










目录
1 总体思想
2 Gamma变换(图像预处理)
3 HOG特征详细解释
4 SVM原理简介
5 opencv+python代码实现
ps.现在这篇帖子方法早就过时了,作为一个知识学习还是可以。
现在可以直接去关注 深度学习的 YOLOV5, FASTER-RCNN等目标检测算法!!!
1 总体思想
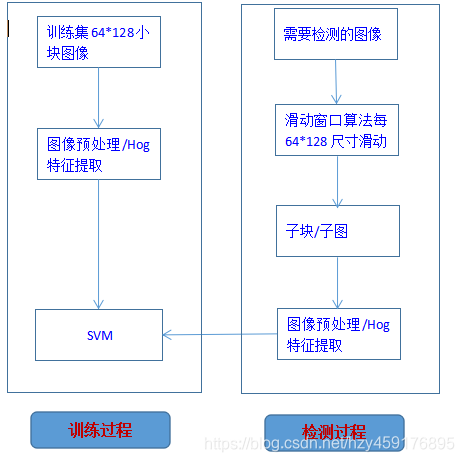
众所周知,机器学习一般分为算法训练过程,和预测过程,下面就简单描述总体训练和预测思想:
1.1 模型训练过程
- (1)准备一堆训练集,训练集是 “有行人” 和 “没有行人” 的正负样本图(我们设定统一64x128大小),分别若干张。
- 如图所示,比如:
 这是“行人”的正样本图像块
这是“行人”的正样本图像块  这是“没有行人”的负样本图像块
这是“没有行人”的负样本图像块 - (2)对上述一些数据集进行图像预处理(Gamma矫正),目的是减少光照对图像的影响;
- (3)对预处理的图像提取hog特征(此步骤后边将重点介绍:包含计算图像梯度+计算梯度直方图+特征归一化);
- (4)拿正负样本的hog特征,结合正负标签,有监督训练SVM二分类算法。训练完成后,保存SVM模型参数。
hog+svm整体工作流程如下:

1.2 行人检测过程
(1)将一张待检测的图像,每64x128的局部区域进行滑动,每滑动的那一个块拿来预测是否是“有行人”的区域;
(2)将图中每次滑动后的局部区域块,都要同理经过训练过程中的(2-3)步骤:即提取特征过程;
(3)每一个块将提取好的hog特征,送入前面已经训练好的svm分类器,得到是否有行人的类别;
(4)如果该块是“有行人”那一类,则该块的坐标信息就是整张图中有行人的地方;
(5)将有行人的那些块,根据坐标信息,在图中框出来,既完成“行人检测”工作。<--------------- 模型训练/检测流程图:------------------------>
2 Gamma变换(图像预处理)
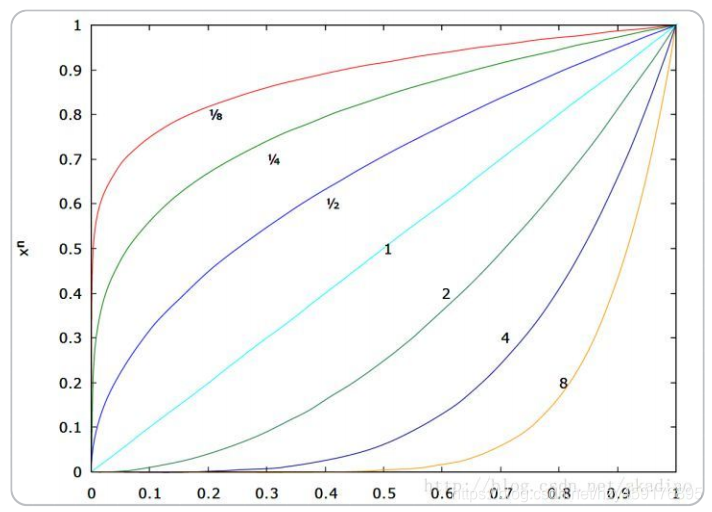
主要是调节图像对比度,减少光照对图像的影响(包括光照不均和局部阴影),使过曝或者欠曝的图像恢复正常,更接近人眼看到的图像。其原理描述如下:

python实现:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('*.png', 0)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img2 = np.power(img/float(np.max(img)),1/2.2)
plt.imshow(img2)
plt.axis('off')
plt.show()3 HOG特征详细解释
3.1 HOG简介
