



EdgeCRNN:一种面向边缘计算的关键词检测声学特征增强模型
摘要
关键词检测(KWS)是自动语音识别(ASR)的一个重要分支,已广泛应用于边缘计算设备。KWS的目标是在降低内存、计算和延迟成本的同时,实现高准确率和低误报率(FAR)。然而,边缘计算设备的资源有限,给KWS应用带来了挑战。轻量级模型和深度学习结构在保持高效性能的同时,在KWS领域已取得了良好效果。本文提出了一种面向边缘计算设备的新型卷积循环神经网络(CRNN)架构,命名为EdgeCRNN。EdgeCRNN基于深度可分离卷积和残差结构,采用了一种特征增强方法。在Google语音命令数据集上的实验结果表明,EdgeCRNN在Raspberry Pi 3B+上每秒可处理11.1个音频数据,是Tpool2的2.2倍。与Tpool2相比,EdgeCRNN的准确率达到98.05%,其性能同样具有竞争力。
关键词 边缘计算 · 关键词检测 · 卷积循环神经网络 · 特征增强 · 轻量级结构
引言
关键词检测(KWS)是自动语音识别的一个分支,专注于从连续音频流中检测预定义的关键词。唤醒词是关键词检测在边缘计算设备上的关键应用,例如苹果的“嘿Siri”和谷歌的“OK谷歌”。当关键词识别系统在对话中检测到预定义的关键词时,设备将被唤醒以执行相应命令。
传统的关键词识别(KWS)方法通常使用关键词/填充隐马尔可夫模型(HMM)(Wilpon 等人 1991;Silaghi 和 Bourlard 1999;Silaghi 2005)。然而,由于依赖 HMM 拓扑结构,这些系统需要进行维特比解码,计算成本高。这些方法不适用于资源有限的边缘计算场景。
在关键词识别领域,深度神经网络(DNN)已被证明能够提供高效且可靠的解决方案。DNN(Chen 等人 2014)是首个应用于关键词识别的深度学习模型。其模型参数为 2.24 亿,小于高斯混合模型‐隐马尔可夫模型( GMM‐HMM)的 3.73 亿,且性能也优于 HMM 模型。然而,该模型的参数量和计算开销仍然相对较高,不适合边缘计算设备。
此外,关键词识别系统采用客户端‐服务器模式,其中客户端在终端收集并上传数据,由云服务器进行处理(图 1a)。当客户端接收到云服务器返回的结果后,将执行相关命令和操作。随着数据的快速增长,服务器的计算和存储压力将呈指数级增加,最终导致用户体验严重下降。此外,还存在用户隐私泄露问题,可能导致违法行为(Gaff 等人 2014;Custers 等人 2019)。因此,我们采用一种新模式,即客户端在终端本地收集并处理数据,如图 1b 所示。客户端无需将数据上传至云服务器。这种模式不仅减轻了云服务器和网络带宽的负担,保护了用户隐私,还能提供精准定位和高质量服务。
然而,模型对硬件的高要求以及资源的有限性给该模式在边缘计算设备中的应用带来了挑战。为此,人们采用了硬件加速和设计轻量级模型的方法来解决这一问题。硬件加速通过增加硬件来提供强大的计算能力。Benelli 等人(2018)使用神经计算棒(NCS)来提高速度,使模型延迟降低了 50%。Dinelli 等人 (2019)提出了一种基于现场可编程门阵列(FPGA)的卷积神经网络(CNN),其速度比 NCS 快近十倍。然而,这些基于 NCS 或 FPGA 的方法成本较高,难以在边缘计算设备中广泛应用。而设计轻量级模型的方法则可以通过设计或自动选择轻量级算法、结构或模型计算方法来降低计算成本和模型参数。因此,我们选择了设计轻量级模型的方法。换句话说,轻量级模型能够解决资源不足的问题,是一种面向边缘计算的模型。
