







目录
博主用的是mysql8 DBMS,附上示例资料:
百度网盘链接: https://pan.baidu.com/s/1XaWi3Y7hpXbs_uHq2cPI6Q
提取码: fpnx
1、为什么要使用数据分组
(1)使用分组的场景
如果我想统计供应商为1001的产品均价,用where子句过滤就行了
-- 如果我想统计供应商为1001的产品均价,用where子句过滤就行了
SELECT AVG(prod_price)
FROM products
WHERE vend_id = 1001;但是我想统计所有供应商的产品均价呢,还要去一个一个写吗?
这时候就要用到分组了。使用分组可以将数据分为多个逻辑组,对每个组进行聚集计算。
(2)举例
先看上面的需求,作为一个例子:统计所有供应商的产品均价
SELECT vend_id, AVG(prod_price) AS avg_price, COUNT(*)
FROM products
GROUP BY vend_id; -- GROUP BY 子句指示 DBMS 分组数据,然后对每个组而不是整个结果集进行聚集。看了例子,再来深入理解一下分组的概念
(3)分组的相关概念
基本概念
当在 MySQL 中使用
GROUP BY子句进行分组后,数据会被组织成多个分组。每个分组就像是一个子数据集,它包含了符合分组条件的行。例如,假设有一个
students表,包含class_id(班级编号)、student_name(学生姓名)和score(成绩)列。如果按照class_id进行分组,那么所有class_id相同的行就会被划分到同一个组中。
数据结构细节
分组键(Grouping Keys):
- 分组是基于
GROUP BY子句中指定的列来进行的。这些列的值决定了如何划分数据。在上面的students表例子中,class_id就是分组键。每个不同的class_id值都会形成一个独立的分组。组内数据(Data within Groups):
- 每个分组包含了所有在
GROUP BY条件下具有相同分组键值的行。- 可以把每个分组想象成一个临时的小型数据集,这个数据集可以通过聚合函数(如
SUM、AVG、COUNT等)来处理组内的数据。比如,可以计算每个班级(每个分组)的学生平均成绩,即AVG(score)。结果集(Result Set):
- 经过分组后,最终返回的结果集是由每个分组的汇总信息组成的。如果使用了聚合函数,结果集中会包含每个分组的聚合结果。例如,在按照
class_id分组并计算平均成绩后,结果集可能会有两列:class_id和AVG(score),每一行对应一个班级及其平均成绩。- 结果集的行数等于分组的数量。使用聚集函数就是对分号的每一组的组内数据进行统计汇总
2、创建分组
SELECT vend_id, AVG(prod_price) AS avg_price, COUNT(*)
FROM products
GROUP BY vend_id; 通过上面的例子,可以知道分组是使用 SELECT 语句的 GROUP BY 子句建立的。
因为使用了 GROUP BY,就不必指定要计算和估值的每个组了。系统会自动完成。GROUP BY 子句指示 DBMS 分组数据,然后对每个组而不是整个结果集进行聚集。
在使用 GROUP BY 子句前,需要知道一些重要的规定。
- GROUP BY 子句可以包含任意数目的列,因而可以对分组进行嵌套,更细致地进行数据分组。
- 如果在 GROUP BY 子句中嵌套了分组,数据将在最后指定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY 子句中列出的每一列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在 SELECT 中使用表达式,则必须在 GROUP BY子句中指定相同的表达式。不能使用别名。
- 大多数 SQL 实现不允许 GROUP BY 列带有长度可变的数据类型(如文本或备注型字段)。
- 除聚集计算语句外,SELECT 语句中的每一列都必须在 GROUP BY 子句中给出。
- 如果分组列中包含具有 NULL 值的行,则 NULL 将作为一个分组返回。如果列中有多行 NULL 值,它们将分为一组。
- GROUP BY 子句必须出现在 WHERE 子句之后,ORDER BY 子句之前。
这里先不去关心嵌套分组,只需要知道这些分组是一个树形结构,嵌套相当于多了一层结点。
3、过滤分组--HAVING子句
