



最近收到藏经阁群友私信,问能不能在最近发布的轮动策略当中加入持仓时间的限制条件,买入某个ETF后,必须持有够7天才可以卖出。
其目的有二,第一是想减少市场杂音,减少不必要的交易,第二就是如果场外操作的话,交易对应的ETF联接基金(直接在支F宝里面就可以买),持满7天,就可以省去赎回费,降低交易成本。

咱这里就直接开干了,不了解策略构建流程和细节的小伙伴可以看之前的两篇文章《手把手教你构建与改进轮动策略》和《换了量化平台,重新回测,还是十年10倍》,在原策略的基础上,加入了“持仓必须满7天才可以卖出”的条件,重新回测绩效如下,为了保持与原策略的可比性,回测时间范围和费率等设置皆与原策略一致。
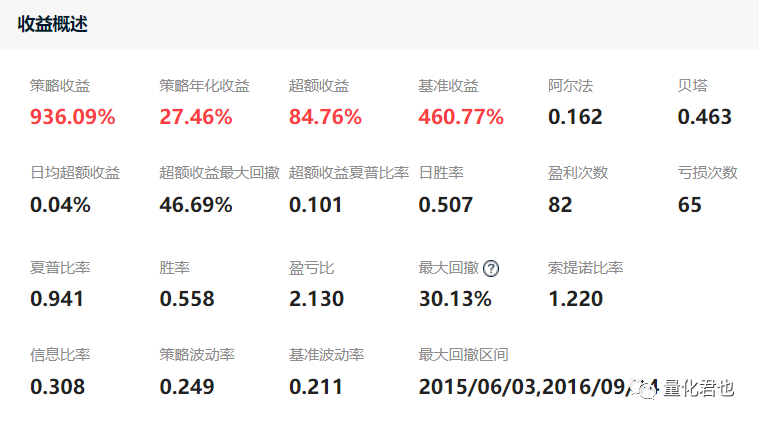

原策略的累计收益是1040.55%,年化收益率是28.74%,加入这个条件后,累计收益下降到了936.09%,对应的年化收益是27.46%,对比看出,按复利计算的年化收益每年少了1.3%。
所以啊,如果不介意持仓时间和交易次数的话,还是使用原策略为好,若是在这方面有限制和要求,加入新条件的轮动策略源码也已经分享,请原路径自取、改进和优化。
针对本次修改后的策略,我再啰嗦3个点,方便量化萌新操作。
第一点,类似这种加入“持仓时间限制”条件的策略,往往都会存在着“起始点陷阱”。结合这个策略来具体说明,在原策略当中,2013年9月13日是要将原来的创业板ETF卖出,然后轮动到红利ETF的,由于加了“持仓必须满7天”的条件,就还不能完成整个轮换动作,因为创业板ETF刚买入2天,必须再等5天之后才能卖出旧仓开新仓。
试想一下,假设有人是2013年9月3日开始运行这个新策略,他在2013年9月13日的持仓就是创业板ETF,而另外一个人恰好是在2013年9月13日开始运行,由于他之前没有持仓,他就可以丝滑买入红利ETF。这种由于策略运行起始时间点不同,而造成同一日期不同交易情况的现象,就叫做“起始点陷阱”。
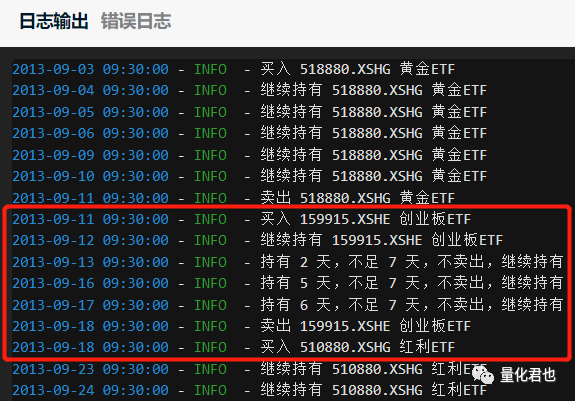