各种轻量级深度学习架构已成功应用于关键词识别( KWS)问题,例如 Tpool2(Tang 等人 2018)和卷积神经网络(CNN)(Sainath 和 Parada 2015)。与深度神经网络(DNN)(Chen 等人 2014)相比,卷积神经网络(CNN)(Sainath 和 Parada 2015)在乘法运算和参数数量有限的情况下,误报率(FAR)相对降低了 27% 至 44%。然而,由于卷积核的大小限制,CNN 忽略了全局的时间和频谱相关性。循环神经网络 (RNN)能够利用更长的时间上下文,弥补了 CNN 的这一缺陷。近年来,RNN(Sun 等人 2016)和卷积循环神经网络(CRNN)(Arik 等人2017;Du 等人 2018; Zeng 和 Xiao 2019)被用于关键词识别。CRNN 是 CNN 和 RNN 的混合模型。在 CRNN 中,卷积层提取局部时间/空间相关性,循环层提取时间序列中的全局时间特征依赖关系。在 Talk-Type 数据集上,准确率达到 97.71%(Arik 等人 2017)。然而,CRNN 中的 CNN 模型(Arik 等人 2017)并未采用轻量级结构。
在本文中,我们设计了一种新的卷积循环神经网络模型,称为EdgeCRNN。其卷积神经网络部分采用基于深度可分离卷积和残差结构的EdgeCRNN模块。此外,我们在EdgeCRNN中提出了特征增强方法,使用LFBE-增量特征替代梅尔频率倒谱系数(MFCC)作为输入特征。LFBE-增量包含三个特征。EdgeCRNN通过在Google语音命令数据集(Warden 2018)上进行训练,能够识别 12类关键词。实验结果表明,EdgeCRNN不仅减少了模型参数和每秒浮点运算次数(FLOPs),还降低了延迟。测试用例可在边缘计算设备Raspberry Pi 3B+上正常运行,每秒可处理11.1个音频数据且无卡顿。此外,准确率也有所提升,达到了98.05%。
本文组织如下。第2节介绍轻量级关键词识别模型的相关工作。我们在第3节描述我们的方法和边缘卷积循环神经网络架构。在第4节中,我们解释实验步骤和结果。第5节给出结论。
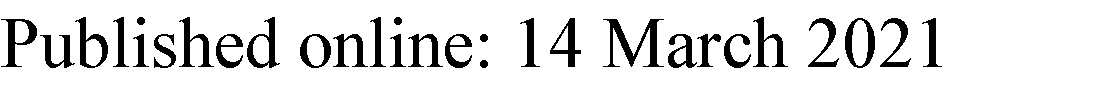
2 相关工作
设计轻量级关键词识别模型主要有三种方法:(1)模型压缩,(2)基于神经架构搜索(NAS)的自动神经网络架构设计,(3)人工设计轻量级神经网络。
模型压缩通过移除冗余层、权重量化高精度权重参数以及分解复杂操作,进一步减小模型尺寸。根据神经网络在不同方面的冗余性,模型压缩可分为权重量化、低秩分解和知识蒸馏(Nakkiran 等人 2015; Mishcheno 等人2019)。在(Tucker 等人 2016)中,George 等人将低秩权重矩阵和知识蒸馏应用于深度神经网络(DNN),实现了帧错误率相对降低 23.9%。时延神经网络(TDNN)(Sun 等人 2017)采用奇异值分解(SVD)降低模型复杂度,与深度神经网络(DNN)(Chen 等人 2014)相比,曲线下面积(AUC)降低了 37.6%。
神经架构搜索能够自动设计高性能的神经网络,目前已逐渐应用于计算机视觉(Howard 等人 2019)和语音识别(Tan 等人 2018)领域。它包含搜索空间、搜索策略和性能评估策略。基于搜索策略,NAS 能够在预定义的搜索空间中自动设计适用于特定应用的模型(Mazzawi 等人 2019;Anderson 等人 2020)。SANAS 能够根据任务难度在推理时动态地调整神经网络架构,并保持较高的识别水平(Véniat 等人 2019)。AUTOKWS 采用可微分神经结构搜索来寻找更有效的网络,达到了 97.2% 的 Top-1 准确率(Zhang 等人 2020)。
人工设计的轻量级神经网络主要通过优化卷积计算方法和设计更高效的卷积操作来减少计算量。轻量级结构主要包括深度残差结构(He 等人2016)、深度可分离卷积(Sifre 和 Mallat 2014)、空洞卷积( Coucke 等人 2019)和注意力机制(Luo 等人 2019)。DS-CNN(Zhang 等人 2017)是一种基于深度可分离卷积的轻量级模型,在有限的内存和计算能力下,其准确率达到 95.4%。在保持性能的同时,卷积神经网络(CNN)结合了残差学习和空洞卷积(Coucke 等人 2019;Tang 和 Lin 2018)。这些模型能够有效地反复提取语音特征,并降低模型的计算成本。准确率在论文(Tang 和 Lin 2018)中达到 95.8%。
