







 本文介绍了ELK套件的使用。elasticsearch是近似实时搜索平台,有集群和节点概念,建议配置成集群模式;logstash可上传日志文件、采集其他服务器日志,还能利用插件处理日志;最后讲解了elk套件结合使用,用redis转发日志,在kibana搭建界面进行数据监控。
本文介绍了ELK套件的使用。elasticsearch是近似实时搜索平台,有集群和节点概念,建议配置成集群模式;logstash可上传日志文件、采集其他服务器日志,还能利用插件处理日志;最后讲解了elk套件结合使用,用redis转发日志,在kibana搭建界面进行数据监控。
**
elasticSearch
**
NRT
elasticsearch是一个近似实时的搜索平台,从索引文档到可搜索有些延迟,通常为1秒。
集群
集群就是一个或多个节点存储数据,其中一个节点为主节点,这个主节点是可以通过选举产生的,并提供跨节点的联合索引和搜索的功能。集群有一个唯一性标示的名字,默认是elasticsearch,集群名字很重要,每个节点是基于集群名字加入到其集群中的。因此,确保在不同环境中使用不同的集群名字。一个集群可以只有一个节点。强烈建议在配置elasticsearch时,配置成集群模式。
节点
节点就是一台单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能。像集群一样,节点也是通过名字来标识,默认是在节点启动时随机分配的字符名。当然啦,你可以自己定义。该名字也蛮重要的,在集群中用于识别服务器对应的节点。
节点可以通过指定集群名字来加入到集群中。默认情况下,每个节点被设置成加入到elasticsearch集群。如果启动了多个节点,假设能自动发现对方,他们将会自动组建一个名为 elasticsearch的集群。
索引
索引是有几分相似属性的一系列文档的集合。如nginx日志索引、syslog索引等等。索引是由名字标识,名字必须全部小写。这个名字用来进行索引、搜索、更新和删除文档的操作。
索引相对于关系型数据库的库。
类型
在一个索引中,可以定义一个或多个类型。类型是一个逻辑类别还是分区完全取决于你。通常情况下,一个类型被定于成具有一组共同字段的文档。如ttlsa运维生成时间所有的数据存入在一个单一的名为logstash-ttlsa的索引中,同时,定义了用户数据类型,帖子数据类型和评论类型。
类型相对于关系型数据库的表。
文档
文档是信息的基本单元,可以被索引的。文档是以JSON格式表现的。
在类型中,可以根据需求存储多个文档。
虽然一个文档在物理上位于一个索引,实际上一个文档必须在一个索引内被索引和分配一个类型。
文档相对于关系型数据库的列。
分片和副本
在实际情况下,索引存储的数据可能超过单个节点的硬件限制。如一个十亿文档需1TB空间可能不适合存储在单个节点的磁盘上,或者从单个节点搜索请求太慢了。为了解决这个问题,elasticsearch提供将索引分成多个分片的功能。当在创建索引时,可以定义想要分片的数量。每一个分片就是一个全功能的独立的索引,可以位于集群中任何节点上。
分片的两个最主要原因:
a、水平分割扩展,增大存储量
b、分布式并行跨分片操作,提高性能和吞吐量
分布式分片的机制和搜索请求的文档如何汇总完全是有elasticsearch控制的,这些对用户而言是透明的。
网络问题等等其它问题可以在任何时候不期而至,为了健壮性,强烈建议要有一个故障切换机制,无论何种故障以防止分片或者节点不可用。
为此,elasticsearch让我们将索引分片复制一份或多份,称之为分片副本或副本。
副本也有两个最主要原因:
高可用性,以应对分片或者节点故障。出于这个原因,分片副本要在不同的节点上。
提供性能,增大吞吐量,搜索可以并行在所有副本上执行。
总之,每一个索引可以被分成多个分片。索引也可以有0个或多个副本。复制后,每个索引都有主分片(母分片)和复制分片(复制于母分片)。分片和副本数量可以在每个索引被创建时定义。索引创建后,可以在任何时候动态的更改副本数量,但是,不能改变分片数。
默认情况下,elasticsearch为每个索引分片5个主分片和1个副本,这就意味着集群至少需要2个节点。索引将会有5个主分片和5个副本(1个完整副本),每个索引总共有10个分片。
每个elasticsearch分片是一个Lucene索引。一个单个Lucene索引有最大的文档数LUCENE-5843, 文档数限制为2147483519(MAX_VALUE – 128)。 可通过_cat/shards来监控分片大小。
安装软件
使用rpm包安装
yum install elasticsearch-2.3.3.rpm -y
需要jdk环境 同时安装jdk
yum install jdk-8u121-linux-x64.rpm
同时安装数据可视化rpm
elasticsearch-head-master.zip
[root@server1 elk]# /usr/share/elasticsearch/bin/plugin install file:/mnt/elk/elasticsearch-head-master.zip
-> Installing from file:/mnt/elk/elasticsearch-head-master.zip...
Trying file:/mnt/elk/elasticsearch-head-master.zip ...