原策略回测的起始时间点是2013年9月3日,咱把新策略的起始时间点各往后挪1~6个交易日,再跑一遍回测。
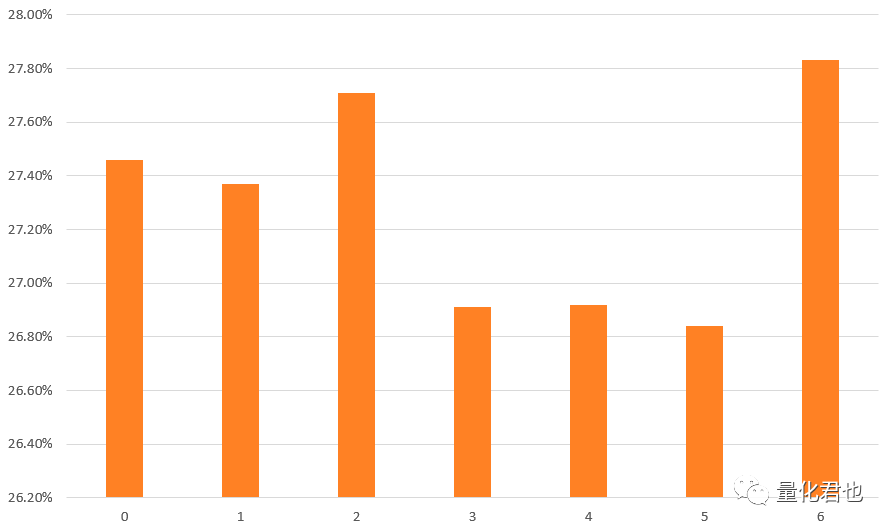
横轴对应的就是相对2013年9月3日往后挪多少个交易日,0表示还是2013年9月3日,1表示的就是2013年9月4日,以此类推。纵轴对应的是策略的年化收益率,其中最大值是27.83%,最小值是26.84%,相差大概1%,虽说起始点陷阱存在,但不算太严重,将来类似的情况留意着点儿就好。
第二点就是场外ETF联接基金的选取。一些小伙伴由于自身从业的限制等原因,没办法开设股票账户,进而玩不了场内ETF,只好退而求其次交易场外基金。
简单来说,ETF联接基金就是场外跟踪场内对应ETF的基金,联接基金的绝大部分资产都会用来购买场内的ETF,以达到跟踪的目的,在交易层面的最大区别就是,ETF可以在二级市场场内实时交易,成交价格是不断变化的,而联接基金只按照当天净值成交,在支F宝上就可以交易。
那如何快速找到场内ETF对应的联接基金呢?如何让跟踪误差最小呢?
教给大伙儿一个小技巧,以黄金ETF(518880)为例,在行情软件中输入ETF代码,就可以看到ETF的行情界面,接着按F10,就可以查看该ETF的详情,黄金ETF的简称是“华安黄金易ETF”,全称是“华安易富黄金交易型开放式证券投资基金”,基金管理人是“华安基金”,基金经理是“许之彦”。
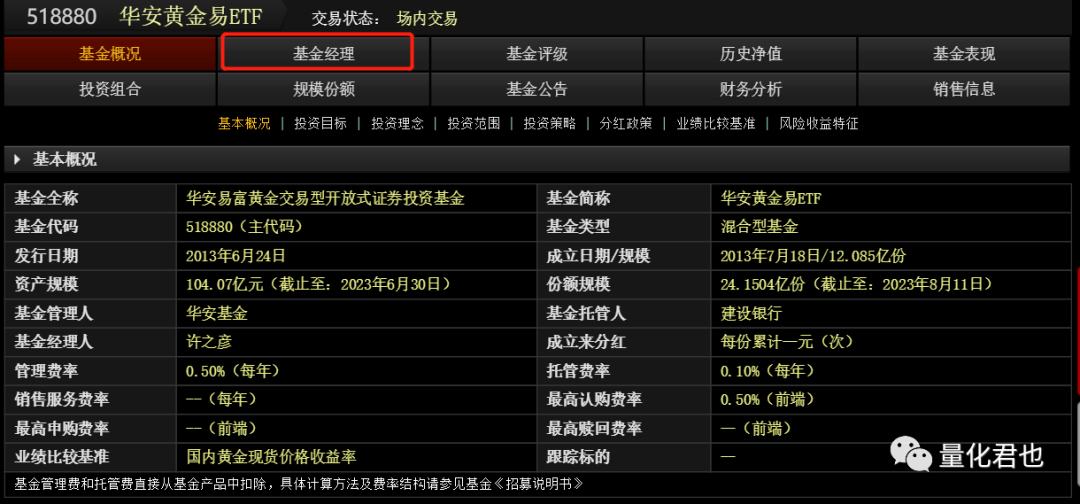
在F10界面中,点击【基金经理】选项卡,就可以看到该ETF的基金经理介绍,接着往下拉,就可以看到这个基金经理管理的所有基金产品,其中就大概率包括对应的ETF联接基金。
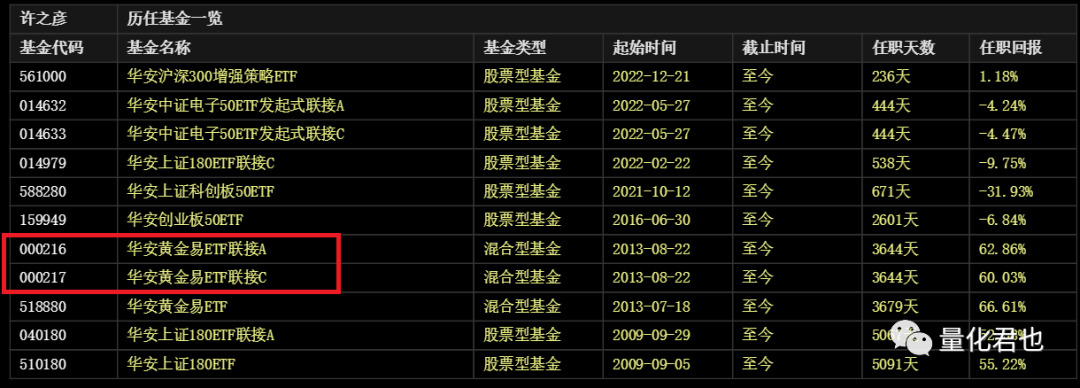
第三点就是关于是选择ETF联接基金中的A类还是C类。从上图可以看出,黄金ETF对应着有两个联接基金“华安黄金易ETF联接A”(002216)和“华安黄金易ETF联接C”(002217),那到底选哪一个呢?