模型压缩和自动设计方法都会消耗资源且耗时。人工设计轻量级神经网络需要设计人员具备专业知识,但其消耗的资源较少,技术也较为成熟。因此,我们采用人工设计神经网络的方法,为边缘计算设备设计一种轻量级关键词识别模型。
3 EdgeCRNN
在本节中,我们首先提出了两种特征增强方法。然后,基于EdgeCRNN模块设计了EdgeCRNN的架构。
3.1 特征增强
为了更高效地提取声学特征,我们提出了两种增强方法:输入特征增强和第一卷积层特征增强。表3显示,在添加特征增强后,准确率提高了3%。
3.1.1 输入特征增强
传统方法MFCC仅提取频谱上的包络信息,而丢失了声音细节。MFCC适用于长度超过2秒的语音数据,因为此类数据包含足够的包络特征。在关键词识别任务中,平均长度为1–2秒的语音指令整体特征较少。如果仅提取频谱中的包络特征,则不利于神经网络的推理。我们发现,对数梅尔滤波器组能量(LFBE)包含更多特征,例如低频和频谱细节。许多提案已采用LFBE作为特征提取方法(Sainath和Parada 2015;Coucke 等人 2019)。此外,MFCC在时间轴上的一阶导数 (Delta)和二阶导数(Delta-Delta)特征能更好地表示帧之间的相关性。
深度学习模型具有强大的学习和表征能力,能够从输入特征中提取更鲁棒的特征(Abdel-Hamid 等人 2014)。我们提出一种新的特征提取方法 LFBE-增量 作为输入特征。LFBE-增量 为 39 维,通过 LibROSA包(McFee 等人 2015)每 30 ms 计算一次,帧移为 10 ms。它包含三个特征:LFBE、Delta 和 Delta-Delta。每个特征的维度为 13。与 MFCC 相比,它包含了更多类型的特征,如图2,有助于模型提取更有用的特征并提高准确率。
3.1.2 第一卷积层特征增强
卷积核通过将输入信号与滑动窗口进行相乘来增强特征,然后输出一个尺寸较小的特征图。卷积操作参数包括步幅、卷积核大小和填充,如表1所述。通过设置步幅为= 1,输出图的尺寸保持不变。因此,重复多次卷积操作等效于相加特征。与大尺寸输入特征相比,小尺寸输入可以相对节省计算成本。
与计算机视觉中3× 224× 224的输入数据维度相比 (Zhang 等人 2018;Howard 等人 2017),39 维的 LFBE-增量声学特征过小,难以有效提取有效特征。在卷积层中,通过设置步幅保持输出特征图尺寸不变,可提取更高效的特征。因此,我们通过设置步幅= 1来保持输出特征图尺寸不变,以实现特征增强。卷积操作的计算公式如下:
$$
\left{ \frac{t - m + 2 \times p}{s} + 1 \right} \times \left{ \frac{f - n + 2 \times p}{s} + 1 \right}
$$
其中 t 和 f 分别表示输入特征在时域和频域的维度。m × n、p 和 s 分别是卷积操作的卷积核大小、填充和步幅。二维卷积的输出特征图是 2d 维,当设置步幅为 = 2 时;而二维卷积_增强后的维度为 d 维,对应步幅为 = 1。这意味着输入特征得到了增强。随着步幅减小,模型计算量将相应倍数增加。在实验中,我们发现该方法仅使用一次时,在计算成本和提升性能之间达到了最佳平衡。
 MFCC 和 39D LFBE-增量 (LFBE-增量表示 13D LFBE、13D 增量和 13D 增量- 增量的拼接))
MFCC 和 39D LFBE-增量 (LFBE-增量表示 13D LFBE、13D 增量和 13D 增量- 增量的拼接))
| 卷积 | 卷积核大小 | 步幅 | 填充 |
|---|---|---|---|
| 二维卷积 | 3× 3 | 2× 2 | 1× 1 |
| 二维卷积 enhance | 3× 3 | 1× 1 | 1× 1 |
表1 卷积操作参数
二维卷积表示标准卷积,Conv2D_enhance表示具有步幅= 1设置的 增强卷积
3.2 EdgeCRNN的构建模块
在本节中,我们首先介绍EdgeCRNN模块所基于的核心方法(即深度可分离卷积和残差结构)。然后介绍 EdgeCRNN模块和循环神经网络。
