




鸡汤
努力不一定成功,但是放弃很轻松
概念复习
1.get和post
- get 输入www.baidu.com,按下回车键,相当于对百度服务器发送了get请求,只从服务器获取数据,而没有对服务器产生影响。右键–>查看网页源代码,看到html开头的文件就是服务器相应返回的内容,经过浏览器的一番处理就变成了我们看到的网页界面。查看网页源代码,
特点:一般情况下只从服务器获取数据 没有对服务器产生影响,所有的请求的参数都会在url地址中显示出来 - post 可能会对服务器产生影响,指的是让服务器的返回值发生变化。比如打开有道翻译,输入“人工智能”进行翻译,但是在查看网页源代码中,并未找到人工智能的几个字的搜索结果。Network是服务器与浏览器的交互记录,他们之间所进行的传递都记录在Network里,找到translate标签开头的文件,在Form Data中可以看到“人工智能”。
特点:请求参数不会出现在url地址里面,而是会隐藏在From表单里,如登录网页输入账号密码,需要发到服务器进行验证。
2.URL 全球统一资源定位符
https://new.qq.com/omn/TWF20200/TWF2020032502924000.html
https: 网络协议
new.qq.com 就理解为有一台主机名叫new.qq.com在qq.com域名之下
omn/TWF20200/TWF2020032502924000.html 访问资源路径
3.User-Agent
浏览网页发送请求,在请求头里都会加上User-Agent,让开发者认为是人在访问,而不是机器在访问网页,伪装成用户访问。访问网页的时候服务器第一步会检查User-Agent,避免给服务器产生压力,以百度为例找到请求头的步骤:网页空白地方右键–>检查–>#Network–>All–>名称:www.baidu.com–>headers–>request headers–>User-Agent
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
请求头中包含了操作系统和浏览器的版本
作用:记录了操作系统和浏览器相关信息 为了让用户更好的获取HTML页面的效果 一般是反反爬的第一步
# 没有加请求头的访问
import requests
url = "https://www.baidu.com/" #-->把百度的网址赋值给url
res = requests.get(url) #-->发起访问网站请求
header = res.request.headers
print(header) #-->返回的结果中"python-requests/2.26.0",明目张胆的告诉服务器是程序在访问网页,
运行的结果:
{'User-Agent': 'python-requests/2.26.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
可以看到是python程序进行的访问网页的操作。
如果加上请求头
# 加上请求头的访问
import requests
url = "https://www.baidu.com/" #-->把百度的网址赋值给url
headers = { #-->网页空白地方右键-->检查-->
#Network-->All-->名称:www.baidu.com
#-->headers-->request headers-->User-Agent
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
res = requests.get(url, headers=headers) #-->发起访问网站请求
header = res.request.headers
print(header)
返回的结果:
{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
这时请求头为’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62’,服务器就会认为是用户在访问,为不是程序。访问网站的时候加上请求头,是反反爬的第一步,伪装成用户在访问。
4.Cookie
记录用户信息的,登录一次百度账号,关闭后再次打开会默认登录。在向一个服务器重复发送请求的时候,会自动进行登录的操作。
在爬虫里面的作用:1、反反爬(看情况)2、模拟登录(QQ登录),把别人登录过VIP的cookie信息放到请求头,就能爬取到VIP的内容。
5.Referer 记录了当前的页面是从哪个url过来的,有时加上User-Agent直接爬取网页会获取不到数据或者获取的数据有问题,可以到Referer中查看网页的来源,加上Referer
6.状态码
如果你的请求头(程序)都没啥问题 但是就是请求不到数据 或者说 请求的数据有问题 这个时候 你就去检查一下状态码
200 成功
301 资源(网页)被永久转移到其他url
404 请求的资源(网页等)不存在
500 内部服务器错误 postman(模拟请求,测试时用)
403 被服务器发现爬虫程序,请求不到数据
状态码分类:
1** 信息,服务器收到请求,需要请求者继续执行操作
2** 成功,操作被成功接收并处理
3** 重定向,需要进一步操作以完成请求
4** 客户端错误,请求包含语法错误或无法完成请求
5** 服务器错误,服务器在请求处理的过程中发生了错误
7.抓包工具(谷歌浏览器自带的)
前期用这个可以解决90%的问题
打开开发者工具:
右击–>检查 或者 按F12
Elements 元素 网页源代码 用来提取和分析数据的 可以用来分析页面结构 分析数据,呈现的是网页最终渲染的结果,做网页分析时以Elements为辅助。
Console 控制台 后期分析js代码的时候 可以通过打印来找规律 前期用不着。
Sources 资源 信息的来源 整个网站加载的资源 分析js代码的时候使用 进行调试 前期用不着。
network(很重要) 网络工作(数据抓包) 浏览器、服务器和客户端的交互记录都在network里面,客户端发起请求以及服务器返回响应在network里面都是可以找得到的。
爬虫网络请求模块
urllib模块
1.urllib是什么?
python内置的网络请求模块 ,python自带模块:re time
第三方的:requests lxml scrapy
2.为什么要学习它?.
