








 本文深入解析冒泡排序算法,通过实例展示排序过程,探讨时间与空间复杂度,并提供Java实现代码。
本文深入解析冒泡排序算法,通过实例展示排序过程,探讨时间与空间复杂度,并提供Java实现代码。
排序是一个我们经常遇到的问题,这也是一个非常基本的问题,例如我们平时大小个站队?搜索数据之后的排序,常见的还是数字的排序等等(该图像素材来源于网络)

那么想象我们站队的时候是怎么排序的,来时看到谁最高就让谁站到第一位,然后再找第二高的,以此类推。我们看出高低也是互相比较得出的,计算机也可以使用这个方法,首先找到最高的,然后是第二高的,这种方法就是冒泡排序,因为他是按照大小一个一个的得到结果,就像是水泡浮出水面一样。
我们举一个简单的例子,
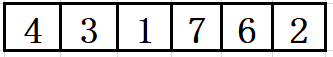
按照冒泡排序的原理,从第一位开始比较,4>3 所以换位置

然后是4和1比较,继续换位置

4<7 所以不用换位置 最大的变为7

7>6 所以接着往上冒泡

7>2 继续冒泡

至此达到了最大的数7,接下来还是从第一位开始寻找第二大的数。
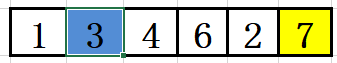



至此完成了第二个数的查找,我们知道冒泡算法的基本原理就是将最大的一点点浮到高的位置。每次仅挑选出来当前最大的数,6个数字循环五次就可以完全排序,因为最后两个数排序依次就可以变为有序。
这有一个动图(https://www.cnblogs.com/onepixel/articles/7674659.html)非常形象

算法分析:
1.需要两层循环 第一层固定当前最大的位置,第二层用于遍历剩下的元素,将大的一点点浮上来。
2.需要一个临时变量,用于交换两个元素。
实际代码:(实际例子就使用java写了,比较通用的写法,其他程序也差不多,推荐的在线网站https://tool.lu/coderunner/)
class Untitled {
public static void main(String[] args) {
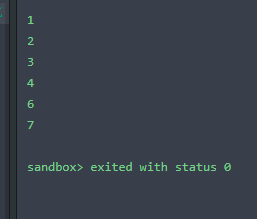
int[] array = new int[]{4,3,1,7,6,2}; //我们的需要排序的数组
int temp=0; //临时变量
//循环次数 只需要数组长度-1次就可以 因为两个数的时候只需要排序一次
//i变量用于定位 从数组的最后一位开始 存储当前最大的数
for(int i=array.length-1;i>0;i--)
{
for(int j=0;j<i;j++) //内层遍历从0到该位置的所有元素
{
if(array[j]>array[j+1]) //大于就交换 否则不变
{
temp = array[j+1];
array[j+1]=array[j];
array[j]=temp;
}
}
}
//输出显示排序后的 这种写法是java独有的 也可以正常遍历 或是使用数组转字符串方法
for(int ele:array)
{
System.out.println(ele);
}
}
}
那么第一个小问题来了,如果变为从大到小排序?
--》 将其中array[j]>array[j+1] 的大于号变为小于号即可。
第二个问题,我们使用了多少资源(CPU计算资源和内存资源)
--》我们开启了两次循环,循环的长度和数组长度成正比,指定的次数影响程序的完成时间(这里不会有异议吧)
--》我们创建了一个int变量,除了原始数组,额外占据空间4个字节
也就是说我们的排序算法,占据的资源是这么多,这是算法需要考虑的问题,因为在不同的场景可能要求速度和占用内存资源的大小,为此就出现了时间复杂度和空间复杂度。
这个问题和明天的另一个排序算法讲解的时候,单独对比说明一下。还有一点,我发现编程真的是需要自己写,想的好,可能写的时候就有各种问题。
注:
【时间复杂度不是执行需要的时间,而是根据输入的问题规模增加,完成所需要的时间效率,是一个对比的关系。
空间复杂度不是执行算法需要的空间,而是根据输入的问题规模增加,完成所需要的空间效率,是一个对比的关系
一般我们都是用“时间复杂度”来指运行时间的需求,是用“空间复杂度”指空间需求。】
例如 我们的这个问题输入的数组长度是n,那么循环的次数为为n-1次,内层循环次数:
n-1,n-2,......1 统计总的循环次数,用等差数列求和公式 n(n-1)/2 = (n²-n)/2 我们可以看到与问题规模的关系为n²关系(取多项式最高项,因为其影响是最大的)
所以该问题的时间复杂度就是O(n²);
由于无论增大问题的规模n,我们使用的内存空间都是1个int的大小,即4比特,与问题规模无关,即恒定的大小
所以该问题的空间复杂度为O(1);
具体的下次会讲,这里有一个概念就行。

















 3748
3748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