3.2.1 深度可分离卷积
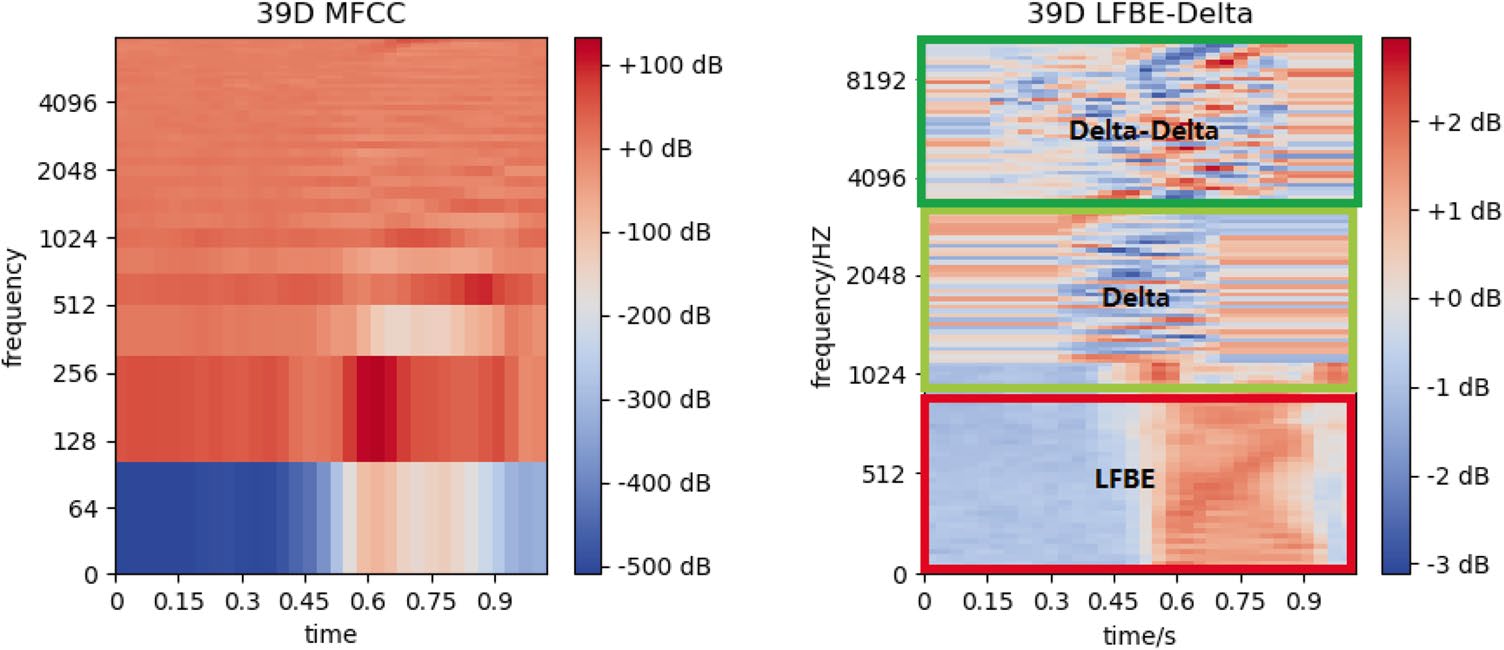
深度可分离卷积的思想基于滤波器的深度和空间维度可以被分离。因此,它将一个卷积核拆分为两个独立的部分:深度可分离卷积(DWConv)和逐点卷积(PConv)。深度可分离卷积(DWConv)在输入信号的每个通道上独立执行,然后逐点卷积(PConv)将深度可分离卷积 (DWConv)的输出通道投影到新的通道空间中。
根据 Howard 等人(Howard et al.,2017)的研究,深度卷积和逐点卷积的浮点运算次数分别为 $D^2_K \times M \times D^2_F$ 和 $N \times M \times D^2_F$,而深度可分离卷积的浮点运算次数为 $1N + 1D^2_k$ 是标准卷积操作的M和N分别为输入和输出通道的数量,D k 是卷积核大小,而DF是方形输入特征图的空间宽度和高度。它在许多轻量级模型研究中逐渐取代了标准卷积核。大多数EdgeCRNN的卷积核大小为1× 1 ,因此EdgeCRNN的计算成本比全尺寸3× 3卷积层大约减少了9倍。这证明了 EdgeCRNN模型能够降低计算成本和模型参数。
DWConv无法改变输入特征的通道数量(图3a),当通道数较少时,特征无法被良好提取。声学特征仅有一通道数量,提取效果较差。然而,PConv可以改变通道数量,且根据上述描述,其计算量和模型参数相对较小。因此,我们在DWConv层之前增加一个 PConv层以提升通道数量,如图3b所示,模型的特征提取效果将更好。

3.2.2 残差结构
理论上,更深的网络具有更强的学习能力。然而,随着网络层数量的增加,模型结构变得更加复杂,需要高昂的计算成本,甚至会出现梯度消失/爆炸的问题。因此,He 等人(He et al.2016)提出了 ResNet 来解决上述问题。该模型基于残差结构,并使用了跳跃连接。跳跃连接是在神经网络中跳过一个或多个网络层的恒等映射函数。
公式 2 可通过 Lth L−1 层带有跳跃连接的前馈神经网络实现(图 4),其中F(⋅)是诸如卷积(Conv)、批归一化和ReLU函数等操作的复合函数。 XL表示第 L th 层的输出。在本研究中,跳跃连接仅执行恒等映射,不同层的输入和输出通过逐元素相加或在通道维度上拼接。恒等跳跃连接不会引入额外参数或计算复杂度。残差结构提高了模型的训练速度。在模型设计过程中,我们添加残差结构以提高模型效率并减少冗余的隐藏层。
$$
X_L = F(X_{L-1}) + X_{L-1}
$$

3.2.3 循环神经网络
循环神经网络利用循环结构将先前状态信息与当前状态连接起来,能够很好地提取序列数据上下文特征。然而,标准RNN存在短期记忆问题。长短期记忆网络(LSTM) (Hochreiter和Schmidhuber 1997)和门控变体循环神经网络中的门控循环单元(GRU)(Cho 等人 2014)被提出作为解决该问题的方案。它们具有称为记忆细胞的内部机制,能够存储信息流。双向长短期记忆网络(BiLSTM)能够很好地获取时间序列特征,并达到 96.6% 的准确率( Zeng 和 Xiao 2019)。因此,我们在 EdgeCRNN 模型中使用长短期记忆网络(LSTM)。
3.2.4 EdgeCRNN模块
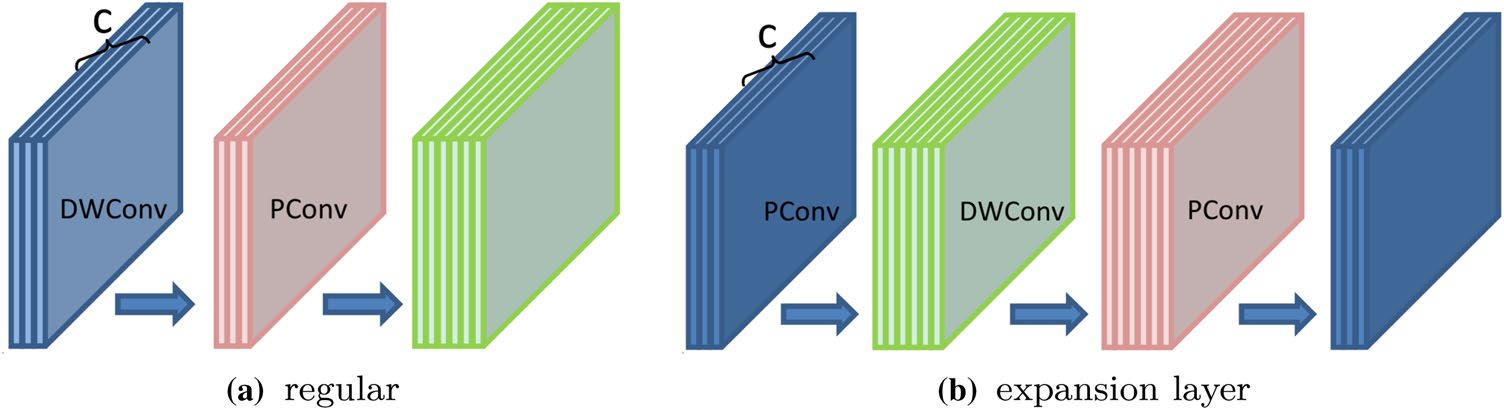
我们基于深度可分离卷积和残差结构设计了 EdgeCRNN模块,该设计类似于论文(Ma等人2018)中的方法。如上所述,EdgeCRNN模块使用扩展层 (图3b)来增加通道数,并且包含基础块和 EdgeCRNN块(图5)。EdgeCRNN模块由两个 PConv层和一个DWConv层组成,选用ReLU激活函数,并使用批归一化对输入数据进行归一化。假设x为输入数据,在EdgeCRNN块中,两个分支的输入数据与x相同,而在基础块中,将x分成两半作为两个分支的输入。EdgeCRNN块用于下采样,通过在 DWConv层设置步幅= 2将输入信号尺寸减半,然后使用拼接操作使通道数量加倍。拼接表示将多个数据源组合在一起。基础块是基本模块,通过相加操作添加特征,输入信号的尺寸和通道数保持不变,步幅设置为= 1。每个阶段的第一个单元使用EdgeCRNN块 (详见第3.3节),其后跟随基础块。

