







Abstract.:We present an image-conditional image generation model. The model transfers an input domain to a target domain in semantic level, and generates the target image in pixel level. To generate realistic target images, we employ the real/fake-discriminator as in Generative Adversarial Nets, but also introduce a novel domain-discriminator to make the generated image relevant to the input image. We verify our model through a challenging task of generating a piece of clothing from an input image of a dressed person. We present a high quality clothing dataset containing the two domains, and succeed in demonstrating decent results.
1.论文简述
整篇论文比较容易懂,主要内容就是把输入domain转换到目标domain,输入一张模特图片,得到上衣图片,如下:

文章主要贡献主要在两个方面:
1.贡献了LookBook数据集
下载地址:uj3j

2.基于Gan的转换框架
网络结构如下:
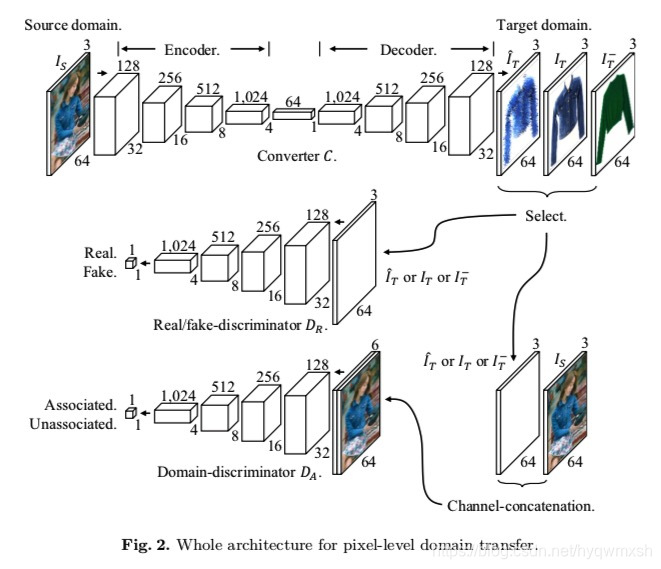
生成网络是encoder-decoder结构,判别网络有两个:Dr和Da。
Dr就是一个基本的Gan的判别网络,判别fake或real;Da主要用来判断生成图像与输入是否配对,所以Dr输入是生成网络的输入和输出的concat.
整个过程很容易懂,细节看原文即可:Pixel-Level Domain Transfer(pncc)
2.论文复现
Generator:
输入64x64x3图像,输出64x64x3生成图像。
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def conv_block(in_channels, out_channels, kernel_size, stride=1,
padding=0, bn=True, a_func='lrelu'):
block = nn.ModuleList()
block.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding))
if bn:
block.append(nn.BatchNorm2d(out_channels))
if a_func == 'lrelu':
block.append(nn.LeakyReLU(0.2))
elif a_func == 'relu':
block.append(nn.ReLU())
else:
pass
return block
def convTranspose_block(in_channels, out_channels, kernel_size, stride=2,
padding=0, output_padding=0, bn=True, a_func='relu'):
'''
H_out = (H_in - 1) * stride - 2 * padding + kernel_size + output_padding
:param in_channels:
:param out_channels:
:param kernel_size:
:param stride:
:param padding:
:param output_padding:
:param bn:
:param a_func:
:return:
'''
block = nn.ModuleList()
block.append(nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride,
padding, output_padding))
if bn:
block.append(nn.BatchNorm2d(out_channels))
if a_func == 'lrelu':
block.append(nn.LeakyReLU(0.2))
elif a_func == 'relu':
block.append(nn.ReLU())
else:
pass
return block
def encoder():
conv_layer = nn.ModuleList()
conv_layer += conv_block(3, 128, 5, 2, 2, False) # 32x32x128
conv_layer += conv_block(128, 256, 5, 2, 2) # 16x16x256
conv_layer += conv_block(256, 512, 5, 2, 2) # 8x8x512
conv_layer += conv_block(512, 1024, 5, 2, 2) # 4x4x1024
conv_layer += conv_block(1024, 64, 4, 1) # 1x1x64
return conv_layer
def decoder():
conv_layer = nn.ModuleList()