Downloading .........DONE
Verifying file:/mnt/elk/elasticsearch-head-master.zip checksums if available ...
NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify)
Installed head into /usr/share/elasticsearch/plugins/head
##################################################
安装后配置文件
配置文件对格式要求较高 修改如下三个部分即可
# Use a descriptive name for your cluster:
#
cluster.name: my-es
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: server1
node.master: true (作为 master)
node.data: false(不存储数据) 在其他两台主机配置相反即可
node.enabled: false(不作为读服务) 在其他两台主机配置相反即可
~~~~~~~~~~~~~~~~~~~~~~~~`
# Lock the memory on startup:
#
bootstrap.mlockall: true
#
# Make sure that the `ES_HEAP_SIZE` environment variable is set to about half the memory
# available on the system and that the owner of the process is allowed to use this limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 172.25.15.6
#
# Set a custom port for HTTP:
#
http.port: 9200
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: ["server1", "server2","server3"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of nodes / 2 + 1):
#
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
不打开注释在默认发布目录
#path.data: /var/lib/elasticsearch
#
# Path to log files:
#
# path.logs: /var/log/elasticsearch
#
三台主机添加ip解析 浏览器打开master即可
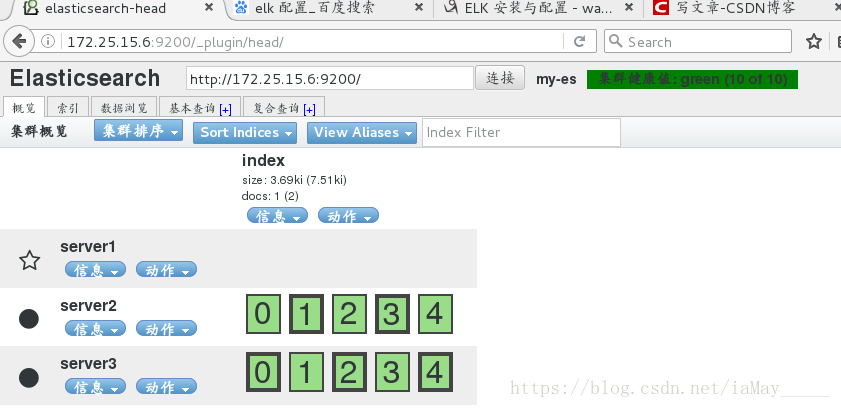
**
logstash
**
官方文档
https://www.elastic.co/guide/en/logstash/index.html
在此选择版本进行插件的学习使用
安装软件
[root@server1 elk]# yum install logstash-2.3.3-1.noarch.rpm
###########################################################################
开始测试
将logstash与elasticSearch结合使用
[root@server1 conf.d]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["172.25.15.6:9200"] } stdout{ codec => rubydebug } }'
Settings: Default pipeline workers: 1
Pipeline main started
test1
{
"message" => "test1",
"@version" => "1",
"@timestamp" => "2018-08-25T02:43:41.077Z",
"host" => "server1"
}
浏览器中查看数据
数据发送成功
但这样的输入方式不方便 所以将配置写在文件中 使程序自动加载读取配置
[root@server1 etc]# cd /etc/logstash/conf.d/
[root@server1 conf.d]# ls
[root@server1 conf.d]# vim es.conf
#######################################3
input { stdin { } }
output {
elasticsearch { hosts => ["172.25.15.6"] }
stdout { codec => rubydebug }
}
#########################################33
测试
[root@server1 conf.d]# /opt/logstash/bin/logstash -f es.conf
Settings: Default pipeline workers: 1
Pipeline main started
hello
{
