









1. 即时编译器
在Java虚拟机当中,当虚拟机发现某个方法或代码块的运行特别频繁,就会把这些代码认定为**“热点代码”** ,为了提高热点代码的执行销量,在运行时,虚拟机回把这些代码殡仪为本地机器码,并以各种手段尽可能地进行代码优化,运行时完成这个任务的后端编译器被称为 即时编译器。
2. 获取编译信息的几个重要参数
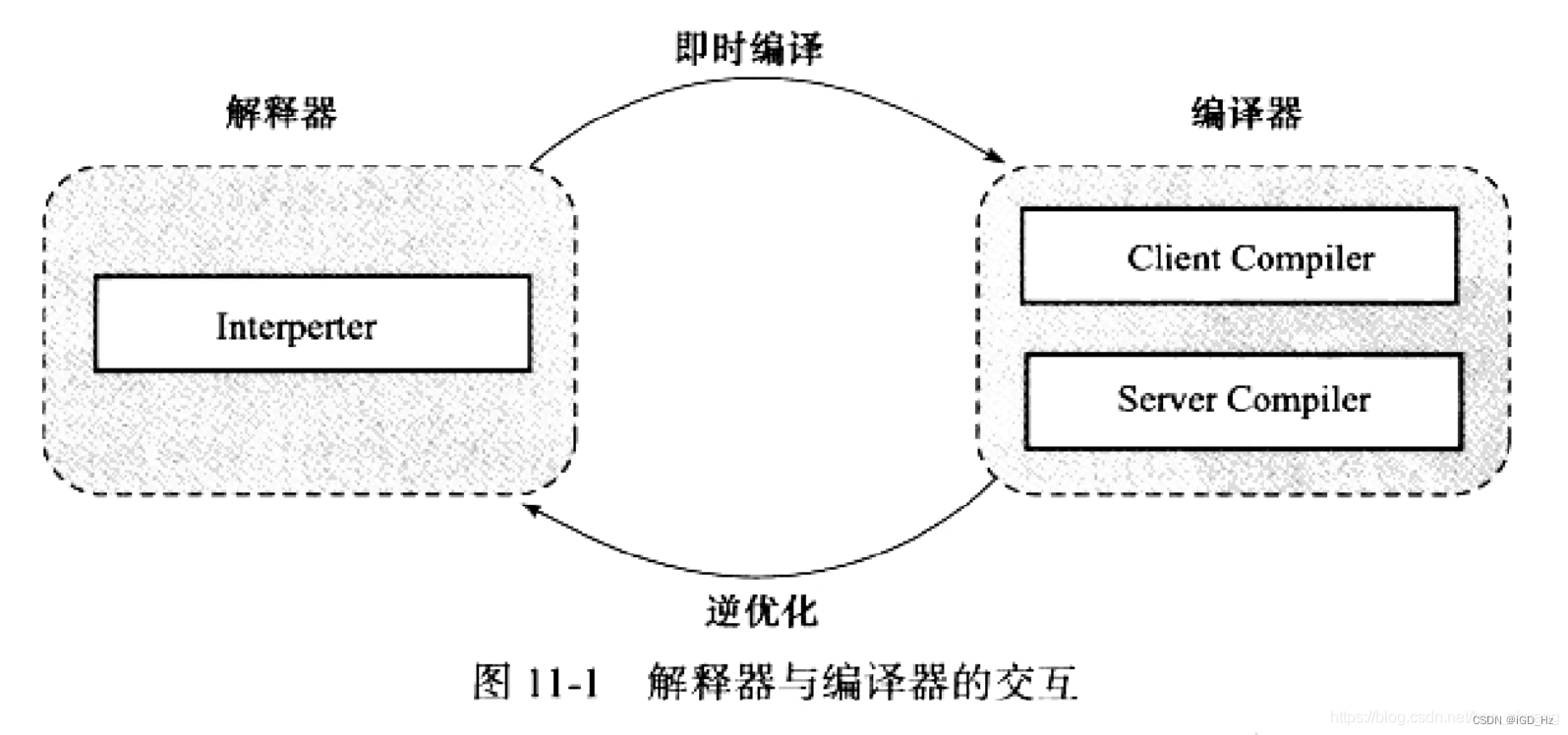
在了解一些重要的参数之前需要先了解一些编译器与解释器,尽管并不是所有的Java虚拟机都采用解释器和编译器并存的运行架构,但主流的Java虚拟机(如HotSpot、OpenJ9等)内部都包含了编译器和解释器。
当程序迅速启动和执行时,解释器可以首先发挥作用,省去编译的时间。
当程序启动后,随着时间的推移,编译器逐渐发挥作用,把代码转化为本地代码, 即转化为如下图的汇编代码,可以减少解释器的中间损耗,获得更高的执行效率。