HOG特征是一种图像局部特征,其基本思路是对图像局部的梯度幅值和方向进行投票统计,形成基于梯度特性的直方图,然后将局部特征拼接起来作为总特征。局部特征在这里指的是将图像划分为多个子块(Block), 每个Block内的特征进行联合以形成最终的特征。hog特征表示图样子可如下所示:

3.2 图像的梯度
3.2.1 求梯度方法
图像的梯度是指:可以把图像看成二维离散函数,图像梯度其实就是这个二维离散函数的求导。
前面讲到,要得到HOG特征,必须要计算图像的梯度直方图,那么首先需要计算图像水平方向和垂直方向梯度。
一般的,采用sobel算子,可以很好的计算图像x方向和y方向梯度信息,两个方向的基础sobel算子如下所示:
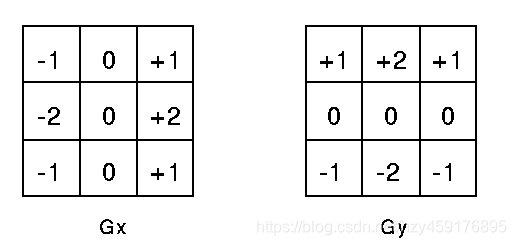
有了sobe算子后,利用如下方式对图像依次卷积滤波,可以求得图像的梯度信息
(其中Gx是水平梯度,Gy是垂直梯度,G是综合图像梯度或者横幅信息,A是原图像)。

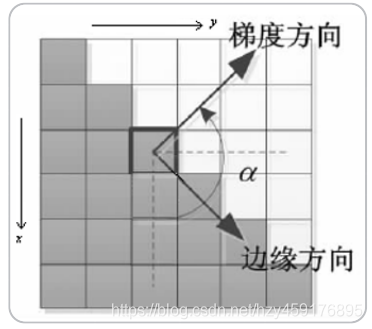
有了梯度信息,图像像素对应的角度信息,也可以求出为:α = arctan(Gy/Gx)
需要注意的是:梯度方向和图像边缘方向是互相正交的。如下图所示:
3.2.2 Python实现
mport cv2
import numpy as np
# Read image
img = cv2.imread('*.jpg')
img = np.float32(img) / 255.0 # 归一化
# 计算x和y方向的梯度
gx = cv2.Sobel(img, cv2.CV_32F, 1, 0, ksize=1)
gy = cv2.Sobel(img, cv2.CV_32F, 0, 1, ksize=1)
# 计算合梯度的幅值和方向(角度)
mag, angle = cv2.cartToPolar(gx, gy, angleInDegrees=True)3.3 梯度直方图
经过上一步计算,每一个像素点都会有两个值:梯度幅值/梯度方向。
然后,我们将图像被分为若干个8×8的cell,例如一个图像是64x128,那么这幅图像就被划分为8x16个8x8的cell单元,并为每个8×8的cell计算梯度直方图。(PS. cell的划分也可以是其他值:16x16,8x16等,根据具体的场景确定)
为什么我们将图像分成若干个cell? ----> 因为如果对一整张梯度图逐像素计算,其中的有效特征是非常稀疏的,不但运算量大,而且会受到一些噪声干扰。于是我们就使用局部特征描述符来表示一个更紧凑的特征,计算这种局部cell上的梯度直方图更具鲁棒性。
回到前面描述,以8x8的cell为例,一个8x8的cell包含了8x8x2 = 128个值,因为每个像素包括梯度的大小和方向。