"message" => "hello",
"@version" => "1",
"@timestamp" => "2018-08-25T03:02:08.672Z",
"host" => "server1"
}

1 上传日志文件
在conf.d目录下创建 log配置文件即可
##############################################################3
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["172.25.15.6"]
index => "system-%{+YYYY.MM.dd}"
}
}
#######################################################3
[root@server1 conf.d]# vim log.conf
[root@server1 conf.d]# /opt/logstash/bin/logstash -f log.conf
Settings: Default pipeline workers: 1
Pipeline main started
测试 浏览器查看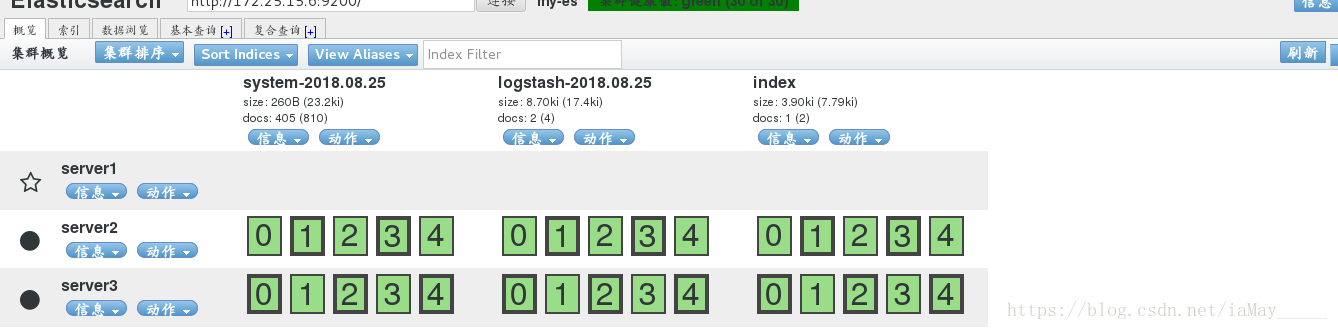
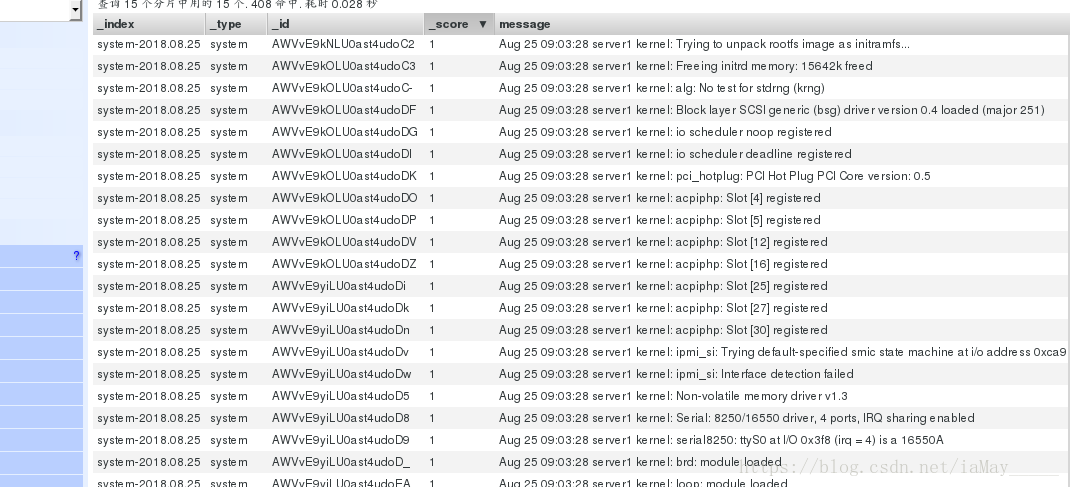
测试日志的上传
添加日志信息 查看是否有新的日志产生
[root@server1 ~]# logger asfdsdfsada
[root@server1 ~]# logger asfd
[root@server1 ~]# logger asfd
[root@server1 ~]# logger asfd
[root@server1 ~]# logger asfd
浏览器中查看
需要通过message搜索栏来查找添加的信息 如图 添加成功
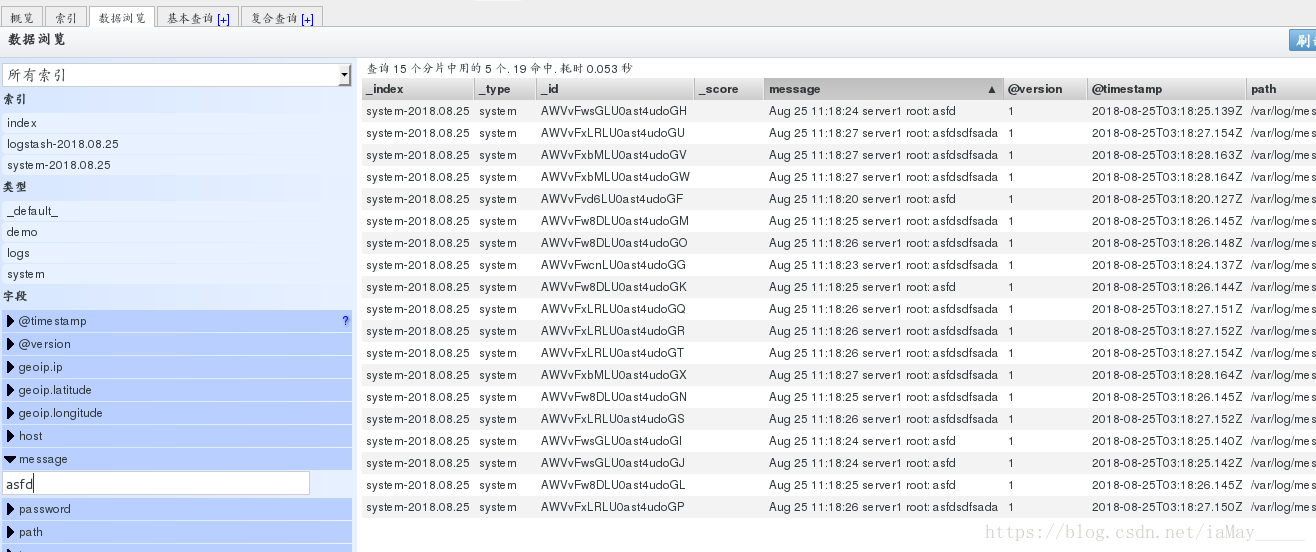
关于 配置文件中的begin 并不是每次都从日志的开始位置读取数据 而根据日志是否发生变化来读取数据 避免日志重复读取产生错误
这里在log配置文件中添加在shell显示的结果的代码 用以验证
[root@server1 ~]# cat /etc/logstash/conf.d/log.conf
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["172.25.15.6"]
index => "system-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
#####################################################################
测试
[root@server1 conf.d]# /opt/logstash/bin/logstash -f log.conf
Settings: Default pipeline workers: 1
Pipeline main started
{
"message" => "Aug 25 11:18:23 server1 root: asfdsdfsada",
"@version" => "1",
"@timestamp" => "2018-08-25T03:24:19.252Z",
"path" => "/var/log/messages",
"host" => "server1",
"type" => "system"
}
{
"message" => "Aug 25 11:18:24 server1 root: asfd",
"@version" => "1",
"@timestamp" => "2018-08-25T03:24:20.972Z",
"path" => "/var/log/messages",
"host" => "server1",
"type" => "system"
}
数据自动添加 但并没有从开始的位置添加
根据如下方式判定
[root@server1 ~]# cat .sincedb_452905a167cf4509fd08acb964fdb20c
913943 0 64768 33380
第一个为inode号 日志是否变更时根据 最后一个数字来确定
###################################################
在没有发生变更时 不重新读取数据
[root@server1 conf.d]# /opt/logstash/bin/logstash -f log.conf
Settings: Default pipeline workers: 1
Pipeline main started
######################################################
添加新日志后 数字变更 所以由此重新读取数据
[root@server1 ~]# logger lelele
[root@server1 ~]# cat .sincedb_452905a167cf4509fd08acb964fdb20c
913943 0 64768 33417
如下 所有新的数据都被读取到了
[root@server1 conf.d]# /opt/logstash/bin/logstash -f log.conf
