



在文生图 模式下虽然可以根据 prompt出效果很好的图,但也存在一些问题。利用图生图可对图片进行精准的调整,包括不限于换脸,换背景,修改画质,利用tile模型重新生成和放大图片等。

在文生图模式下虽然可以根据 prompt
出效果很好的图,但也存在一些问题,比如我们想要微调一些细节,就只能通过修改
prompt
来实现,但是这样的效果并不好;文生图的出图结果太随机;没办法根据我们自己的图进行二次加工。我们通过深入学习图生图就可以很好的解决上述问题。本篇使用MJ生成摄影模特底图,再拿到SD的图生图进行二次修改。
MJ生成模特

绘图工具:Midjourney
提示词:
Beautiful Asian woman in dress surrounded by huge lotus leaves with
intricate patterns, standing in front of a huge full moon with soft light,
Albert Watson style, minimalism, elegant light green --ar 3:4 --s 750 --v
5.2 --style raw
中文:
美丽的亚洲女子身着连衣裙,周围环绕着巨大的荷叶,荷叶上有复杂的图案,站在一轮巨大的满月前,月光柔和,阿尔伯特-沃森风格,极简主义,优雅的浅绿色。
图生图简介
图生图和文生图的原理基本一样,文生图直接根据 prompt 描述来生成图片。而图生图则是在这个基础上添加图片的信息,图片+prompt
生成新的图。图生图主要的几个重点:重绘幅度、图生图下的TAG写法、缩放模式等。

1、图生图的2种打开方式
第一种是在文生图中将生成好的图直接发送到图生图中。第一种是在图生图界面中上传参考图。本文采用的是第二种方法。

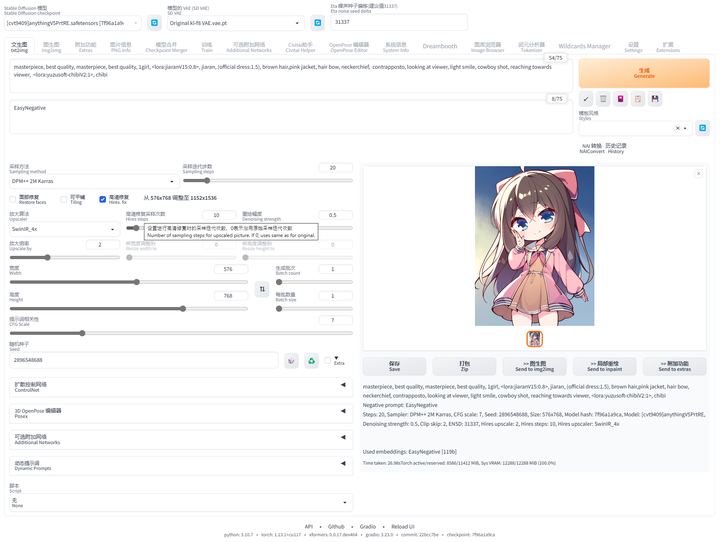
2、提示词写法
图生图正向提示词不用写太多人物描述的TAG,只要写一些画质的基础描述语即可。
模型:[写实]墨幽人造人_v1020 (写实模型都可以)
正向Prompt:masterpiece, best quality,1girl,(best quality), ((masterpiece)), (highres),beautiful face, extremely_beautiful_detailed_anime_face,反向 prompt:easynegative, paintings,
sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres,
normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin
blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers,bad
hand,naked,uncovered,(worst quality, low quality:1.4), (bad anatomy),
watermark, signature, text, logo,contact, (extra limbs),(3d), Six
fingers,Low quality fingers,monochrome,(((missing arms))),(((missing
legs))), (((extra arms))),(((extra legs))),less fingers.seed 种子:-1步数:30
3、重绘幅度
Denoising strength(重绘幅度)
就是来控制与原图一致性的程度。如果只是简单修改背景、换脸之类的就0.3-0.5.画质整体改变很大的话就0.7上下(跟底图没什么相似性了)