那么,在HOG中,每个8x8的cell的梯度直方图本质是一个由9个数值组成的向量(为什么是9个?-----> 因为对应了九个不同梯度方向,以20度为一个间隔, 0,20,40,... 160:共9个). 那么那么原本cell中8x8x2 = 128个值就由长度为9的向量来表示,用这种梯度直方图的表示方法,大大降低了计算量,同时又对光照等环境变化更加地鲁棒。
比如下图中,一个小cell是8*8, 中间的图像表示一个cell中的梯度矢量,箭头朝向代表梯度方向,箭头长度代表梯度大小。右图我们分别计算了cell中每个像素值的横幅Gradient magnitude,和梯度方向gradient direction,注意角度的范围介于0到180度之间,而不是0到360度, 这被称为“无符号”梯度,因为两个完全相反的方向被认为是相同的。
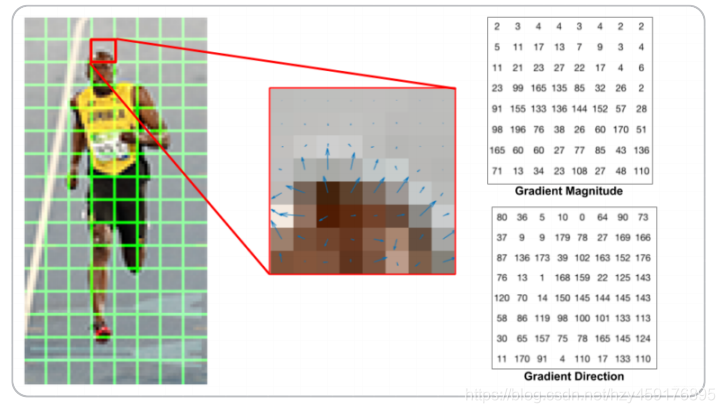
接下来,我们来计算cell中像素的梯度直方图,将0-180度分成9等份,称为9个bins,分别是0,20,40...160。然后对每个bin中梯度的贡献进行统计:
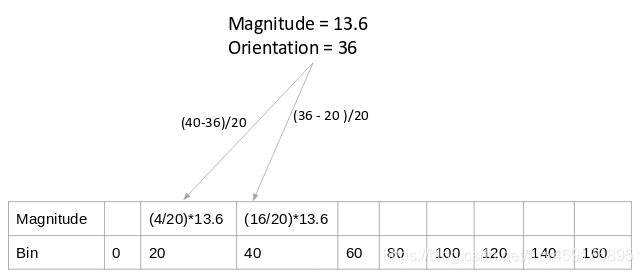
统计方法是一种加权投票统计, 如上图所示,某像素的梯度幅值为13.6,方向为36,36度两侧的角度bin分别为20度和40度,那么就按一定加权比例分别在20度和40度对应的bin加上梯度值,加权公式为:
20度对应的bin:((40-36)/20) * 13.6,分母的20表示20等份,而不是20度;
40度对应的bin:((36-20)/20) * 13.6,分母的20表示20等份,而不是20度;这里有一个细节需要注意:如果某个像素的梯度角度大于160度,也就是在160度到180度之间,那么把这个像素对应的梯度值按比例分给0度和160度对应的bin。如左下图绿色圆圈中的角度为165度,幅值为85,则按照同样的加权方式将85分别加到0度和160度对应的bin中。(最终每个像素对各个bin的分配值 累计相加,得到每个bin的直方图柱子值)
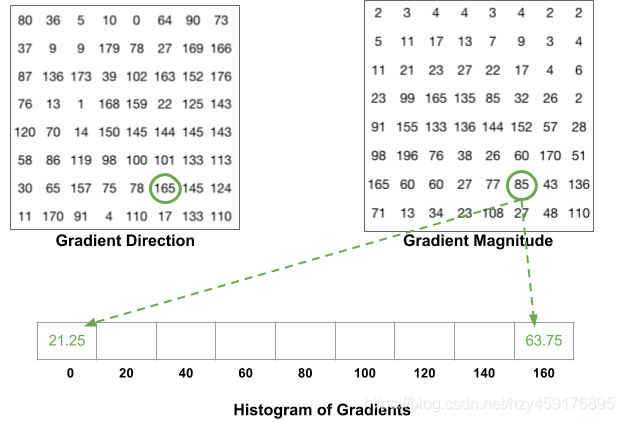
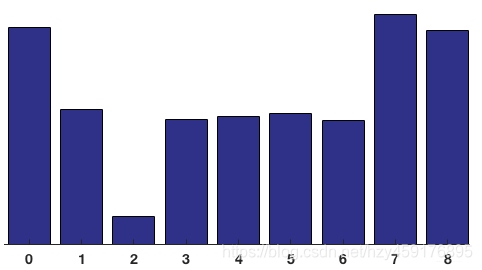
对整个cell进行投票统计,正是在HOG特征描述子中创建直方图的方式,最终得到由9个数值组成的向量—梯度方向图:
3.4 Block再归一化
HOG特征将8×8的一个局部区域作为一个cell,然后我们再以2×2个cell作为一组,称为一个block,也就是说一个block表示16x16的区域。为什么又需要分block呢?------> 这是因为,虽然我们已经为图像的8×8单元创建了HOG特征,但是图像的梯度对整体光照很敏感。这意味着对于特定的图像,图像的某些部分与其他部分相比会非常明亮。我们不能从图像中完全消除这个。但是我们可以通过使用16×16个块来对梯度进行归一化来减少这种光照变化。
所以,由于每个cell有9个值,一个block(2×2个cell,4个cell),则有36个值。所以进行图像的block再归一化!!!
