






目录
一.前言
在当今数据驱动的时代,数据分析已成为各行各业不可或缺的一部分。无论是商业决策、科学研究还是日常生活,数据都以其独特的方式揭示着事物的本质和规律。为了更好地理解和利用这些数据,我们需要借助强大的数据分析工具和技术。而pandas,作为一款基于Python的数据分析库,凭借其高效、灵活和易于使用的特点,成为了数据分析师和数据科学家的首选工具之一。
二.安装步骤
pip install pandaspip install numpy
Pandas的作用
数据处理与分析:
- Pandas是Python中专门用于数据处理和分析的库,提供了灵活且高效的数据结构(如DataFrame和Series),能够快速处理各种数据类型(如CSV、Excel、SQL数据库等)。
- 提供了数据清洗、数据筛选、数据统计、数据可视化等功能,是数据科学家和数据分析师进行数据探索和分析的强大工具。
- 数据结构:
- Pandas中的DataFrame是其最重要的数据结构,它是一个二维的、大小可变且可以包含异构类型列的表格结构。
- Series则是一维的标签数组,能够保存任何数据类型。
- 数据读取与写入:
- Pandas可以读取和写入多种数据格式,如CSV、Excel、SQL等,方便用户与各种数据源进行交互。
- 数据分组与聚合:
- Pandas支持通过groupby()函数对数据进行分组,并使用聚合函数对数据进行统计分析。
- 时间序列分析:
- Pandas对时间序列数据提供了强大的支持,可以方便地进行时间序列分析、滑动窗口分析等操作。
- 数据可视化:
- Pandas可以与Matplotlib等可视化工具结合,绘制各种图表,如折线图、散点图、柱状图等,帮助用户更好地理解数据。
NumPy的作用
- 数值计算:
- NumPy是Python中用于数值计算的库,提供了高性能的多维数组对象(ndarray)以及对这些数组进行操作的函数。
- 提供了大量的数学函数,包括线性代数、傅里叶变换、随机数生成等,能够高效地处理大规模数据集。
- 数组操作:
- NumPy的核心是ndarray对象,它是一个多维数组,可以进行快速的数值计算和数组操作。
- 提供了丰富的数组操作函数,如索引、切片、形状变换、数学运算、逻辑运算等。
- 矩阵运算:
- NumPy提供了各种矩阵运算,如矩阵乘法、转置和分解等,方便进行矩阵运算,满足不同场景的需求。
- 存储和处理大型矩阵:
- NumPy是一个开源的数值计算扩展,可以用来存储和处理大型矩阵。它采用了NumPy中的嵌套列表结构,比Python本身的列表结构要高效得多。
- 科学计算:
- NumPy广泛应用于科学计算领域,如物理学、生物学、化学、地理学等。它提供了许多科学计算的工具和函数,可以进行数据分析、建模、模拟等。
- 计算速度快:
- NumPy库的计算速度非常快,甚至比Python内置的简单运算还要快,这使得它成为很多科学计算和数据分析的首选工具。
三.处理不同数据源的数据
1.1 数据读取
一般情况下,数据文件多为_csv文件与,那么若需要用Python进行分析则需要的导入库才能读取文件,一般读取数据文件多用pandas库,而在安装Anaconda以自带库,不用在另外下载。
我们运行程序时也需要声明导入所需库。
import pandas as pd
import numpy as np利用pandas读取_csv文件
以某地区房屋销售数据的数据(数据格式为_csv)为例进行演示
导入数据
data=pd.read_csv('某地区房屋销售数据.csv'读取出“某地区房屋销售数据”的数据
import pandas as pd
housesale= pd.read_csv('D:/sdf/某地区房屋销售数据.csv', encoding='gbk')
print(housesale)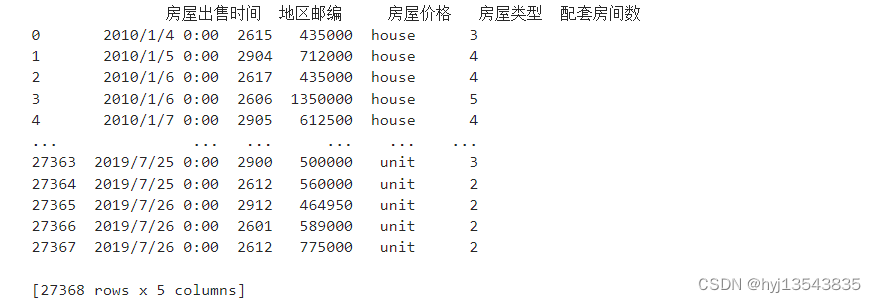
利用pandas读取_csv文件