3.3 EdgeCRNN的架构
EdgeCRNN架构是一种CNN与RNN的混合模型,其中CNN主要由堆叠的EdgeCRNN模块组成,RNN则选用包含一个隐藏层且具有64个节点的LSTM模型。此外,CNN被划分为一个称为卷积1的第一卷积层特征增强层、三个阶段以及一个名为卷积5的标准卷积层。卷积1和卷积5包含一种基于样本离散化的变体池化算子,其目标是对输入表示进行下采样(Sun等人2016)。卷积1采用最大池化,卷积5采用全局池化。图6
| 阶段*为EdgeCRNN模块,K和S分别为卷积核大小和步幅,R表示模块数量,填充= 1 | ||||||
|---|---|---|---|---|---|---|
| 层 | 输出 | K | S | R | 输出通道 | |
| 0.5× | 1.0× | |||||
| 音频 | 39× 101 | – | – | – | 1 | |
| 卷积1 | 39× 101 | 3× 3 | 1 | 1 | 16 | 24 |
| 最大池化 | 20× 51 | 3× 3 | 2 | |||
| 阶段2 | 10× 26 | 3× 3 | 2 | 1 | 32 | 72 |
| 10× 26 | 3× 3 | 1 | 1 | |||
| 阶段3 | 5× 13 | 3× 3 | 2 | 1 | 64 | 144 |
| 5× 13 | 3× 3 | 1 | 2 | |||
| 阶段4 | 3× 7 | 3× 3 | 2 | 1 | 128 | 288 |
| 3× 7 | 3× 3 | 1 | 1 | |||
| 卷积5 | 3× 7 | 1× 1 | 1 | 1 | 256 | 512 |
| 全局池化 | 1× 7 | 3× 1 | 1 | |||
| RNN | – | – | – | – | 64 | |
| FC | – | – | – | – | 12 | |
| 兆浮点运算每秒 | 4.10 | 14.54 | 34.89 | 57.65 | ||
| 百万权重 | 0.15 | 0.59 | 1.15 | 1.68 |
表2 EdgeCRNN架构

4 EdgeCRNN上的实验
在本节中,我们介绍了数据集、实验步骤以及模型训练方法。接着,我们研究了特征增强和EdgeCRNN模块的影响,并将结果与全卷积模型进行比较。最后,我们比较了EdgeCRNN与主流关键词识别模型的性能。
4.1 EdgeCRNN上的实验步骤
我们使用Google语音命令数据集(Warden 2018)对模型进行评估,该数据集包含来自数千名不同人士的 65,000条长度为1秒的30个单词的语音片段。采样频率为 16千赫兹。我们的任务是在12个类别“yes”、“no”、“up”、“down”、“left”、“right”、“on”、“off”、“stop”、“go”、未知类和静音类之间进行区分。未知类别用于模拟模型学习关键词与非关键词之间的差异。静音类表示低响度的音频。在信噪比为随机采样于[ −5 分贝,+ 10 分贝],范围内的条件下,我们手动向数据集中添加汽车噪声和餐厅噪声。这可以提升关键词识别系统在实际应用中的性能,使其更接近连续噪声背景的情况。数据集随后按80:10:10的比例被随机划分为训练集、验证集和测试集。EdgeCRNN在训练集和验证集上进行训练,实验结果来自测试集。
我们采用Tpool2(Tang等人2018)作为基线模型,该模型由两个卷积层、两个线性层和一个DNN层组成。在我们的实验中,输入特征为39维LFBE-增量。EdgeCRNN在每个卷积层上使用ReLU激活函数、Adam优化器和交叉熵(CE)损失函数。在公式3中,学习率每50轮衰减一次。初始学习率LR_init是1E−3,结束学习率 LR_end 等于1E−4,总训练轮数 total_epoch 为500,current_epoch 表示当前轮数,且批处理大小设为128。
