 布隆过滤器原理与应用
布隆过滤器原理与应用





 本文详细介绍了布隆过滤器的工作原理,包括其在内存中声明Bit数组、通过多次hash确定元素位置的过程,以及如何判断元素可能存在于列表中。同时,文章探讨了布隆过滤器的特点,如存在误报但不会漏报,以及无法删除元素等问题,并讨论了如何通过增加hash次数和bit数组长度来提高准确性。最后,提到了布隆过滤器在防止缓存穿透、去重和幂等处理等场景的应用。
本文详细介绍了布隆过滤器的工作原理,包括其在内存中声明Bit数组、通过多次hash确定元素位置的过程,以及如何判断元素可能存在于列表中。同时,文章探讨了布隆过滤器的特点,如存在误报但不会漏报,以及无法删除元素等问题,并讨论了如何通过增加hash次数和bit数组长度来提高准确性。最后,提到了布隆过滤器在防止缓存穿透、去重和幂等处理等场景的应用。
目录
一、概述
简单讲布隆过滤器就是判断一个列表中是否存在某个元素。一般在JAVA判断是否存在,我们可以Map,Set等容器。但是当数据量特别大的时候,用Map和Set会占用过多的内存。这个时候就会考虑用布隆过滤器了。
二、详解
要创建一个布隆过滤器首选需要在内存中声明一个Bit数组,假设数组的长度为L,初始值全部为0。
当put一个key到布隆过滤器的时候,会对key进行N次hash,然后对hash值 % L 取模,得到N个位置下标。然后将Bit数组中对应位置的值全部设置为1。其中的L和N取决于key的预估总数和错误率,因为bloomfilter不能保证100%的准确,这个后面会说。
当判断一个key是否存在的时候也是对key进行N次hash取模,如果所有bit数组中所有位置的值都为1,则认为这个key有可能存在,注意这里说是有可能。
过程如下图:(这里假设L为10, N为3)
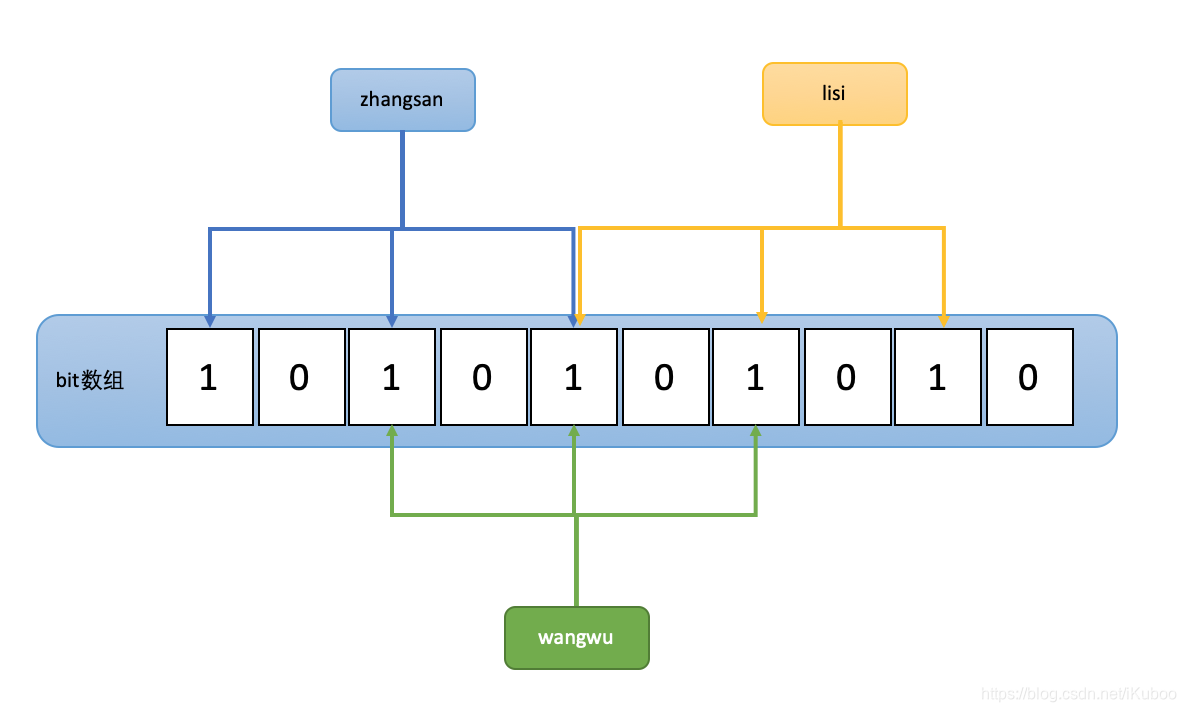
假设:
"zhangsan":3次hash取模的结果为:0,2,4。
"lisi":3次hash取模的结果为:4,6,8。
"wangwu":3次hash取模的结果为:2,4,6。
如果已经存在"zhangsan"和"lisi"这俩个key,那么即使"wangwu"这个key实际不存在,但是算法返回的结果是存在,因为2,4,6这个三个位置已经被“zhangsan”和“lisi”占用了。
综上所述发现bloomfiter有一些特点:
- 如果算法返回不存在,那刻个key肯定不存在。
- 如果算法返回存在,那只能说明有可能存在。
- bloomfiter中的key无法删除。因为bit位是复用的,删除会影响别的key。
那么怎么提升算法的准确度呢?