conv_layer += conv_block(64, 4 * 4 * 1024, 1, a_func='relu')
conv_layer.append(Reshape((1024, 4, 4))) # 4x4x1024
conv_layer += convTranspose_block(1024, 512, 4, 2, 1) # 8x8x512
conv_layer += convTranspose_block(512, 256, 4, 2, 1) # 16x16x256
conv_layer += convTranspose_block(256, 128, 4, 2, 1) # 32x32x128
conv_layer += convTranspose_block(128, 3, 4, 2, 1, bn=False, a_func='') # 64x64x3
conv_layer.append(nn.Tanh())
return conv_layer
self.net = nn.Sequential(
*encoder(),
*decoder(),
)
def forward(self, input):
out = self.net(input)
return outDiscriminatorR:输入64x64x3图像,输出real or fake;
class DiscriminatorR(nn.Module):
def __init__(self):
super(DiscriminatorR, self).__init__()
def conv_block(in_channels, out_channels, kernel_size, stride=1,
padding=0, bn=True, a_func=True):
block = nn.ModuleList()
block.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding))
if bn:
block.append(nn.BatchNorm2d(out_channels))
if a_func:
block.append(nn.LeakyReLU(0.2))
return block
self.net = nn.Sequential(
*conv_block(3, 128, 5, 2, 2, False), # 32x32x128
*conv_block(128, 256, 5, 2, 2), # 16x16x256
*conv_block(256, 512, 5, 2, 2), # 8x8x512
*conv_block(512, 1024, 5, 2, 2), # 4x4x1024
*conv_block(1024, 1, 4, bn=False, a_func=False), # 1x1x1
nn.Sigmoid(),
)
def forward(self, img):
out = self.net(img)
return outDiscriminatorA:
输入64x64x6的concat图像,输出real or fake;class DiscriminatorA(nn.Module):
def __init__(self):
super(DiscriminatorA, self).__init__()
def conv_block(in_channels, out_channels, kernel_size, stride=1,
padding=0, bn=True, a_func=True):
block = nn.ModuleList()
block.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding))
if bn:
block.append(nn.BatchNorm2d(out_channels))
if a_func:
block.append(nn.LeakyReLU(0.2))
return block
self.net = nn.Sequential(
*conv_block(6, 128, 5, 2, 2, False), # 32x32x128
*conv_block(128, 256, 5, 2, 2), # 16x16x256
*conv_block(256, 512, 5, 2, 2), # 8x8x512
*conv_block(512, 1024, 5, 2, 2), # 4x4x1024
*conv_block(1024, 1, 4, bn=False, a_func=False), # 1x1x1
nn.Sigmoid(),
)
def forward(self, img):
out = self.net(img)
return outloss:
与原文不同,在生成损失上加了mse
gen_loss_d = self.adversarial_loss(torch.squeeze(gen_output), real_label)
gen_loss_a = self.adversarial_loss(torch.squeeze(gen_output_a), real_label)
mse_loss = self.mse_loss(gen_target_batch, target_batch)完整训练测试代码:GitHub
3.结果
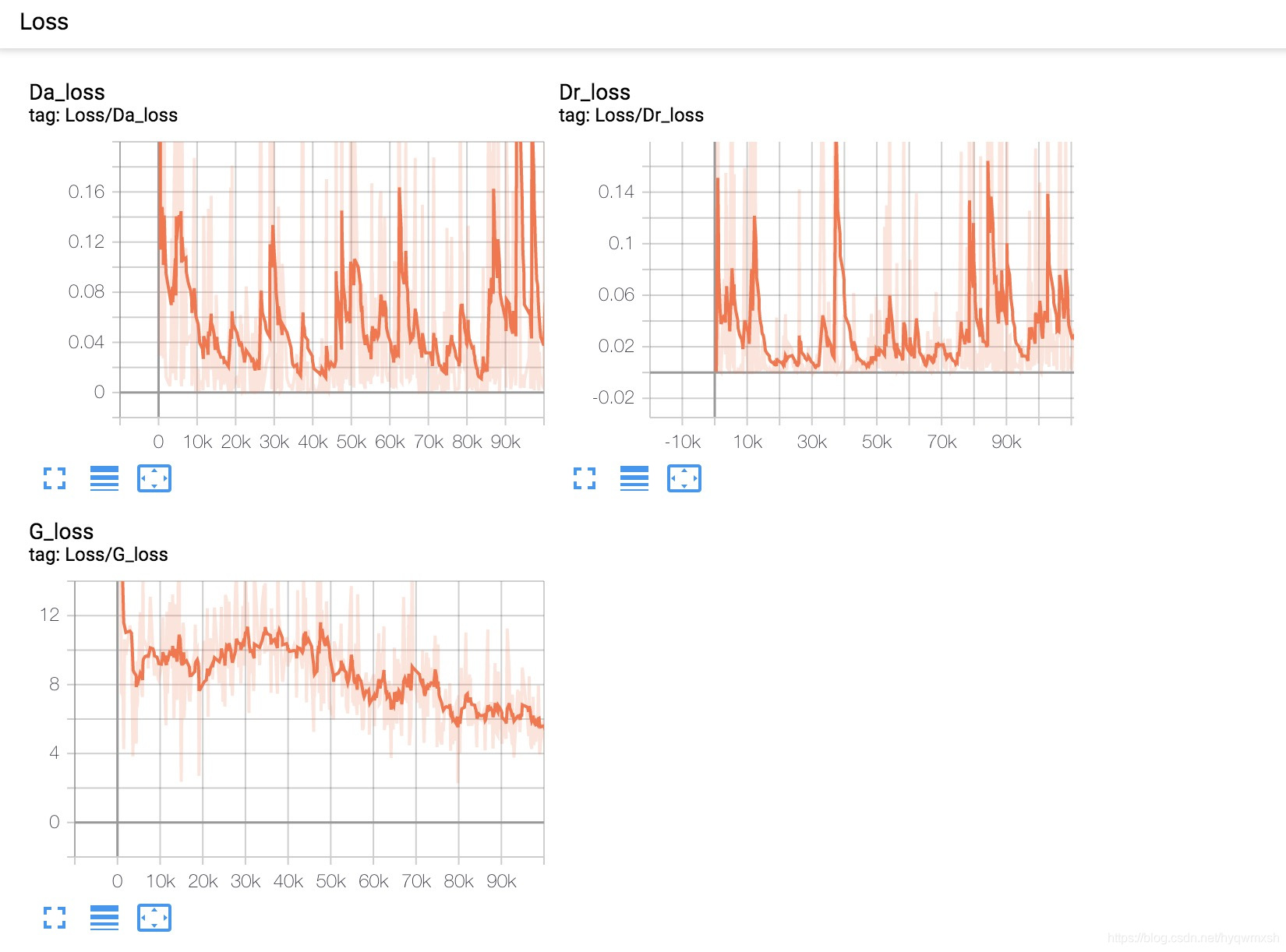
loss曲线:
生成过程:

validation:

原文内效果:

没有得到过原文图中这种效果,复现的细节基本是没有的,边缘也基本模糊不清,不清楚文章有什么trick,文章也比较老了,仅供娱乐学习Gan吧~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









