



 本文针对BZOJ4502题进行解析,利用Trie树和AC自动机解决字符串拼接问题,避免重复计数,实现高效算法。
本文针对BZOJ4502题进行解析,利用Trie树和AC自动机解决字符串拼接问题,避免重复计数,实现高效算法。
题目:BZOJ4502.
题目大意:给定
n
n
n个单词,求两个在是这些单词中任意一个单词前缀的串拼起来能够组合出的字符串数量.
1
≤
n
≤
1
0
4
1\leq n\leq 10^4
1≤n≤104,单词长度
≤
30
\leq 30
≤30.
考虑最多有多少种可能,发现最多会有 n 2 n^2 n2种情况,但是这写情况中会有重复.
考虑去掉重复,发现一个若一个字符串 s = s 1 + s 2 = s 1 ′ + s 2 ′ s=s_1+s_2=s'_1+s'_2 s=s1+s2=s1′+s2′且 ∣ s 1 ′ ∣ > ∣ s 1 ∣ |s'_1|>|s_1| ∣s1′∣>∣s1∣时,那么 s 1 s_1 s1必然是 s 1 ′ s'_1 s1′的一个前缀,并且 s 2 ′ s'_2 s2′必然是 s 2 s_2 s2的一个后缀.
于是想到Trie树经常用于处理前缀问题,而AC自动机的fail树又可以用来处理后缀,我们考虑将这些串构成一个AC自动机.
我们深入思考一个串s会被重复构造的情况,如下图:
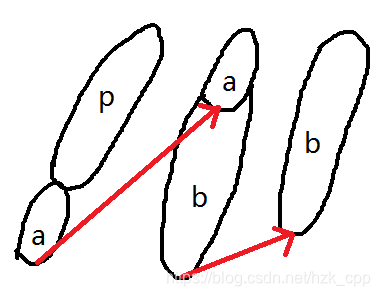
我们发现,当一个串
s
s
s被重复构造时,总会有一个前缀
p
p
p,使得
s
=
p
+
a
+
b
s=p+a+b
s=p+a+b,我们发现只要让串
p
+
a
p+a
p+a和
b
b
b在Trie中有,串
p
p
p和
a
+
b
a+b
a+b在Trie中也就会出现一次重复.
我们发现若要出现这种情况则必须满足 p + a p+a p+a能够通过fail指针跳到 a a a,而且 a + b a+b a+b也能通过fail指针跳到 b b b,会有这种重复的情况.
那么考虑枚举串 a + b a+b a+b,切掉它的最长后缀 b b b(使 a a a最短,避免重复计数),统计 a a a是多少个串的后缀即可得到一种方案重复了多少次.
接下来的问题就是如何实现了,枚举串我们可以dfs实现,切掉最长后缀就相当于切掉它的fail指针指向的串,剩余部分可以通过记录深度与dfs时每个深度代表的串来实现.统计一个串是多少个串的后缀可以通过fail树上的子树大小 s i z siz siz来实现.
时间复杂度 O ( ∑ s i ) O(\sum s_i) O(∑si),若把每个字符串的长度看成常数,则时间复杂度为 O ( n ) O(n) O(n).
代码如下:
#include<bits/stdc++.h>
using namespace std;
#define Abigail inline void
typedef long long LL;
#define m(a) memset(a,0,sizeof(a))
const int N=1000000,C=26;
struct Trie{
int s[C],deep,fail,siz;
Trie(){m(s);deep=fail=0;siz=1;}
}tr[N+9];
int cn;
void Build(){tr[cn=0]=Trie();}
void Insert(char *c,int len){
int x=0;
for (int i=1;i<=len;++i)
if (tr[x].s[c[i]-'a']) x=tr[x].s[c[i]-'a'];
else {
tr[x].s[c[i]-'a']=++cn;
tr[cn]=Trie();
tr[cn].deep=tr[x].deep+1;
x=cn;
}
}
queue<int>q;
int ord[N+9],co;
void Get_fail(){
ord[co=0]=0;
for (int i=0;i<C;++i)
if (tr[0].s[i]) q.push(tr[0].s[i]);
while (!q.empty()){
int x=q.front(),t;q.pop();
ord[++co]=x;
for (int i=0;i<26;++i)
if (tr[x].s[i]){
t=tr[x].fail;
while (t&&!tr[t].s[i]) t=tr[t].fail;
tr[tr[x].s[i]].fail=tr[t].s[i];
q.push(tr[x].s[i]);
}
}
for (int i=co;i>=1;--i)
tr[tr[ord[i]].fail].siz+=tr[ord[i]].siz;
}
int pos[N+9];
LL ans;
void dfs(int x,int dep){
pos[dep]=x; //pos[dep]表示当前dfs时深度为dep的串所对应在Trie上的节点
if (tr[x].fail) ans+=tr[pos[dep-tr[tr[x].fail].deep]].siz-1;
//这表示一个串被重复了tr[pos[dep]-tr[tr[x].fail].deep]].siz次,因为要留下一次所以减1
for (int i=0;i<C;++i)
if (tr[x].s[i]) dfs(tr[x].s[i],dep+1);
}
int n;
char c[N+9];
Abigail into(){
int len;
scanf("%d",&n);
Build();
for (int i=1;i<=n;++i){
scanf("%s",c+1);
len=strlen(c+1);
Insert(c,len);
}
}
Abigail work(){
Get_fail();
dfs(0,0);
}
Abigail outo(){
printf("%lld\n",LL(cn)*cn-ans);
}
int main(){
into();
work();
outo();
return 0;
}

















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