Settings: Default pipeline workers: 1
Pipeline main started
{
"message" => "Aug 25 11:29:23 server1 root: lelele",
"@version" => "1",
"@timestamp" => "2018-08-25T03:30:10.018Z",
"path" => "/var/log/messages",
"host" => "server1",
"type" => "system"
}
{
"message" => "Aug 25 11:29:30 server1 root: lelelele",
"@version" => "1",
"@timestamp" => "2018-08-25T03:30:11.604Z",
"path" => "/var/log/messages",
"host" => "server1",
"type" => "system"
}
{
"message" => "Aug 25 11:29:45 server1 root: weafajd",
"@version" => "1",
"@timestamp" => "2018-08-25T03:30:11.605Z",
"path" => "/var/log/messages",
"host" => "server1",
"type" => "system"
}
#########################################################3
2 采集其他服务器的日志
添加新的配置文件即可
input {
syslog {
port => 514
}
}
output {
elasticsearch {
hosts => ["172.25.15.6"]
index => "system-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
###############################################################3
[root@server1 conf.d]# vim message.conf
[root@server1 conf.d]# /opt/logstash/bin/logstash -f message.conf
Settings: Default pipeline workers: 1
Pipeline main started
###########################################################
查看端口是否打开
[root@server1 ~]# netstat -antple|grep 514
tcp 0 0 :::514 :::* LISTEN 0 29813 3365/java
################################################################
发送日志端
修改日志配置文件
[root@server2 elk]# vim /etc/rsyslog.conf
#*.* @@remote-host:514
*.* @172.25.15.6:514
# ### end of the forwarding rule ###
##############################################################
测试
日志发送端产生新日志
[root@server2 elk]# /etc/init.d/rsyslog restart
Shutting down system logger: [ OK ]
Starting system logger: [ OK ]
[root@server2 elk]# logger westos
[root@server2 elk]# logger westos
日志收集端
[root@server1 conf.d]# /opt/logstash/bin/logstash -f message.conf
Settings: Default pipeline workers: 1
Pipeline main started
{
"message" => "imklog 5.8.10, log source = /proc/kmsg started.",
"@version" => "1",
"@timestamp" => "2018-08-25T03:42:23.000Z",
"host" => "172.25.15.7",
"priority" => 6,
"timestamp" => "Aug 25 11:42:23",
"logsource" => "server2",
"program" => "kernel",
"severity" => 6,
"facility" => 0,
"facility_label" => "kernel",
"severity_label" => "Informational"
}
3 利用filter插件对日志进行匹配统一操作
因为java日志中一条信息会分为多段 所以合并后输出保存更合适
编写配置文件
[root@server1 ~]# cat /etc/logstash/conf.d/my-es.conf
input {
file {