前面已经说明,归一化的目的是为了降低光照的影响,因为梯度对整体光照非常敏感,比如通过将所有像素值除以2来使图像变暗,那么梯度幅值将减小一半,因此直方图中的值也将减小一半,我们就需要将直方图“归一化”。归一化的方法有很多:L1-norm、L2-norm、max/min等等,一般选择L2-norm。
所以归一化方法就是:一个cell有一个梯度方向直方图,包含9个数值,一个block有2*2即4个cell,那么一个block就有4个梯度方向直方图,将这4个直方图拼接成长度为36的向量,然后对这个向量进行统一归一化。每一个block将按照上图滑动的方式进行重复计算,直到整个图像的block都计算完成。
3.5 最终HOG特征信息
紧接着前面讲,每一个16 * 16大小的block将会得到一个长度为36的特征向量,并进行归一化。 那会得到多少个特征向量呢?-----> 例如,对于上图被划分8 * 16个cell ,每个block有2x2个cell的话,依次步长为1的滑动图像,其实block数量为:7个水平block和15个竖直block。
前面讲到,每个block有36个值,整合所有block的特征值,最终获得由36 * 105=3780个特征值组成的特征描述符,而这个特征描述符是一个一维的向量,长度为3780。
到这里,这一个block的所有特征就提取完成了。获得HOG特征向量,就可以用来可视化和分类了。对于多维的HOG特征,提取完一个图像,即一个64*128矩阵的所有hog特征后,机器学习SVM分类器就可以排上用场了。
4 SVM原理简介
SVM的原理,很多大神都有详细介绍过,篇幅有限,关于机器学习的svm分类器,我这里就不在赘述。大家可自行搜索资料学习其原理,主要用于二分类效果非常好! 我们本篇文章的是对图像提取hog特征,然后利用这些特征训练SVM分类器。
5 opencv+python实现
我们这里只介绍简单的opencv封装好了的成熟接口,他内置算法原理就是前面讲述的系列过程。
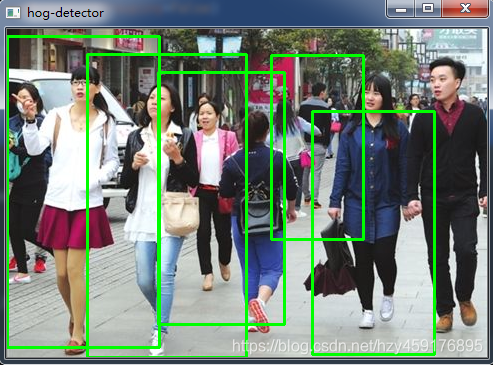
所以,这里实现这里我们只调用opencv成熟的模型,看看行人检测效果:
import cv2 as cv
# hog+svm 行人检测案例 ##############################
if __name__ == '__main__':
src = cv.imread('data/xingren.jpg')
cv.imshow("input", src)
hog = cv.HOGDescriptor()
# opencv的 默认的 hog+svm行人检测器
hog.setSVMDetector(cv.HOGDescriptor_getDefaultPeopleDetector())
# Detect people in the image
(rects, weights) = hog.detectMultiScale(src,
winStride=(2, 4),
padding=(8, 8),
scale=1.2,
useMeanshiftGrouping=False)
for (x, y, w, h) in rects:
cv.rectangle(src, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv.imshow("hog-detector", src)
cv.imwrite("hog-detector.jpg", src)
cv.waitKey(0)
cv.destroyAllWindows()(1)原图 ------>

(2) 运行结果图 (效果不太好,以后自己实现的时候再调优吧) ------>
参考来源:
https://hal.inria.fr/file/index/docid/548512/filename/hog_cvpr2005.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