4、图像尺寸

5、缩放模式
Just resize、 Crop and resize、 Resize and fill 这三种模式会根据新尺寸选择是填充、拉伸还是裁剪。
1.拉伸
当我们调整了分辨率后导致和原图不一致,拉伸模式就会直接把图片拉大(不推荐)。
2.裁剪
如果设置的分辨率要小于原分辨率,裁剪就会将多余的剪掉。
3.填充
如果设置的分辨率要高于原图的分辨率,AI会帮助我们进行填充,而填充的内容则会依赖于重绘幅度,重绘幅度越高,AI自主发挥的空间越大。
6、模型选择
选择主模型:根据图片的画质,选择对应的大模型。(写实、二次元,2.5D等),主模型影响出图的风格。要写实就真人模型,要二次元就选择二次元模型。

7、 X/Y/Z 脚本控制
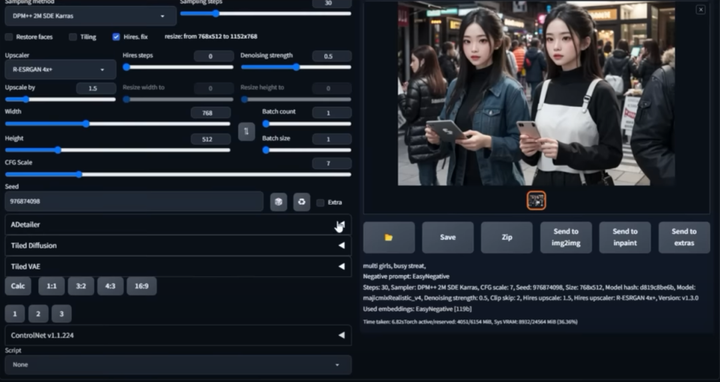
所以我们打开 X/Y/Z 图表脚本,设置重绘幅度范围(0-1),让 SD 一次性生成10张图

生成的图片



重绘幅度越高,那么生成出来的原图就与原图差别越大。搭配不同的模型+不同程度的重绘幅度生成不同效果的图片。
图生图中修改背景
图生图中输入prompt,提示词部分是告诉AI修正图片的地方。
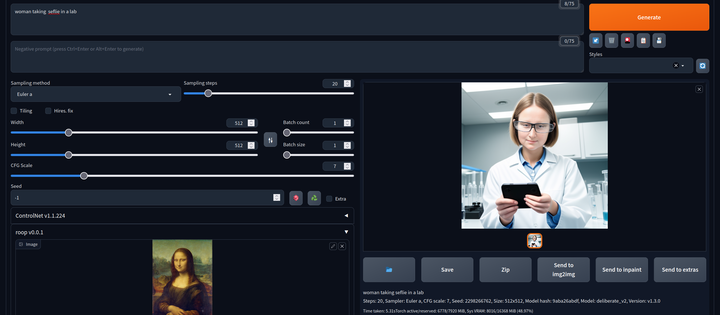
范例:下面的模特,我们想把背景换到校园里(在正向prompt 中加入 “背景是校园”)

正向 prompt:
* 1
* 2
photography,(8k uhd,RAW photo:1.2),(realistic,photo-realistic:1.37),(best quality:1.2),(masterpiece:1.5),The background is a college campus,(best quality:1.2),(masterpiece:1.5),The background is a college campus
* 1
生成的图片:

图生图到Extra放大
Extra主要是对图像进行优化放大的。可以上传图片导入,也可以通过其文生图和图生图中的send to extras直接使用;

放大算法 Upscaler :
图片选择4x-UltraSharp或R-ESRGAN 4x+
动漫选择:R-ESRGAN 4x+ Anime6B
缩放比率:选择2或4(根据自己所需)
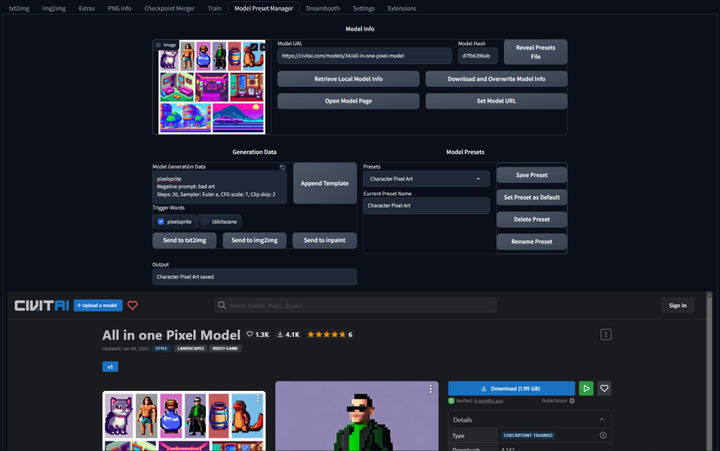
PNG Info 提取TAG
读取图片TAG(只有SD生成的原图才可以读取)