path => "/var/log/elasticsearch/my-es.log"
start_position => "beginning"
}
}
filter {
multiline {
pattern => "^\[" ####匹配语法
negate => "true" 匹配到再进行操作
what => "previous" 当匹配到后 和上一条合并
}
}
output {
elasticsearch {
hosts => ["172.25.15.6"]
index => "es-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
没有匹配过的日志格式为
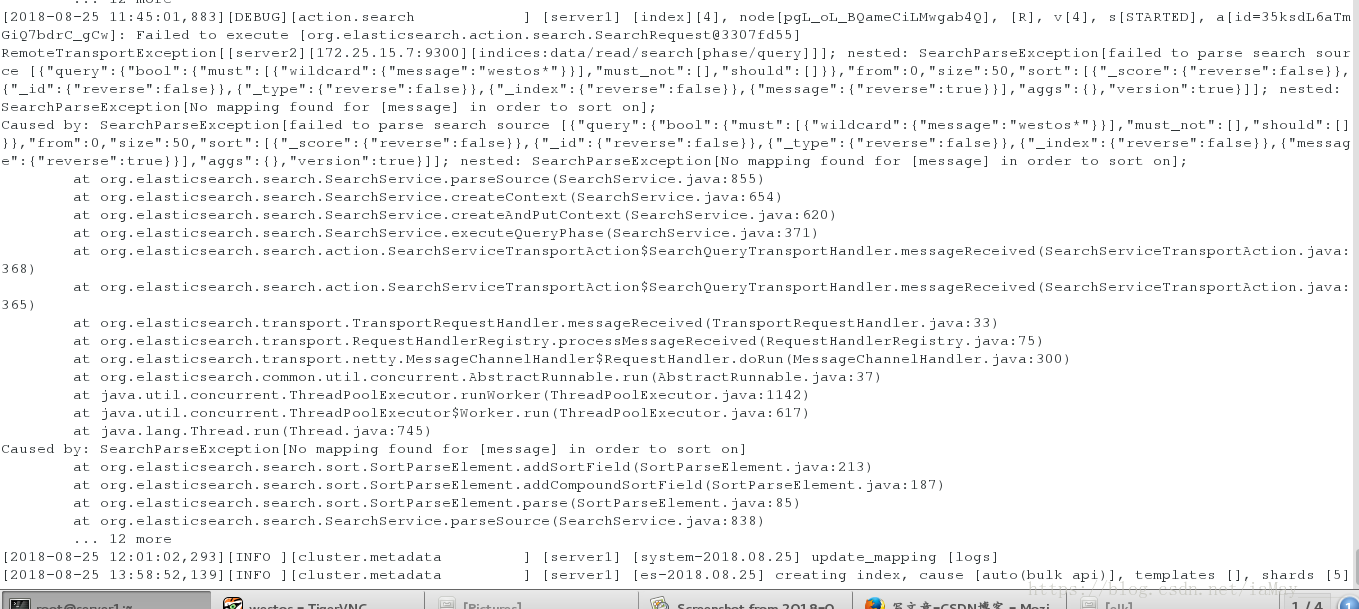
匹配后的格式为
[root@server1 conf.d]# /opt/logstash/bin/logstash -f my-es.conf

4 通过插件来对日志信息进行处理
编写配置文件
input {
file {
path => ["/var/log/httpd/access_log", "/var/log/httpd/error_log"]
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
elasticsearch {
hosts => ["172.25.15.6"]
index => "apache-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
#########################################################
grok 的match匹配在
[root@server1 patterns]# pwd
/opt/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns
查看grok即可 里面有各类服务的日志分割匹配模板
########################################################################
在对日志重新采集时 需要删除 .sin文件 有被采集日志的inode号确定即可
[root@server1 ~]# cat .sincedb_ef0edb00900aaa8dcb520b280cb2fb7d
918421 0 64768 650
[root@server1 ~]# ls -i /var/log/httpd/access_log
918421 /var/log/httpd/access_log
###################################################################
开启服务
成功
[root@server1 conf.d]# /opt/logstash/bin/logstash -f my-es.conf
Settings: Default pipeline workers: 1
Pipeline main started
{
"message" => "172.25.15.250 - - [25/Aug/2018:14:28:38 +0800] \"GET / HTTP/1.1\" 403 3985 \"-\" \"Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0\"",
"@version" => "1",
"@timestamp" => "2018-08-25T06:29:22.098Z",
"path" => "/var/log/httpd/access_log",
"host" => "server1",
"clientip" => "172.25.15.250",
"ident" => "-",
"auth" => "-",
"timestamp" => "25/Aug/2018:14:28:38 +0800",
"verb" => "GET",
"request" => "/",
"httpversion" => "1.1",
"response" => "403",
"bytes" => "3985",
"referrer" => "\"-\"",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0\""
**
elk套件结合使用
**
[root@server3 elk]# rpm -ivh kibana-4.5.1-1.x86_64.rpm
Preparing... ########################################### [100%]
1:kibana ########################################### [100%]
[root@server3 elk]# vim /opt/kibana/config/kibana.yml
#######################################################################
编辑配置文件
# The Elasticsearch instance to use for all your queries.
elasticsearch.url: "http://172.25.15.6:9200"