- 增加hash的次数(CPU和准确度的取舍)
- 增加bit数组的长度(内存和准确度的取舍)
三、实现
- 自己写java代码实现
package com.ikuboo.bloomfilter; import java.util.BitSet; /** * 布隆过滤器 */ public class MyBloomFilter { private int length; /** * bitset */ private BitSet bitSet; public MyBloomFilter(int length) { this.length = length; this.bitSet = new BitSet(length); } /** * 写入数据 */ public void put(String key) { int first = hashcode_1(key); int second = hashcode_2(key); int third = hashcode_3(key); bitSet.set(first % length); bitSet.set(second % length); bitSet.set(third % length); } /** * 判断数据是否存在 * * @param key * @return true:存在,false:不存在 */ public boolean exist(String key) { int first = hashcode_1(key); int second = hashcode_2(key); int third = hashcode_3(key); boolean firstIndex = bitSet.get(first % length); if (!firstIndex) { return false; } boolean secondIndex = bitSet.get(second % length); if (!secondIndex) { return false; } boolean thirdIndex = bitSet.get(third % length); if (!thirdIndex) { return false; } return true; } /** * hash 算法1 */ private int hashcode_1(String key) { int hash = 0; int i; for (i = 0; i < key.length(); ++i) { hash = 33 * hash + key.charAt(i); } return Math.abs(hash); } /** * hash 算法2 */ private int hashcode_2(String data) { final int p = 16777619; int hash = (int) 2166136261L; for (int i = 0; i < data.length(); i++) { hash = (hash ^ data.charAt(i)) * p; } hash += hash << 13; hash ^= hash >> 7; hash += hash << 3; hash ^= hash >> 17; hash += hash << 5; return Math.abs(hash); } /** * hash 算法3 */ private int hashcode_3(String key) { int hash, i; for (hash = 0, i = 0; i < key.length(); ++i) { hash += key.charAt(i); hash += (hash << 10); hash ^= (hash >> 6); } hash += (hash << 3); hash ^= (hash >> 11); hash += (hash << 15); return Math.abs(hash); } }测试代码
public class TestMyBloomFilter { public static void main(String[] args) { int capacity = 10000000; MyBloomFilter bloomFilters = new MyBloomFilter(capacity); bloomFilters.put("key1"); System.out.println("key1是否存在:" + bloomFilters.exist("key1")); System.out.println("key2是否存在:" + bloomFilters.exist("key2")); } } - guava类库实现
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; import java.nio.charset.Charset; public class TestGuavaBloomFilter { public static void main(String[] args) { //预估的容量 int capacity = 10000000; //期望的错误率 double fpp = 0.01; BloomFilter<String> bloomFilters = BloomFilter.create( Funnels.stringFunnel(Charset.forName("UTF-8")), capacity, fpp); bloomFilters.put("key1"); System.out.println("key1是否存在:" + bloomFilters.mightContain("key1")); System.out.println("key2是否存在:" + bloomFilters.mightContain("key2")); } } - 配合redis实现
- 可以自己写代码利用redis bitmap数据结构显示。可以参考guava里面的计算hash次数和hash的想相关代码,就guava里的BitArray替换为redis的bitmap即可。
- 可以用lua脚本实现。参考:https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
- 利用redis 4.0+提供的插件功能实现。参考:https://blog.youkuaiyun.com/u013030276/article/details/88350641
四、适用业务场景
- 防止缓存穿透
- 去重,幂等处理等流程

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









