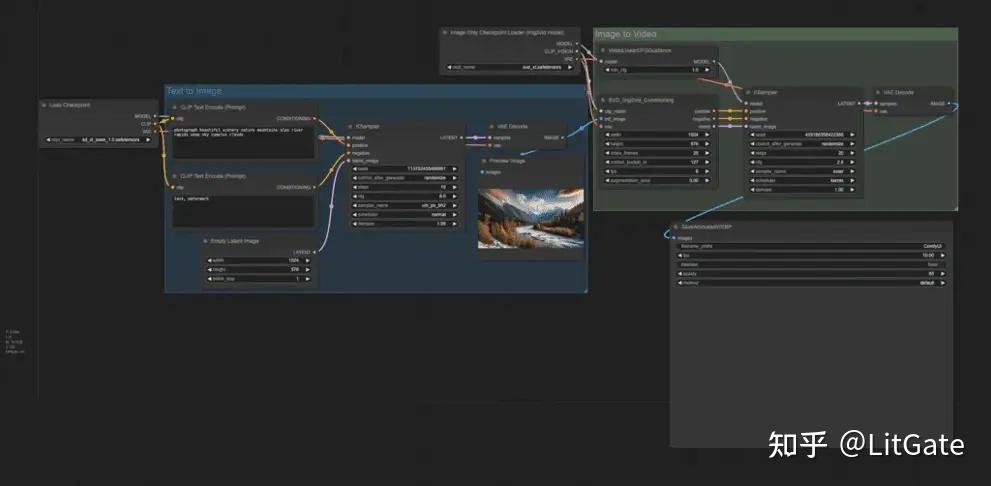

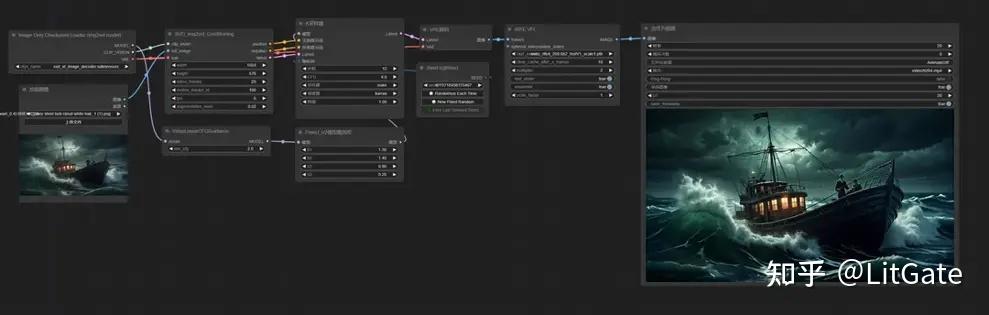
2.图片转视频


三.存在问题
- 时长很短,小于4s
- 分辨率限制
- 有时输出图像没有运动
- 模型无法通过文本进行控制
- 有时脸和身体的效果不友好
份完整版的comfyui整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

份完整版的comfyui整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 4492
4492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









