







文章目录
排序算法有很多,最经典的、最常用的:冒泡排序、选择排序、归并排序、快速排序、计数排序、基数排序、桶排序。按照时间复杂度把他们分成三类。
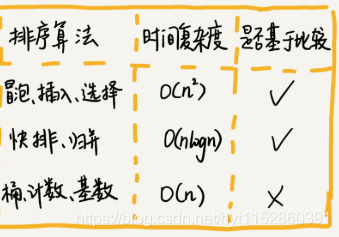
思考题:插入排序和冒泡排序的时间复杂度相同,都是O(n2),在实际软件开发里,为什么我们更倾向于使用插入排序算法而不是冒泡排序算法呢?
如何分析一个“排序算法”
排序算法的执行效率
排序算法的 执行效率,一般从这几个方面来衡量:
- 最好情况、最坏情况、平均情况时间复杂度
- 时间复杂度的系数、常数、低阶
- 比较次数和交换(或移动)次数
排序算法的内存消耗
算法的内存消耗通过空间复杂度来衡量,针对排序算法的空间复杂度,引入一个新的概念,原地排序(Sorted in place)。原地排序算法,特指空间复杂度是O(1)的排序算法。
排序算法的稳定性
- 稳定性,这个概念是说,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
冒泡排序(Bubble Sort)
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让他两互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复n次,就完成了n个数据的排序工作。
#include <stdio.h>
#include <stdlib.h>
#include "stdbool.h"
/*
@func: 从小到大排序
@param1: 数组
@param2: 数组大小
*/
void bubble_sort(int a[], int size)
{
int i, j;
int tmp;
bool flag; // 用于标识是否还存在数据交换 0:没有可直接退出 1:有,继续比较
if (size <= 1) {
printf("Don't need to sort.\n");
return;
}
/*未排序个数*/
for (i = 0; i < size; i++) {
flag = false;
for(j = 0; j < size-i-1; j++) {
if (a[j] > a[j+1]) {
tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
flag = true; //有数据交换
}
if (!flag)
break; //没有数据交换。提前退出
}
}
}
int main()
{
int a[10] = {10, 3, 4, 10, 32, 5, 6, 9, 17, 20};
int len = sizeof(a)/sizeof(int);
int i;
bubble_sort(a, len);
for (i = 0; i < len; i++) {
printf("a[%d] ---> %d\n", i, a[i]);
}
return 0;
}
结合分析排序算法的三个方面,评估一下冒泡排序。
- 冒泡排序是原地排序算法吗 ?
冒泡排序的过程只涉及相邻数据的交换操作,空间复杂度为O(1),是一个原地排序算法。 - 冒泡排序是稳定排序算法吗?
当相邻两个元素的大小相等时,不做交换,相同大小数据排序前后顺序不会改变。 - 冒泡排序的时间复杂度是多少?

如何分析冒泡排序的平均时间复杂度?通过有序度和逆序度两个概念来进行分析。
有序度:数组中具有有序关系的元素对个数。一个完全有序的数组,比如1,2,3,4,5,6,有序度是n*(n-1)/2,也就是15。把完全有序的数组的有序度叫做满有序度。
逆序度:定义也有序度相反(默认从小到大为有序)。
逆序元素对:a[i] > a[j], 如果 i < j。
有一个公式可以表示他们之间的关系,逆序度 = 满有序度 - 有序度。排序的过程是一个增加有序度,减少逆序度的过程,最后达到满有序度的过程。
对于包含n个数据的数据进行冒泡排序,平均交换次数是多少?
最坏情况:初始有序度是0,要进行n*(n-1)/2次交换
最好情况:初始有序度为n*(n-1)/2, 不需要进行交换
取中间值n*(n-1)/4,来表示初始有序度既不是很高也不是很低的平均情况。所以平均情况下的时间复杂度就是O(n2)。
插入排序(Insertion Sort)
一个有序数组,往里面添加一个新的数据后,如何继续保持数据有序?我们只要遍历数组,找到数据应该插入的位置将其插入即可。
插入排序实现思路:将数组中的数据分为两个区间,已排序区间和未排序区间。初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束。
#include <stdio.h>
#include <stdlib.h>
#include "stdbool.h"
/*
@func: 插入排序
*/
void insert_sort(int a[], int len)
{
int i, j;
int value;
if (len <= 1) {
printf("Don't need to sort.\n");
return;
}
for (i = 1; i < len; i++) {
value = a[i];
j = i-1;
/*查找插入的顺序*/
for (; j >= 0; j--) {
if(a[j] > value) {
a[j+1] = a[j]; //数据移动
} else {
break;
}
}
a[j+1] = value;
}
}
int main()
{
int i;
int a[10] = {10, 3, 4, 10, 32, 5, 6, 9, 17, 20};
int len = sizeof(a)/sizeof(int);
insert_sort(a, len);
for (i = 0; i < len; i++) {
printf("a[%d] ---> %d\n", i, a[i]);
}
return 0;
}
插入排序分析
- 插入排序是原地排序算法吗?
插入排序不需要额外的存储空间,空间复杂度是O(1),是一个原地排序算法。 - 插入排序是稳定的排序算法吗?
在插入排序中对于相同的元素,我们可以将后面出现的元素插入到前面出现的元素后面,不改变排序前后的顺序,所以插入排序是稳定的排序算法。 - 插入排序的时间复杂度是多少?
在数组中插入一个数据的平均时间复杂度是O(n),对于插入排序来说,每次插入操作都相当于在数组中插入一个数据,循环执行n次插入操作,所以平均时间复杂度为O(n2)。
选择排序(Selection Sort)
选择排序的实现思路有点类似插入排序,也分已排序区间和未排序区间。选择排序每次会从未排序区中找到最小的元素,插入已排序区间的末尾。
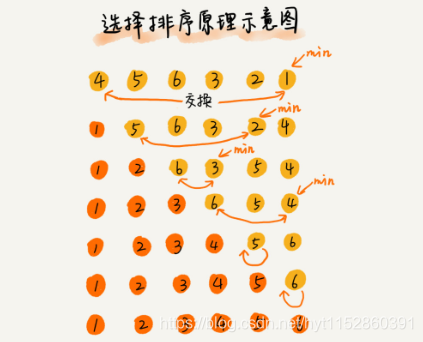
选择排序算法分析:
选择排序空间复杂度为O(1),是一种原地排序算法。选择排序的最好情况时间复杂度、最坏情况时间复杂度和平均情况时间复杂度都是O(n2)。选择排序不是一种稳定算法。
算法实现:
#include <stdio.h>
#include <stdlib.h>
void select_sort(int a[], int len)
{
int i, j;
int tmp, value, idx;
if (len <= 1) {
printf("Don't need to sort.\n");
return;
}
for (i = 0; i < len; i++) {
value = a[i];
j = i;
for ( ;j < len; j++) {
if (a[i] > a[j]) {
a[i] = a[j]; //找到最小值
idx = j; //记录最小值的索引
}
}
if (value == a[i]) //最小值就是本身不需要交换
continue;
//交换
a[idx] = value;
}
return;
}
int main()
{
int a [8] = {10, 10, 30, 73, 4, 1, 5, 2};
int len = sizeof(a)/sizeof(int);
int i;
select_sort(a, len);
for(i = 0; i < len; i++) {
printf("a[%d] ---> %d\n", i, a[i]);
}
}
小节
分析、评价一个排序算法需要从执行效率、内存消耗和稳定性三个方面来看。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