本文转自 https://mp.weixin.qq.com/s/_X6u08Nj5MsQAtXuNm00tQ,如有侵权,请联系删除。
g)
本文转自 https://mp.weixin.qq.com/s/_X6u08Nj5MsQAtXuNm00tQ,如有侵权,请联系删除。
这是一位SD资深大神整理的,100款Stable Diffusion超实用插件,涵盖目前几乎所有的,主流插件需求。
这份完整版的SD整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

全文超过4000字。
我把它们整理成更适合大家下载安装的【压缩包】,无需梯子,并根据具体的内容,拆解成一二级目录,以方便大家查阅使用。
单单排版就差不多花费1个小时。
希望能让大家在使用Stable Diffusion工具时,可以更好、更快的获得自己想要的答案,以上。
如果感觉有用,帮忙点个支持,谢谢了。
想要原版100款插件整合包的小伙伴,可以来点击下方插件直接免费获取
100款Stable Diffusion插件:
面部&手部修复插件:After Detailer
在我们出图的时候,最头疼的就是出的图哪有满意,就是手部经常崩坏。只要放到 ControlNet 里面再修复。
现在我们只需要在出图的时候启动 Adetailer 就可以很大程度上修复脸部和手部的崩坏问题
AI换脸插件:sd-webui-roop
换脸插件,只需要提供一张照片,就可以将一张脸替换到另一个人物上,这在娱乐和创作中非常受欢迎。
模型预设管理器:Model Preset Manager
这个插件可以轻松的创建、组织和共享模型预设。有了这个功能,就不再需要记住每个模型的最佳 cfg_scale、实现卡通或现实风格的特定触发词,或者为特定图像类型产生令人印象深刻的结果的设置!
现代主题:Lobe Theme
已经被赞爆的现代化 Web UI 主题。相比传统的 Web UI 体验性大大加强。
提示词自动补齐插件:Tag Complete
使用这个插件可以直接输入中文,调取对应的英文提示词。并且能够根据未写完的英文提示词提供补全选项,在键盘上按↓箭头选择,按 enter 键选中

提示词翻译插件:sd-webui-bilingual-localization
这个插件提供双语翻译功能,使得界面可以支持两种语言,对于双语用户来说是一个很有用的功能。
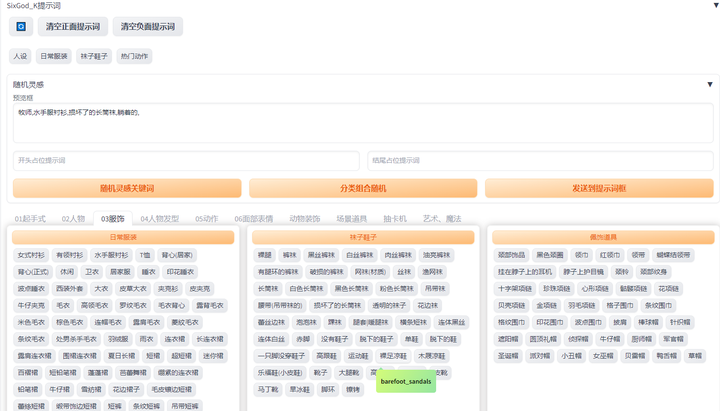
提示词库:sd-webui-oldsix-prompt
提供提示词功能,可能帮助用户更好地指导图像生成的方向。
上千个提示词,无需英文基础快速输入提示词,该词库还在不断更新。
以后再也不担心英文写出不卡住思路了!
这份完整版的SD整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1798
1798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