注意,这里所说的编译器不是将java文件转化为class文件的Javac编译器(前端编译器),而是将常用的Java代码转化为本地机器码的即时编译器
更多参数可以参考java运行参数
| 参数 | 说明 |
|---|---|
| -XX:+UnlockDiagnosticVMOptions | 解锁用于 JVM 诊断的选项 |
| -XX:+PrintAssembly | 配合反汇编插件(hsdis)可以打印出字节码和本地方法的汇编码,需要开启-XX:+UnlockDiagnosticVMOptions支持 |
| -XX:CompileCommand=command,method[,option] | command可以设置为compileonly会从编译中排除非指定方法之外的所有方法,例如–XX:CompileCommand=compileonly,*cls.method 表示只获取cls类中method方法的汇编信息,其中\*表示通配符 |
| -Xint | 强制虚拟机加入 “解释模式” ,这时编译器完全不介入工作,全部代码使用解释方式执行 |
| -Xcomp | 强制虚拟机运行于 “编译模式”,这时候会优先采用编译方式执行程序,但是解释器仍然要在编译无法进行的情况下接入执行过程 |
| -XX:CompileThreshold=n | 但方法调用超过n时将对于方法转化为本地机器码(使用于使用基于计数器的热点检测的虚拟机,客户端模式默认为1500,服务器端默认为10000) |
| -XX:BackEdgeThreshold=n | 需要-XX:OnStackReplacePercentage开启 设置OSR比率为n(见下说明) |
| -XX:InterpreterProfilePercentage=n | 设置监控比率(服务端回边计数器使用) |
回边计数器阈值:
- 在客户端模式下,回边计数器的阈值为:方法调用计数器阈值(-XX:CompileThreshold)×OSR比率(-XX:OnStackReplacePercentage,默认值为933)/100
- 在服务端模式下,回边计数器的阈值为:方法调用计数器阈值(-XX:CompileThreshold)×(OSR比率(默认为140)-解释器监控比率(-XX:InterpreterProfilePercentage,默认为33))/100
3. 添加hsdis反汇编插件支持
相关知识点了解的差不多了,现在我们来运行下列程序测试一下,这里我是在使用Java18中还在孵化的Vector API来测试对应方法是否继续了矢量化运算,如果使用其他版本的jdk可以运行代码中的jdk8demo测试
public class VectorDemo {
final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
//默认为256bit
void jdk8demo(int[] a,int[] b, int[] c,int base){
for (int i = 0; i < 3; i++) {
c[i] = base*a[i]+b[i];
}
}
void vectorComputation(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
/*
SPECIES.loopBound的返回值满足以下条件:
1.返回值n为SPECIES位数(此样例中使用默认的256位)/类型所占字节数(float的4字节)
2.返回值n为满足条件1的最大值
比如这里SPECIES为256bit,表示可以同时处理256位的数据,而loopBound返回循环次数,
即假设我现在a,b,c的数组长度为4,因为SPECIES只有256位,最多同时处理256/32=8个浮点数
表示我一次循环可以处理8个浮点数,当不满足是不使用Vecctor API
*/
for (; i < upperBound; i += SPECIES.length()) {
// FloatVector va, vb, vc;
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(va)
.add(vb.mul(vb))
.neg();
vc.intoArray(c, i);
}
/*
这后面代码的目的在于处理余数部分数据,比如此样例中的数据,如果传入的数组长度
length%(256/8) != 0时,用来处理剩余的部分
*/
for (; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
public static void main(String[] args) {
VectorDemo demo = new VectorDemo();
demo.vectorComputation(new float[]{0.1f,0.2f},new float[]{0.1f,0.2f},new float[]{0.1f,0.2f});
}
}
下载需要下载hsdis反汇编插件来将获取汇编代码hsdis
根据自己系统版本下载对应插件
 注意这里存在的一个小问题,在网页中虽然说明了java查找hsdis插件的方式,但是你会发现每个路径都放了还是找不到,此时你需要在你的java目录中找到
注意这里存在的一个小问题,在网页中虽然说明了java查找hsdis插件的方式,但是你会发现每个路径都放了还是找不到,此时你需要在你的java目录中找到jvm.dll文件,并将下载的hsdis-<arch>.<extension>放到与它同个目录下。

