







 本文介绍了项目结构的详细划分,包括基础类方法的base包,页面元素的page包,以及利用configparse读取配置文件动态定位元素的模块。重点讲解了如何通过配置文件管理不同定位方式的元素操作,如XPath、CSS选择器等,并展示了如何封装FindElement和RegisterPage类。
本文介绍了项目结构的详细划分,包括基础类方法的base包,页面元素的page包,以及利用configparse读取配置文件动态定位元素的模块。重点讲解了如何通过配置文件管理不同定位方式的元素操作,如XPath、CSS选择器等,并展示了如何封装FindElement和RegisterPage类。
项目结构梳理

项目必须有自己的一个清晰的架构,自己才好找文件,而且思路也会理顺,现在就简单介绍一下整个项目的组成。
base包,基础类方法的存放地,比如redis_dao获取验证码,smtp发送邮件,随机生成电话号码,case运行器等。
page包,页面元素包,从配置文件读取页面元素信息。
handle包,page返回的元素进行操作。比如click,send_keys等等。
bussiness包,handle返回的操作进行排序等操作组成我们的测试用例业务逻辑。
config文件夹,存放配置文件,比如文件定位信息,数据驱动文件等等。
report测试报告存放的地方,这是是htmltestrunner生成的报告存放地。
image包,用例或者代码产生错误的时候进行截图处理。
testcase包,用例存放包
util包,读取配置文件
以上就是整体的一个项目结构。
初识configparse
这是一个读取文件用的第三方包,
解析数据分别为 键 = 值 这种形式.
上面是我们需要识别的类型的数据格式,因为我们都知道selenium定位方式不止一种,而且定位元素的信息在迭代过程中也会改变。
所以我这里采取去读配置文件的方法,就可以不用去动代码,而是修改配置文件即可。
在config路径下面创建LocateElement.ini文件

[节点] 括号内是节点信息,=两边分别为key和value
这个模块使用起来也非常简单。具体如下
import configparser
import os
# 因为其他文件肯定是要调用配置文件的没,所以我们把他封装成一个类命名read_ini.py
class ReadIni:
def __init__(self, file_path=None):
if file_path is None:
# 使用相对路径,保证代码可移植性
file_path = os.path.dirname(os.getcwd()) + "\\config\\LocateElement.ini"
# 实例化对象
self.config = configparser.ConfigParser()
# 读取文件,传入文件路径,编码格式
self.config.read(file_path, encoding='utf-8')
def get_config(self):
return self.config
def get_value(self, node, key):
"""
获取配置文件里面的xpath
:param key: 方式+定位信息
:param node: 节点位置
:return:
"""
try:
element_info = self.config.get(node, key)
return element_info
except configparser.NoOptionError:
print("<未找到node:{},key:{}的信息,请检查配置文件>".format(node, key))写好之后记得测试一下自己写的代码是否可用
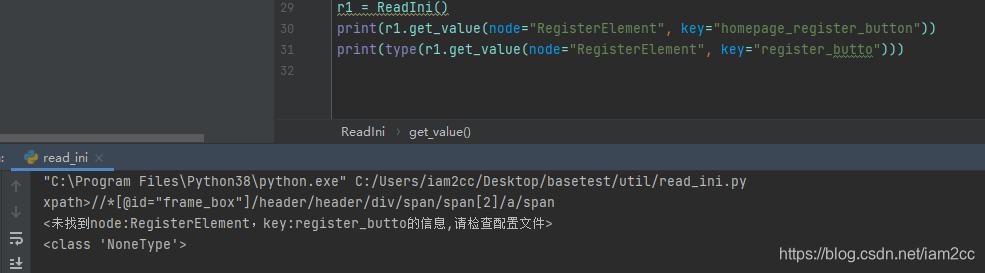
这里正反都有测试到,说明没问题。光拿到字符串
xpath>//*[@id="frame_box"]/header/header/div/span/span[2]/a/span
我们还要对他进行数据解析,熟悉的小伙伴们肯定想到了用split方法就可以解析了。下一步我们就开始封装findelement了。
在base包下面创建getelement.py
class GetElement:
def __init__(self, driver):
# 使用selenium的查找元素的方法肯定是需要用的dirver或者broswer,所以我们在初始化的时候,需
# 要传入
self.driver = driver然后下一步,解析字符串
from util.read_ini import ReadIni
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class GetElement:
def __init__(self, driver):
self.driver = driver
def get_element(self, node, key):
"""
获取元素对象,未定到的时候,返回None
:param node: node name
:param key: key name
:return: return element or None
"""
read_ini = ReadIni()
data = read_ini.get_value(node=node, key=key)
# 使用》分割字符串,xpath 和 后面的定位信息都分离出来了
res = data.split(">")
by, expression = res[0], res[1]
然后通过判断by,我们可以知道使用哪一种方式进行定位,expression则是这种定位方式的表达式;
然后在这里我比较推荐使用selenium.webdriber.support.wait 下面的 webdriverwait 的等待,因为页面js需要加载时间,如果使用正常定位方式,找不到元素会立马报错,使用了等待后我们等待一段时间,对页面进行持续查找。
from util.read_ini import ReadIni
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class GetElement:
def __init__(self, driver):
self.driver = driver
def get_element(self, node, key):
"""
获取元素对象,未定到的时候,返回None
:param node: node name
:param key: key name
:return: return element or None
"""
read_ini = ReadIni()
data = read_ini.get_value(node=node, key=key)
res = data.split(">")
by, expression = res[0], res[1]
try:
if by == 'xpath':
# 等待至多2秒,直到EC下面使用xpath定位的元素可见
element = WebDriverWait(self.driver, 2).until(EC.visibility_of_element_located((By.XPATH, expression)))
return element
elif by == 'css':
element = WebDriverWait(self.driver, 2).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, expression)))
return element
elif by == 'id':
element = WebDriverWait(self.driver, 2).until(
EC.visibility_of_element_located((By.ID, expression)))
return element
elif by == 'name':
element = WebDriverWait(self.driver, 2).until(
EC.visibility_of_element_located((By.NAME, expression)))
return element
elif by == 'class':
element = WebDriverWait(self.driver, 2).until(
EC.visibility_of_element_located((By.CLASS_NAME, expression)))
return element
else:
print("<查找元素失败误,by:{},请检查配置文件>".format(by))
return None
except Exception as e:
print(data, e)
return None
# 测试代码
# d = webdriver.Chrome()
# fd = FindElement(d)
# element = fd.get_element(node="RegisterElement", key="register_button")
接下来就是开始封装我们的page层。
page层的思路就是获取元素,然后把元素返给handle层进行操作。
一层只做一件事情所以page层就获取元素,返回元素即可,注册页面这样的node,我们可以去设置默认值,不用每次都去传参。
from base.find_element import FindElement
class RegisterPage:
def __init__(self, driver):
self.fe = FindElement(driver=driver)
def get_homepage_register_button_element(self):
element = self.fe.get_element(node="RegisterElement", key="homepage_register_button")
return element
def get_phone_num_element(self):
element = self.fe.get_element(node="RegisterElement", key="input_phone_num")
return element
def get_get_v_code_button_element(self):
element = self.fe.get_element(node="RegisterElement", key="get_v_code_button")
return element


















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