# preserve_elasticsearch_host true will send the hostname specified in `elasticsearch`. If you set it to false,
# then the host you use to connect to *this* Kibana instance will be sent.
# elasticsearch.preserveHost: true
# Kibana uses an index in Elasticsearch to store saved searches, visualizations
# and dashboards. It will create a new index if it doesn't already exist.
kibana.index: ".kibana"
#########################################################################
开启服务
使用5601端口
[root@server3 elk]# /etc/init.d/kibana start
kibana started
[root@server3 elk]# netstat -antple
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 0 8127 885/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 0 8334 963/master
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 497 32493 1561/node
一般将服务搭建与另一台主机
此处先不进入网页配置 等下统一配置—————————————————————————————————————
使用redis来作为中间日志数据的转发
搭建redis即可
18 yum install gcc -y
19 tar zxf redis-3.0.6.tar.gz
20 cd redis-3.0.
22 make
23 make install
24 netstat -antple
25 cd utils
27 ./install_server.sh
测试收集nginx的数据
关于如何收集nginx日志
nginx日志的配置:
logstash中grok的正则(添加在logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-xxx/patterns/grok-patterns文件中)为:
WZ ([^ ]*)
NGINXACCESS %{IP:remote_ip} \- \- \[%{HTTPDATE:timestamp}\] "%{WORD:method} %{WZ:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:status} %{NUMBER:bytes} %{QS:referer} %{QS:agent} %{QS:xforward}
###################################################################3
编辑配置文件
和apache类似 多了一个参数而已
[root@server1 ~]# cat /etc/logstash/conf.d/nginx.conf
input {
file {
path => "/var/log/nginx/access.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG} %{QS:x_forwarded_for}" }
}
}
output {
redis {
host => ["172.25.15.7"](指定搭建号的redis主机ip即可)
port => 6379
data_type => "list"
key => "logstash:redis"
}
stdout {
codec => rubydebug
}
}
################################################################
进行测试 在任意主机压测nginx即可
[root@server1 conf.d]# /opt/logstash/bin/logstash -f nginx.conf
Settings: Default pipeline workers: 1
Pipeline main started
{
"message" => "172.25.15.250 - - [25/Aug/2018:16:03:33 +0800] \"GET / HTTP/1.1\" 200 612 \"-\" \"curl/7.29.0\" \"-\"",
"@version" => "1",
"@timestamp" => "2018-08-25T08:22:09.446Z",
"path" => "/var/log/nginx/access.log",
"host" => "server1",
"clientip" => "172.25.15.250",
"ident" => "-",
"auth" => "-",
"timestamp" => "25/Aug/2018:16:03:33 +0800",
"verb" => "GET",
"request" => "/",
"httpversion" => "1.1",
"response" => "200",
"bytes" => "612",
"referrer" => "\"-\"",
