




 论文提出了一种优化LSM-Tree的方法,通过key-value分离减少排序开销,并采用特定的GC策略减轻写放大问题。value存储在vlog中,搜索时先查LSM-Tree获取地址,再从vlog读取。GC仅在有效数据区间操作,提高效率。范围查找通过并行处理提升性能,但对资源消耗较大。写入时,数据缓存至一定量再一次性写入。
论文提出了一种优化LSM-Tree的方法,通过key-value分离减少排序开销,并采用特定的GC策略减轻写放大问题。value存储在vlog中,搜索时先查LSM-Tree获取地址,再从vlog读取。GC仅在有效数据区间操作,提高效率。范围查找通过并行处理提升性能,但对资源消耗较大。写入时,数据缓存至一定量再一次性写入。
在我看来本论文的主要贡献在于相对减轻了传统LSM compact所带来的写放大问题。其核心设计在于使key、value分离以及gc只保持有效数据
key、value分离
作者对于key、value分离策略的观察主要来自于排序是以往LSM性能消耗最大的地方,但是真正影响排序的与占用大储存的value没有什么关系,那么能不能将key和value分开储存,那么就可以仅仅只排序key了呢
具体作者是将key和value所在的地方储存到LSM tree,而value就储存到vlog文件中。那么每次搜索数据的时候就可以先搜索LSM tree找到value的地址,然后在vlog文件中找到对应的值。
当然这和传统LSM充分利用顺序读取不一样,这是作者基于SSD的随机读写性能已经比较强的情况下作出的适应性改进
此外作者为了防止key可能丢失,还在vlog中储存了value的key
gc保持有效数据
gc维护了一个有效数据的区间,无论是搜索还是释放空间都是在这个区间中进行的。这样就免去了合并、排序的大量消耗性能的过程,并且还不需要刻意取出所有有效的key,然后对比对应的value是不是在,不在就删除这种重量级的gc
大概过程是gc从区间找到有效的数据然后添加到空间尾部,最后更新区间范围,那么在这个区间之外的就是无效数据了。这样的过程也难怪叫做gc,确实和标记—整理十分类似
并且为了防止gc过程中突然crash,作者还确保新添加的有效值和更新的区间指针持久化后才真正释放空间
范围查找
范围查找我认为是这篇论文的弱点所在,作者虽然是通过充分利用SSD并行度来解决只能取key然后一次次查找value,最后得到一个范围结果
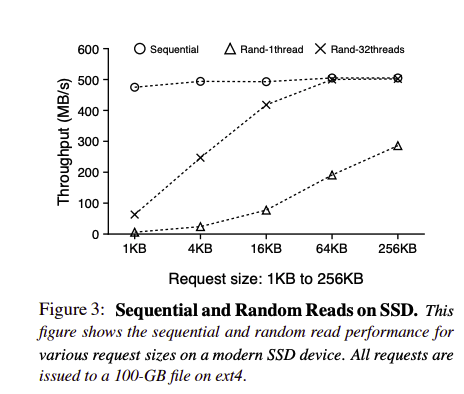
但是从图中仍然可知即使32线程在1kb请求大小的时候,性能仍然非常低。并且即使32线程取得了不弱于传统LSM范围读取的性能,那这样对于并行资源的消耗也是相当巨大的
写入
- 追加value到vlog
- 插入key以及value地址到LSM tree
作者还在这个写入过程做了一个优化,就是缓存要写入的数据直到到达阈值才一次写入
Ref
- https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf

















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