data= pd.read.csv('某地区房屋销售数据.csv')在导入数据时可能会因为我们的数据文档读取失败的状态,出现以下状态,
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc4 in position 45: invalid continuation byte在出现上面这种状态时,我们可以告诉他我们的文件格式
data= pd.read_csv('某地区房屋销售数据.csv', encoding='gbk')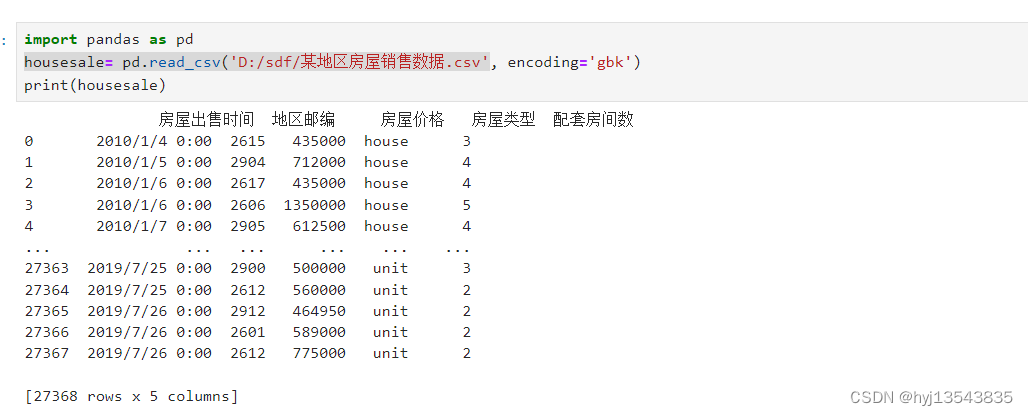
四.DataFrame的使用
1.1 DataFrame的常用属性
对与信息表的属性查找,例如:
维度、形状、所有特征名称
ndim、shape、columns的作用分别如下:
- ndim:
- 作用:ndim属性用于获取数组的维数。它返回一个整数,表示数组有多少个维度。
- 示例:
- 一维数组的ndim为1。
- 二维数组的ndim为2。
- 三维数组的ndim为3,以此类推。
- 信息:ndim是NumPy库中的一个属性,对于理解数组的结构和进行多维计算非常重要。
- shape:
- 作用:shape属性返回一个表示数组在每个维度上大小的元组。这个元组中的元素个数与数组的维度数相同,每个元素表示对应维度上的大小(即该维度上的元素个数)。
- 示例:
- 对于一维数组,shape返回一个只包含一个元素的元组,表示数组的长度。
- 对于二维数组(如矩阵),shape返回一个包含两个元素的元组,第一个元素表示行数,第二个元素表示列数。
- 对于三维数组,shape返回一个包含三个元素的元组,依次表示在三个维度上的大小。
- 信息:shape属性对于了解数组的结构、进行数组操作(如切片、重塑等)以及与其他库(如Pandas)进行交互非常重要。
- columns:
- 作用:columns是Pandas库中DataFrame对象的一个属性,用于表示和操作数据集中的列或字段。它不是一个NumPy的属性,而是Pandas特有的。
- 示例:
- 使用
df.columns可以查看DataFrame中所有的列名。 - 通过列名可以选择特定的列,如
df['column_name']。 - 可以使用
df.drop('column_name', axis=1)删除指定的列。 - 使用
df.rename(columns={'old_name': 'new_name'})可以重命名列。
- 使用
- 信息:columns属性是Pandas库中DataFrame对象进行列操作的基础,对于数据处理和分析非常重要。同时,Pandas库还提供了许多其他与列相关的操作,如排序、筛选、分组等。
通过使用ndim、shape、columns属性分别查看数据的维度、形状、所有特征名称
print('此数据的维度为:', housesale.ndim)
print('此数据的形状为:', housesale.shape)
print('此数据的所有特征名称为:', housesale.columns)
五.总结
Pandas是一个功能强大的Python数据分析库,它为数据科学家和数据分析师提供了便捷、高效的数据处理和分析工具。pandas提供了丰富的数据结构和数据分析函数,使得数据处理、清洗、转换和可视化等操作变得轻而易举。通过pandas,我们可以轻松地进行数据筛选、排序、分组、聚合等操作,以及构建复杂的统计分析模型。此外,pandas还与其他流行的数据分析库(如NumPy、Matplotlib和Seaborn)无缝集成,为用户提供了强大的数据分析和可视化能力。
参考文献:
 http://t.csdnimg.cn/ZoNPf
http://t.csdnimg.cn/ZoNPf

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