"agent" => "\"curl/7.29.0\"",
"x_forwarded_for" => "\"-\""
}
配置成功
此处取消对elasticsearch的提交 提交通过redis的logstash进行配置redis主机的日志提交
input {
redis {
host => ["172.25.15.7"]
port => 6379
data_type => "list"
key => "logstash:redis"
}
}
output {
elasticsearch {
hosts => ["172.25.15.7"]
index => "nginx-%{+YYYY.MM.dd}"
}
}
这里不需要在shell看到反馈 直接在浏览器中查看即可
运行 测试
测试成功 可以在kibana中进行搭建
这是可以将两台主机中的服务转入后台运行
只需要将配置文件目录下的nginx保留 其他全部移除即可
注意 在将nginx端打入后 请求数据成功但redis端没有显示 通过查看日志
错误及解决方法如下
{:timestamp=>"2018-08-25T16:49:58.172000+0800", :message=>"failed to open /var/log/nginx/access.log: Permission denied - /var/log/nginx/access.log", :level=>:warn}
[root@server1 ~]# chmod 777 /var/log/nginx/access.log
再重启服务即可
[root@server1 conf.d]# /etc/init.d/logstash restart 即可开始配置
进入浏览器
点击setting 使kibana与elasticsearch建立链接
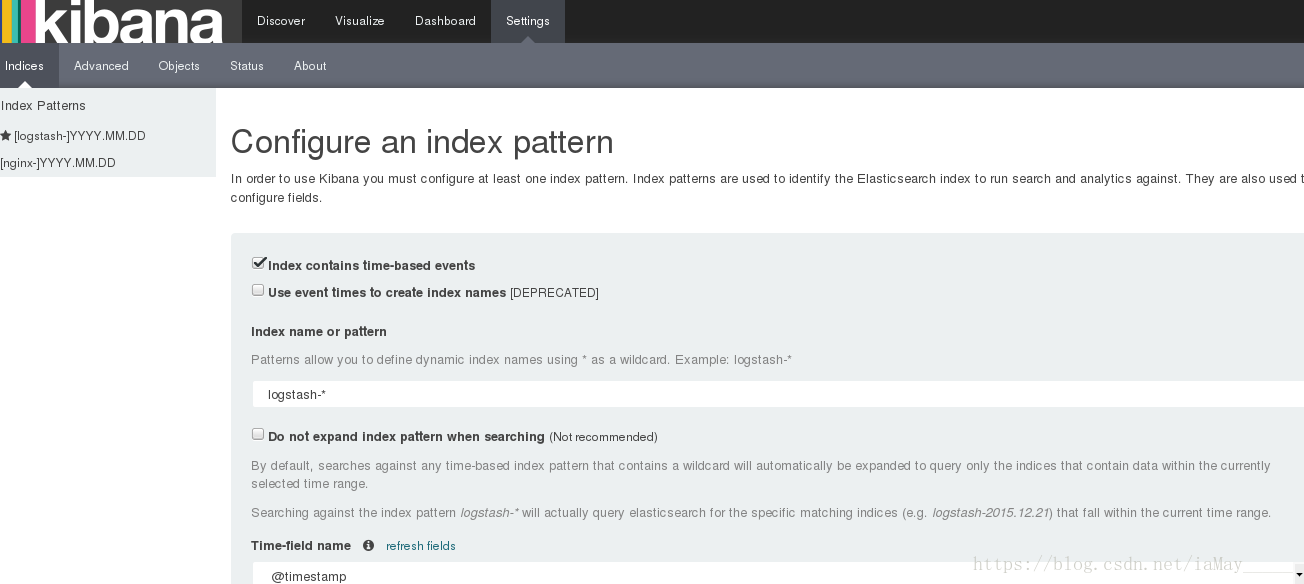

在这里将需要链接的项目名称写入即可 这里的名称有redis端的配置文件决定 可以修改

开始收集数据
点击dicover

在这里设置数据刷新时间与显示规定时间段的数据

出现数据即可
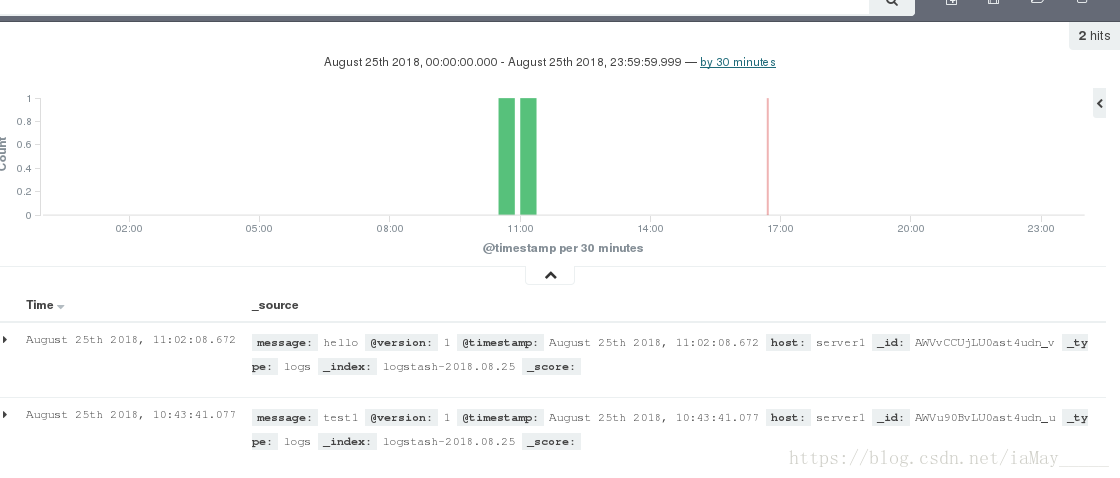
开始构建界面

在这里选择需要配置的监控项目或信息即可

添加一个信息窗口


添加访问量窗口

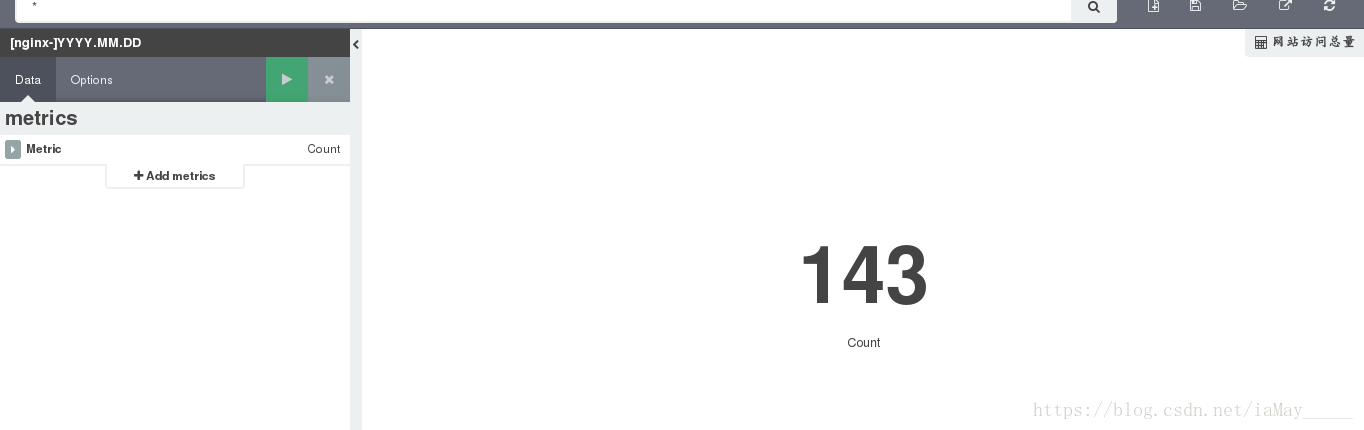
添加ip访问排行

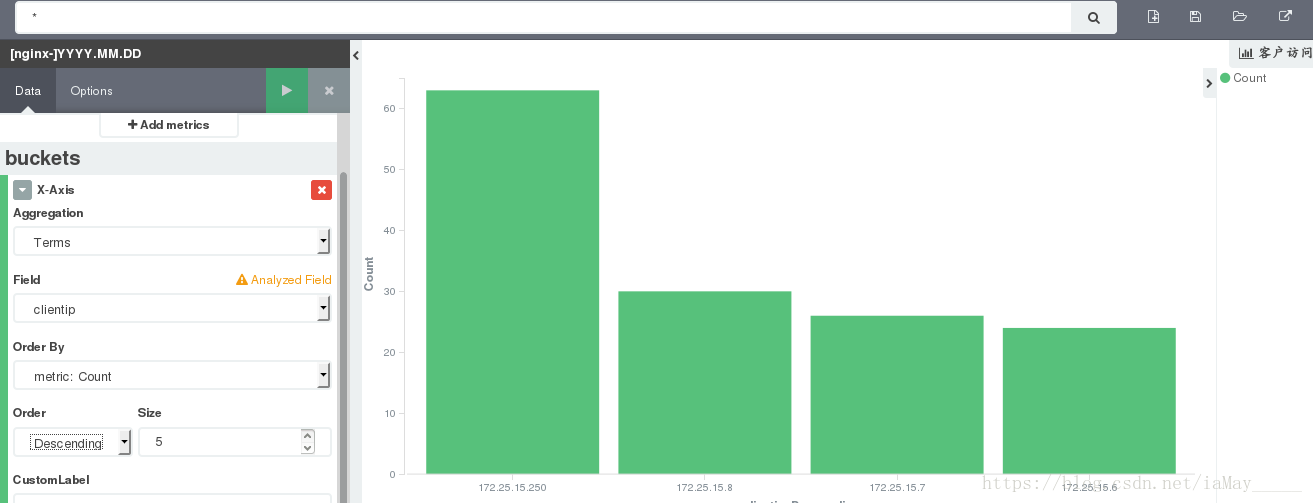
基本配置完成 结合搭建一个界面
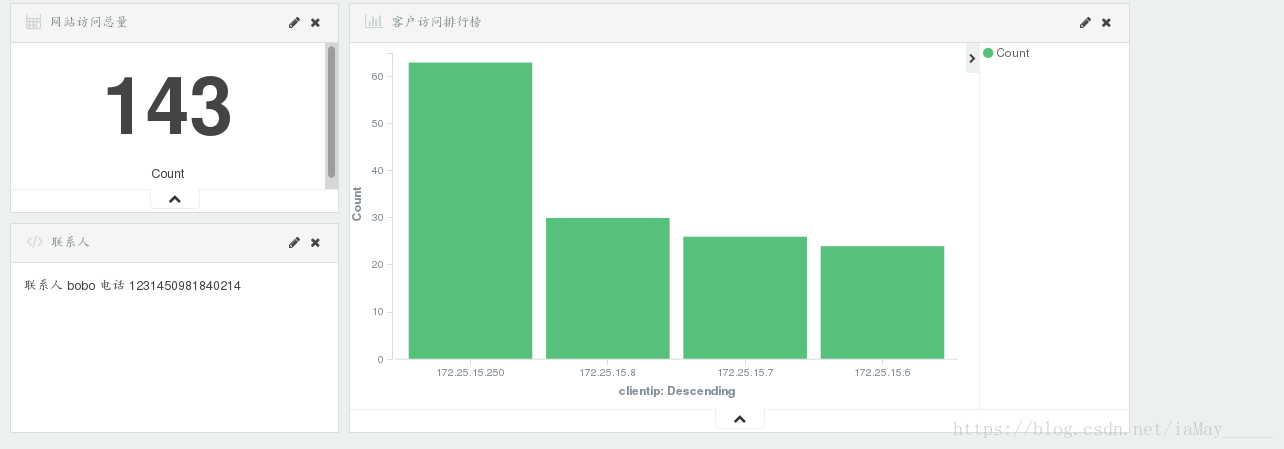
可以随意搭配

















 1540
1540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