$$
LR= LR_init− \frac{current_epoch}{total_epoch} \times(LR_init− LR_end)
$$
4.2 在EdgeCRNN上的模型训练
准确率、浮点运算次数和模型参数是我们的主要质量指标,通过正确分类决策的比例来衡量。我们还绘制了受试者工作特征(ROC)曲线,其中x轴和y轴分别表示误识率和拒识率。针对每个关键词计算曲线,然后进行垂直平均以生成整体ROC曲线。曲线越低,模型性能越好。
4.2.1 基于特征增强的训练
我们比较了采用特征增强和不采用特征增强的模型性能。在表3中,包含三个特征的LFBE-增量情况下,EdgeCRNN-Mel的准确率比EdgeCRNN-M高出3%。同时,EdgeCRNN-Mel-F与EdgeCRNN-M-F在准确率上也具有类似的关系。图7b表明,在0.1误识率的工作点下,EdgeCRNN-Mel-F相较于EdgeCRNN-M-F有69.5%的相对提升。与单一特征相比,包含三种特征类型的输入特征能够提高模型的准确率。
第一卷积层特征增强可以重复提取特征并提高准确率。EdgeCRNN-Mel-F 比 EdgeCRNN-Mel 高 0.8%。然而,EdgeCRNN-Mel-F 的浮点运算次数比 EdgeCRNN-Mel 多出近1000万次。我们发现仅重用一次最为合适。因此,EdgeCRNN 仅使用一次第一卷积层特征增强。
在误识率为0.1的操作点下,EdgeCRNN-Mel-F的拒识率相较于EdgeCRNN-Mel相对改善了34.2%,如图7a所示,表明通过特征增强,EdgeCRNN提取的特征更加鲁棒。
| 模型 | 浮点运算次数 | 参数 | 准确率 (%) |
|---|---|---|---|
| EdgeCRNN-M | 460万 | 59万 | 94.15 |
| EdgeCRNN-M-F | 1454万 | 59万 | 94.97 |
| EdgeCRNN-Mel | 460万 | 59万 | 97.05 |
| EdgeCRNN-Mel-F | 1454万 | 59万 | 97.89 |
表3 特征增强的准确率
其中,M 和 Mel 分别表示 MFCC 作为特征提取方法和 LFBE-Delta。F 表示第一卷积层特征增强,默认为 1.0×
4.2.2 基于循环神经网络的训练
除了标准RNN外,RNN还有变体模型LSTM和GRU。我们测试了EdgeCRNN与这些变体RNN模型结合后的性能。由于变体RNN的内部机制不同,参数计算方法也不同,这就是参数值在表4中有所不同。CSANN LAB(Dey和Salemt 2017)提出了参数的计算方法,RNN、LSTM、GRU的方法分别为公式4–6。
$$
P_{RNN} = n^2 + nm + n
$$
$$
P_{LSTM} = 4 \times (n^2 + nm + n)
$$
$$
P_{GRU} = 3 \times (n^2 + nm + n)
$$
其中n和m分别表示输出维度和输入维度。该公式表明,标准RNN具有最少的数量。
| 循环神经网络模型 | 浮点运算次数 | 参数 | 准确率 (%) |
|---|---|---|---|
| RNN | 1454万 | 0.38M | 97.77 |
| GRU | 1454万 | 0.53M | 97.78 |
| LSTM | 1454万 | 59万 | 97.89 |
表4 循环神经网络模型性能
RNN的浮点运算次数更为复杂,因此本文中仅对RNN的浮点运算次数进行了粗略计算。特征提取使用LFBE-增量,为1.0倍。表4显示,由于具有三个门结构,LSTM的参数最多且准确率最高,而RNN的参数最少。因此,本文选择LSTM作为Edge-CRNN中的循环神经网络。
4.3 EdgeCRNN上的结果
