




 本文详细介绍了两层神经网络的结构、前向传播与反向传播过程。从输入到全连接层、ReLU激活函数、再到softmax层,深入解析每个步骤的计算原理。通过链式法则和计算图理解BP算法,并给出了具体的梯度计算公式。最后,文章提及了参数调整的重要性,但未展开详细讨论。
本文详细介绍了两层神经网络的结构、前向传播与反向传播过程。从输入到全连接层、ReLU激活函数、再到softmax层,深入解析每个步骤的计算原理。通过链式法则和计算图理解BP算法,并给出了具体的梯度计算公式。最后,文章提及了参数调整的重要性,但未展开详细讨论。
two layer net 整体结构:
input - fully connected layer(W1,b1) - ReLU - fully connected layer (W2,b2)- softmax
Forward pass:
这里没有任何技术上的难点,就是写了文件中loss函数中scores和loss部分。
loss函数作用就是如果传入了y就返回loss和对所有w和b的梯度,这里在traning的时候调取。
如果没有传入y,就只返回scores,在predict的时候调用。
========forward pass 计算scores=======
y1=X@W1+b1.T#y1经过relu之后变成y2
x2=y1
x2[x2<=0]=0
scores=x2@W2+b2.T
=======forward pass 计算loss======
score=scores-np.max(scores,axis=1,keepdims=True)
exp_mat=np.exp(score)
p=exp_mat/np.sum(exp_mat,axis=1,keepdims=True)
loss=np.sum(-np.log(p[np.arange(N),y]))/N+reg * (np.sum(W2 * W2)+np.sum(W1*W1))
keepdims参数
在sum什么依维度操作的东西里面都有,目的就是保持维度,要不max出来就是一个(n,)的一维向量。
backward pass:
预备知识:
BP以及链式法则:
关于BP以及链式法则的东西,cs231n提供了两个PDF非常有用。
一个是derivations BP and vectorization,讲述了不同维度输入输出之间如何求导。
Derivatives, Backpropagation, and Vectorization
另一个是 BP for a linear layer,解决了一半全连接层的BP问题,基本可以解决所有神经网络的BP问题。
Backpropagation for a Linear Layer
这两个链接不翻墙也可以下。另外我也又写了一篇博文介绍这个。
computation graph:
当时自己做BP花了半下午。最后发现还是要老老实实画出 computation graph。这样结构清晰,还有画法按照cs231n上面的,把符号也算上。
下面是自己画的,稍微有点丑陋。
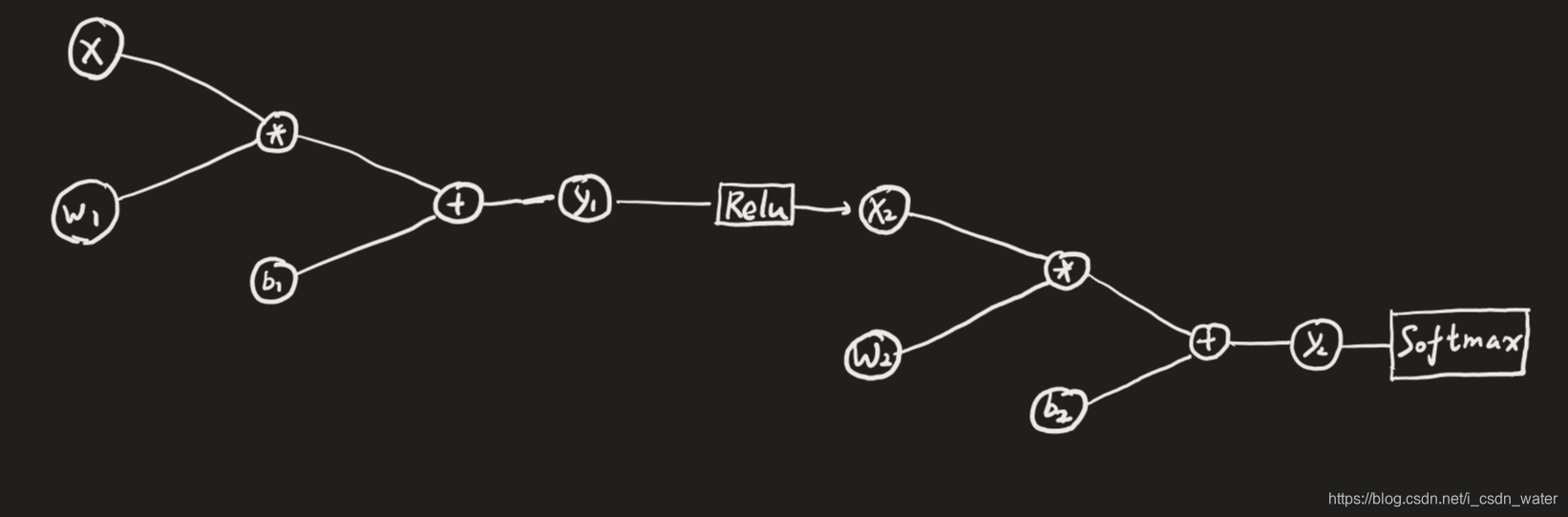
开始 BP:
W1: First layer weights; has shape (D, H)
b1: First layer biases; has shape (H,)
W2: Second layer weights; has shape (H, C)
b2: Second layer biases; has shape (C,)
顺着结构从后往前:
- d L d y 2 \frac{d L}{d y_2} dy2dL:(Softmax 层)
这个东西就是L对每个 y 2 y_2 y2求导,应该和 y 2 y_2 y2具有一样的shape。
其中 L = ∑ i = 1 n l o g ( ∑ k = 1 C e y i , k ) − y i , t r u e L=\sum^n_{i=1}log({\sum^C_{k=1}e^{y_i,k}})-y_{i,true} L=∑i=1nlog(∑k=1Ce
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2154
2154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









