




说明
普遍社交软件上会有关注功能,如何知道自己的关注是否也是关注了自己呢?
需求
求关注结果数据中,相互关注的用户对。
数据如下:
follow表;from_user:关注用户,to_user:被关注用户,timestamp:关注时间。
| from_user | to_user | timestamp |
|---|---|---|
| A | B | 2022-11-28 12:12:12 |
| A | C | 2022-11-28 12:12:13 |
| A | D | 2022-11-28 12:12:14 |
| B | A | 2022-11-28 12:12:16 |
| B | E | 2022-11-28 12:12:16 |
| C | A | 2022-11-28 12:12:17 |
| D | A | 2022-11-28 12:12:18 |
分析
如果是互相关注,很容易想到表自关联,a.from_user 等于 b.to_user 且 a.to_user = b.from_user即可。具体sql如下:
select
a.from_user,
a.to_user
from follow a join follow b
on a.from_user = b.to_user
and a.to_user = b.from_user
这种方式确实可行,结果如下:
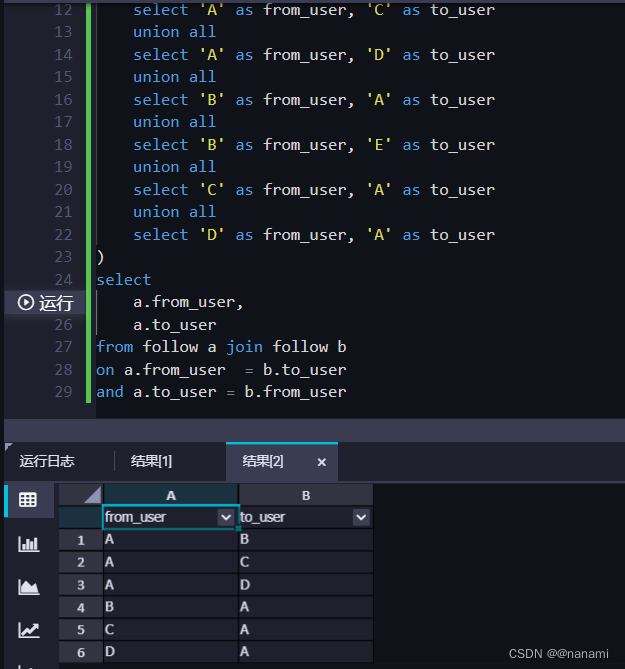
但是当数据量达到很大时候运行时相当慢的,有没优化的方法实现呢?看到这可以思考下如何优化!
优化
其实思路还是一样,知道是from_user 和 to_user正好两个用户互换字段而已。如果是互关用户 AB,在表中有如下数据:
| from_user | to_user |
|---|---|
| A | B |
| B | A |
如果在表中能将其中一条数据用户名互换位置,另一条不动,再按照这两个字段分组计算数据条数,组内数据条数是2的就是互关用户了。这个思路不涉及到join操作。
| from_user | to_user |
|---|---|
| A | B |
| A | B |
实现
有了上述优化思路,下面来实现下,如何将其中一条数据用户名互换位置呢,其实可以想到简单的一个真假逻辑判断就行了。如果一条满足逻辑则不变,另一条要确保一定不满足逻辑,交换位置即可,sql如下:
select
from_user,
to_user,
if(from_user > to_user, concat(from_user,to_user),concat(to_user,from_user)) as concat_users
from follw
上述sql的if()中,这两条数据一定是一个满足一个不满足。即将其中一条数据用户名交换位置,完整sql如下:
select
t1.from_user,
t1.to_user
from
(select
t.from_user,
t.to_user,
sum(1) over(partition by t.concat_users) as flag
from
(select
from_user,
to_user,
if(from_user > to_user, concat(from_user,to_user),concat(to_user,from_user)) as concat_users
from follw
) t
) t1
where t1.flag = 2
结果如下:
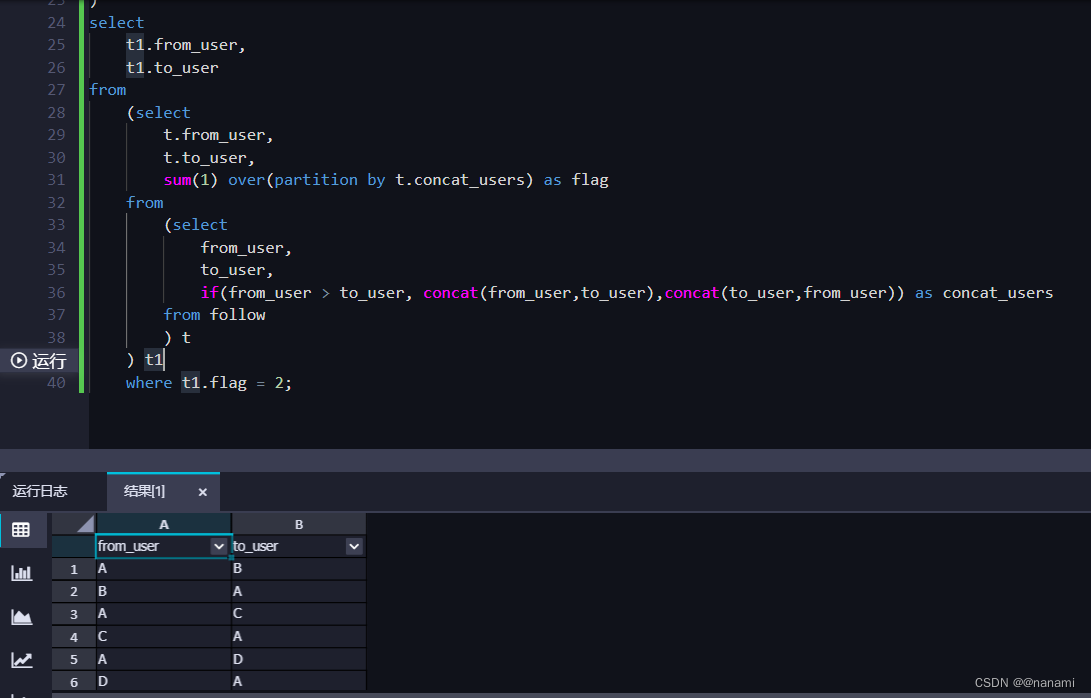
最后
喜欢的点赞、关注、收藏吧~ 感谢支持~~



















 1155
1155




 到【灌水乐园】发言
到【灌水乐园】发言