简单来说,A类和C类都是同一个基金的不同份额类型,A类份额有申购赎回费,C类份额没有申购费,超过一定的持仓天数就可能免赎回费,如下所示。但C类份额并不是就没有交易费用了,只不过它的那些管理费、托管费、销售服务费等费用都是每天从资金资产中计提。
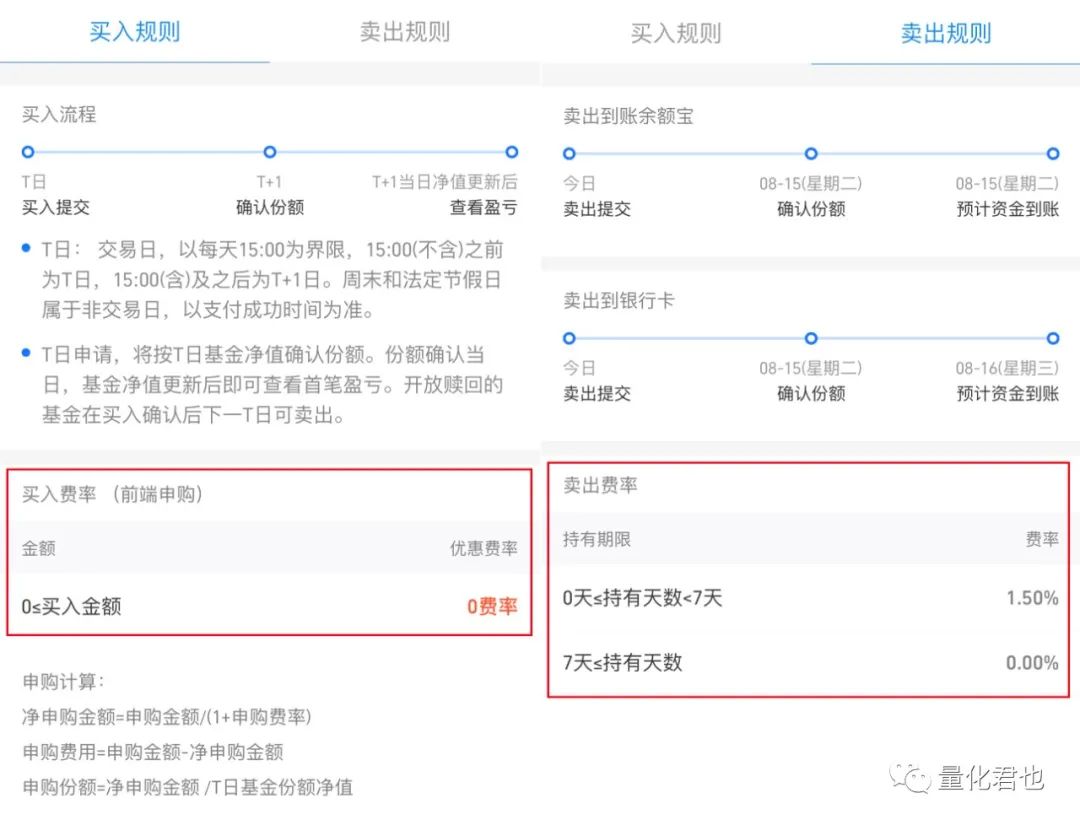
所以对于交易成本而言,交易A类份额是买入卖出时各剌一刀大的,C类份额则是每天小刀慢慢剌,一般来说,A类份额比较适合长期持有(如持有时间大于1年),C类份额更适合短期交易,大部分都是持有超过7天就免申购赎回费。因此,对于本策略的持仓周期而言,更适合交易对应ETF联接基金的C类份额,例如黄金ETF就应该买“华安黄金易ETF联接C”(002217)。
不如意事常八九,可与人言无二三,开发策略就是这样,满心欢喜地以为能改进策略取得长足进步,可到头来经常是失败居多,这也是宽客资历越老,心态越平和的原因。这些都只是策略优化改进中的一朵朵小浪花,放下执念,重新出发,乘风破浪,fighting~
PS:本文提及的所有证券标的和代码,仅为举例说明,不构成任何投资建议,望诸君明察。
原文首发链接:《唉~~量化策略越改越差了》

















 4779
4779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