首先,我们测试了采用EdgeCRNN模块的EdgeCRNN性能,并将其与全卷积模型进行比较。表5显示,与全卷积模型相比,基于EdgeCRNN模块的浮点运算次数减少了6.2倍,模型参数减少了2.9倍。同时,准确率提高了0.93%。即使浮点运算次数和参数更少,EdgeCRNN 1.0×的性能仍优于Conv EdgeCRNN 1.0×。例如,图8a显示,在0.01误识率工作点下,相对性能提升了超过47%,其中Conv EdgeCRNN 1.0×代表全卷积模型。这表明,EdgeCRNN模型在保持更优性能的同时,比全卷积模型更轻量。
为了进一步检测哪个关键词识别效果好或差,我们深入研究了Google语音命令数据集上12个类别的混淆矩阵(更多12个类别细节见第4.1节)。大多数误分类情况是由于真实命令被预测为未知类别所致。对角线表示每个关键词在混淆矩阵上的准确率,图9显示了大多数关键词的准确率超过96%。由于噪声增加,忽略了静音类。由于关键词发音相似,存在许多分类误识别情况,例如未知类和“go”,未知类和“no”。此外,在12关键词任务的基础上,我们测试了EdgeCRNN 1在22个关键词任务(新增关键词“dog”、“zero”、“one”、“bed”、“two”、“three”、“四”、“五”、“bird”、“六”)中的性能。0×表6显示模型参数增加了约0.1百万,而准确率达到95.77%,仍然具有竞争力。这意味着EdgeCRNN在关键词识别任务中表现高效。
| 模型 | 浮点运算次数 | 参数 | 准确率 (%) |
|---|---|---|---|
| Conv EdgeCRNN 1.0× | 104.19M | 228万 | 96.96 |
| EdgeCRNN 1.0× | 1454万 | 59万 | 97.89 |
表5 EdgeCRNN模块与全卷积对比
(a)全卷积模型的ROC曲线。 (b)轻量级模型的ROC曲线。
| 模型 | 关键词 | 兆浮点运算每秒 | 参数 | 准确率 (%) |
|---|---|---|---|---|
| EdgeCRNN 1.0× | 12 | 1454万 | 59万 | 97.89 |
| EdgeCRNN 1.0× | 22 | 1454万 | 0.60M | 95.77 |
表6 基于22个关键词任务的性能
表7比较了以往的轻量级KWS模型(Tang et al. 2018;Sun et al. 2016;Arik et al. 2017;Zeng and Xiao 2019;Zhang et al. 2017)与Edge-CRNN之间的准确率,这些模型均在Google语音命令数据集(Warden 2018)上进行训练(除CRNN(Arik et al. 2017)使用私有的TalkType数据集,以及LSTM的数据来自文献(Zhang et al. 2017)。EdgeCRNN 1.0×的参数量并非最小,但相对轻量且小于0.6百万。此外,EdgeCRNN的准确率高于表7中其他关键词识别模型,在仅1454万次计算的有限计算成本下达到了97.89%。这表明EdgeCRNN几乎可以在关键词识别任务中达到最先进的准确率水平,并且是一个轻量级模型。
我们在边缘计算设备上评估了EdgeCRNN的性能,如表8所示。EdgeCRNN 0.5×可在Raspberry Pi 3B+上每秒读取11.1个音频数据,远快于Tpool2的5/s。这表明EdgeCRNN在准确率达到97.09%的同时,降低了延迟和计算成本。根据Google语音命令数据集中关键词音频长度为1秒的情况,我们知道人类语音速度接近每秒一个关键词。这意味着EdgeCRNN处理速度能够在资源受限的环境中跟上人类语音的速度。
为了验证EdgeCRNN适用于关键词识别(KWS),我们比较了ShuffleNetV2(Ma等人2018)和MobileNetV2(Sandler等人2018)的性能,它们是计算机视觉领域的轻量级模型。实验发现,在Raspberry Pi 3B上,EdgeCRNN 0.5x的速度分别比它们快12.2倍和74倍,且FLOPs少于1/5和1/9,如表8所示。表8中的ShuffleNetV2-M表示输入特征使用MFCC,其他模型使用LFBE-增量。ShuffleNetV2的准确率为96.91%,高于ShuffleNetV2-M的93.28%。这也证明了LFBE-增量特征能够增强特征并提升其他模型的准确率。