除了能用 GROUP BY 分组数据外,SQL 还允许过滤分组,规定包括哪些分组,排除哪些分组。例如,你可能想要列出至少有两个订单的所有顾客。为此,必须基于完整的分组而不是个别的行进行过滤。
在这个例子中 WHERE 不能完成任务,因为 WHERE 过滤指定的是行而不是分组。事实上,WHERE 没有分组的概念。
那么,不使用 WHERE 使用什么呢?SQL 为此提供了另一个子句,就是HAVING 子句。HAVING 非常类似于 WHERE。事实上,目前为止所学过的所有类型的 WHERE 子句都可以用 HAVING 来替代。唯一的差别是,WHERE过滤行,而 HAVING 过滤分组。
提示:HAVING 支持所有 WHERE 操作符
我们学习了 WHERE 子句的条件(包括通配符条件和带多个操作符的子句)。学过的这些有关 WHERE 的所有技术和选项都适用于 HAVING。它们的句法是相同的,只是关键字有差别。
那么,怎么过滤分组呢?请看以下的例子:
-- HAVING过滤分组,WHERE过滤行
-- 过滤产品种类少于3的分组
SELECT vend_id, AVG(prod_price) AS avg_price
FROM products
GROUP BY vend_id
HAVING COUNT(prod_name) < 3说明:HAVING 和 WHERE 的差别
这里有另一种理解方法,WHERE 在数据分组前进行过滤,HAVING 在数据分组后进行过滤。这是一个重要的区别,WHERE 排除的行不包括在分组中。这可能会改变计算值,从而影响 HAVING 子句中基于这些值过滤掉的分组。
WHERE和HAVING一起使用:
-- WHERE和having的一起使用
-- 列出具有两个及以上产品且其价格大于等于 4 的供应商:
SELECT vend_id
FROM products
WHERE prod_price >= 4
GROUP BY vend_id
HAVING COUNT(prod_name) >= 2;
说明:使用 HAVING 和 WHERE
HAVING 与 WHERE 非常类似,如果不指定 GROUP BY,则大多数 DBMS会同等对待它们。不过,你自己要能区分这一点。使用 HAVING 时应该结合 GROUP BY 子句,而 WHERE 子句用于标准的行级过滤。
4、分组和排序
GROUP BY 和 ORDER BY 经常完成相同的工作,但它们非常不同,理解这一点很重要。
| ORDER BY | GROUP BY |
|---|---|
|
对产生的输出排序
|
对行分组,但输出可能不是分组的顺序
|
|
任意列都可以使用(甚至非选择的列也可以使用)
|
只可能使用选择列或表达式列,而且必须使用每个选择列表达式
|
| 不一定需要 | 如果与聚集函数一起使用列(或表达式),则必须使用 |
应该提供明确的 ORDER BY 子句,即使其效果等同于 GROUP BY 子句。
提示:不要忘记 ORDER BY
一般在使用 GROUP BY 子句时,应该也给出 ORDER BY 子句。这是保证数据正确排序的唯一方法。千万不要仅依赖 GROUP BY 排序数据。
检索包含三个或更多物品的订单号和订购物品的数目,要按订购物品的数目和订单号降序排序输出
-- 检索包含三个或更多物品的订单号和订购物品的数目
-- 要按订购物品的数目和订单号降序排序输出
SELECT order_num, COUNT(*) AS items
FROM orderitems
GROUP BY order_num
HAVING COUNT(order_item) >= 3
ORDER BY items DESC, 1 DESC;
5、SELECT语句顺序
下面回顾一下 SELECT 语句中子句的顺序。在使用SELECT 语句时必须遵循的次序,列出迄今为止所学过的子句。
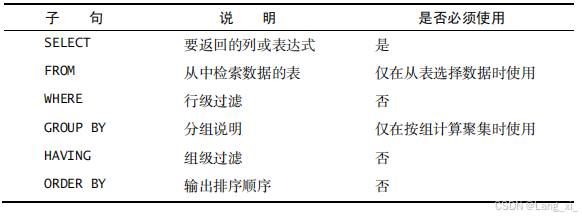
6、小结
- 先明白为什么我们要进行分组
- 分组的构成包括分组键和组内数据,嵌套的分组结构可以看成树形结构
- 进行分组操作的是GROUP BY子句,分组后使用聚集函数会对各分组分别进行汇总
- 对分组进行过滤的是HAVING子句,WHERE子句是对普通的行进行过滤
- 如果需要有顺序的数据,务必在最后使用ORDER BY子句,SQL语句不会保证输出的是有顺序的
- 使用SELECT语句时,要注意其各子句使用的顺序



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