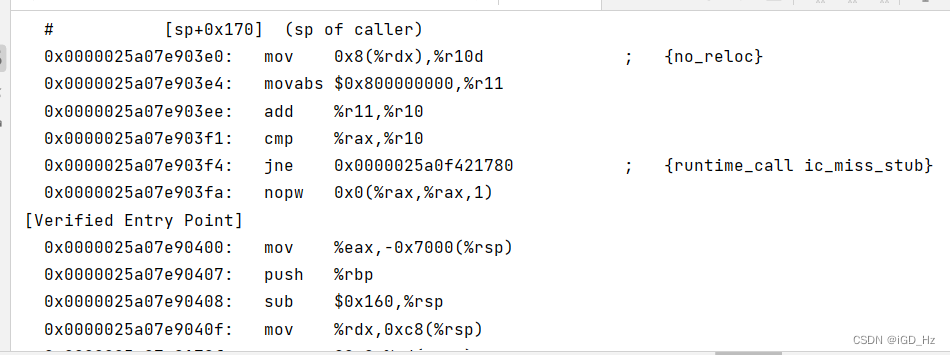
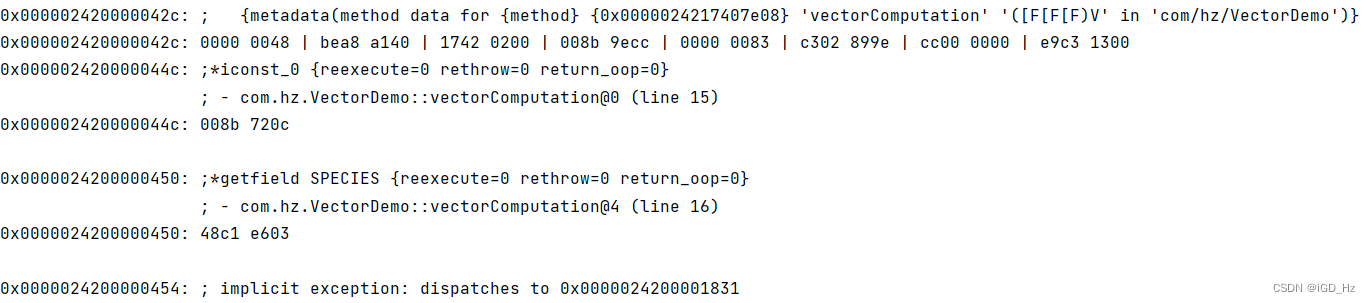
运行时添加VM option
-XX:+UnlockDiagnosticVMOptions -Xcomp -XX:+PrintAssembly -XX:CompileCommand=compileonly,*VectorDemo.vectorComputation
其中-Xcomp设置强制编译,-XX:CompileCommand设置指定编译类,不然输出的编译信息过多

最后会得到以下输出
常见问题解决
1.控制台没有输出
2.输出的数据中未转化未汇编代码

















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