表9比较了不同宽度乘数模型的效果,这些模型具有四个倍数 0.5× 、1.0× 、1.5× 、2.0× ,数据来自表2。2.0×模型的准确率最高,达到98.05%,而0.5x模型每秒可处理11.1段音频,在Raspberry Pi 3B+上运行速度最快。在实际应用中,我们应权衡浮点运算次数与准确率之间的关系,以选择最合适的乘数模型。
| 模型 | 兆浮点运算每秒 | 准确率 (%) | CPU/秒 | ARM/秒 |
|---|---|---|---|---|
| Tpool2 (Tang 等人 2018) | 103 | 91.97 | 27.6 | 5.0 |
| ShuffleNetV2-M (Ma 等人 2018) | 22.11 | 93.28 | 11.6 | 0.91 |
| ShuffleNetV2 (Ma 等人 2018) | 22.11 | 96.91 | 11.6 | 0.91 |
| MobilNetV2 (Sandler 等人 2018) | 36.69 | 96.80 | 3.6 | 0.15 |
| EdgeCRNN 0.5× | 4.10 | 97.09 | 49.9 | 11.1 |
表7 相关关键词识别模型的准确率
| 模型 | 浮点运算次数 | 参数 | 准确率 (%) |
|---|---|---|---|
| Tpool2 (Tang 等人 2018) | 103M | 1.09M | 91.97 |
| LSTM (Sun 等人 2016) | 48.4M | 0.26M | 94.81 |
| CRNN (Arik 等人 2017) | 19.3 M | 0.22M | 97.71 |
| DenseNet-BiLSTM (Zeng 和肖 2019) | – | 0.24M | 97.50 |
| DS-CNN (Zhang 等人 2017) | 5690万 | 47万 | 95.38 |
| EdgeCRNN 1.0× | 1454万 | 59万 | 97.89 |
表8 不同平台上相关关键词识别模型的准确率和速度性能
CPU 表示在搭载 3.6 GHz Intel(R) Core(TM) I3-8100 处理器基础频率的平台上的测试速度。ARM 是指具有 1.2 GHz 处理器基础频率和 1 GB 内存的 Raspberry Pi 3B+
| 模型 | 兆浮点运算每秒 | 参数 | 准确率 (%) | CPU/秒 | ARM/秒 |
|---|---|---|---|---|---|
| EdgeCRNN 0.5× | 4.10 | 0.29 M | 97.09 | 49.9 | 11.1 |
| EdgeCRNN 1.0× | 14.54 | 59万 | 97.89 | 25.6 | 5.0 |
| EdgeCRNN 1.5× | 34.89 | 1.29 M | 97.92 | 17.3 | 3.1 |
| EdgeCRNN 2.0× | 57.65 | 1.72 M | 98.05 | 13.5 | 2.3 |
表9 不同宽度乘数的性能
5 结论
在该论文中,我们设计了一种新的面向边缘计算设备的关键词识别(KWS)模型EdgeCRNN。我们展示了如何通过采用特征增强方法,即重复提取特征和提取三种类型的特征,来提升EdgeCRNN的性能。结果表明,EdgeCRNN在树莓派3B+上每秒可处理11.1段音频,其准确率达到98.05%。然而,变体EdgeCRNN 1.0×的浮点运算次数仍然相对较高,准确率也有进一步提升的空间。此外,模型测试平台仅限于ARM CPU。未来,我们将继续降低计算成本,提高准确率,并将KWS系统应用于不同的环境中。


















 13
13

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