对比学习第三方的模块
有的爬虫项目是用的urllib
有时候需要urllib+requests两者配合使用(requests请求+urllib用来保存文件)
比如保存网页上的图片,百度搜索图片,点开一张图片,点右键,查看 网页的地址
import requests #-->导入库
from urllib import request #-->第三种方法 导入urllib
url = "https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fy0.ifengimg.com%2Fd4a44fff10624b98%2F2013%2F1021" \
"%2Frdn_526466b752409.jpg&refer=http%3A%2F%2Fy0.ifengimg.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n" \
"&fmt=jpeg?sec=1630726708&t=f76bdb9ee1e7e856b7f638c44ed4102b" #-->图片的url地址
req =requests.get(url) #--> 请求访问url
f = open('code_img.png','wb') #-->以二进制的形式打开图片
f.write(req.content) #-->把图片保存为code_img
#with open('code_img2.png','wb') as f:
# f.write(req.content) #-->第二种方法,用 with open 的模式保存文件.
#request.urlretrieve(url,'code_img3.png' ) #-->第三种方法,用urllib来保存文件,将URL表示的网络对象复制到本地文件,一行代码实现.
urllib的快速入门
知识点
-
urllib.request.urlopen(“网址”) 作用 :向网站发起一个请求并获取响应
-
字节流 = response.read()
-
字符串 = response.read().decode(“utf-8”)
-
urllib.request.Request(“网址”,headers=“字典”) urlopen()不支持重构User-Agent,总的来说,如果我们在获取请求对象时,不需要过多的参数传递,我么可以直接选择urllib.request.urlopen();如果需要进一步的包装请求,则需要用urllib.request.Request()进行包装处理。,requests可以直接构造get,post请求并发起,而urllib.request只能先构造get,post请求,再发起。
-
read() 读取服务器响应的内容
-
getcode() 返回HTTP的响应码
-
geturl() 返回实际数据的URL(防止重定向问题)
函数与方法
print()是一个函数,而不是方法
函数: xxx()对应的函数,它是独立的,不需要对象的调用
方法: xxx.yyy()对应的是方法,不能独立自主,需要调用,方法是特殊的函数
urllib.request 的使用
- urllib.request.urlopen(‘网站’)
- urllib.request.urlopen(请求对象)
1、创建一个请求对象 构建UA
2、获取响应对象 通过urlopen()
3、获取响应对象的内容 read().decode(‘utf-8’)
print(res.getcode()) # 状态码
print(res.geturl()) # 请求的url地址
打印百度网页的源码(一)
import urllib.request #-->导入库
response = urllib.request.urlopen('https://www.baidu.com/') #-->urllib.request.urlopen("网址")作用 :向网站发起一个请求并获取响应
print(response.read()) #-->read()方法把响应对象里面的内容取出来,字节流 = response.read(), # 字符串 = response.read().decode("utf-8")
运行的结果:
b'<html>\r\n<head>\r\n\t<script>\r\n\t\tlocation.replace(location.href.replace("https://","http://"));\r\n\t</script>\r\n</head>\r\n<body>\r\n\t<noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>\r\n</body>\r\n</html>'
通过打印出的数据发现问题:
1、打印的数据是字节流 数据类型
2、数据不对
解决发现的打印字节流的问题
import urllib.request
response = urllib.request.urlopen('https://www.baidu.com/')
print(response.read().decode('utf-8'),type(response.read().decode('utf-8')))
返回的结果
<html>
<head>
<script>
location.replace(location.href.replace("https://","http://"));
</script>
</head>
<body>
<noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>
</body>
</html> <class 'str'>
可以看到返回的是字符串。
打印百度网页的源码(二)
步骤:
1、创建一个请求对象 构建UA
2、获取响应对象 通过urlopen()
3、获取响应对象的内容 read().decode(‘utf-8’)
import urllib.request
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
}
url = 'https://www.baidu.com/'
# 1、创建一个请求对象 构建UA
req = urllib.request.Request(url, headers=headers)
# 2、获取响应对象 通过urlopen()
res = urllib.request.urlopen(req)
# 3、获取响应对象的内容 read().decode('utf-8')
print(res.read().decode('utf-8')) #-->获得百度网站的源代码
# print(res.getcode()) # 状态码 --> 200
# print(res.geturl()) # 请求的url地址 -->https://www.baidu.com/
谨慎的程序员在做爬虫的时候,会先打印一下状态码,看状态码的返回结果。
urllib.parse 的使用
urlencode(字典) ,传入的参数是字典类型的
quote(字符串) (这个里面的参数是个字符串)
请求方式
GET 特点 :查询参数在URL地址中显示
POST 特点:在Request方法中添加data参数 urllib.request.Request(url,data=data,headers=headers)
data :表单数据以bytes类型提交,不能是str
在百度搜素“奥运会”,会向url地址发送请求,百度服务器返回相应结果,才有看到的网页界面,wd后面跟的是搜索的关键字“奥运会”,地址栏的信息显示为
但是把地址复制下来之后会变成
https://www.baidu.com/s?wd=%E5%A5%A5%E8%BF%90%E4%BC%9A&rsv_spt=1&rsv_iqid=0x89d6694e000d2297&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_dl=tb&rsv_enter=1&rsv_sug3=8&rsv_sug1=7&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&prefixsug=%25E5%25A5%25A5%25E8%25BF%2590%25E4%25BC%259A&rsp=5&inputT=2040&rsv_sug4=2438
浏览器识别不了中文,会把wd= 后面的中文字符(奥运会)进行编码
http://tool.chinaz.com/tools/urlencode.aspx #–>UrlEncode编码/解码的网站
https://www.baidu.com/s?&wd=%E5%A5%A5%E8%BF%90%E4%BC%9A #–>百度搜索奥运会的url,三个百分号包含的内容代表一个字
https://www.baidu.com/s?&wd=python #–>百度搜索python的url
浏览器会对除数字、字母和部分符号外,其他的全部使用百分号+十六进制的形式进行编码
import urllib.request
url = 'https://www.baidu.com/s?wd=%E5%A5%A5%E8%BF%90%E4%BC%9A'
url1 = 'https://www.baidu.com/s?wd=奥运会'
# urllib.request.urlopen(url) #-->正常访问,没有问题
urllib.request.urlopen(url1) #-->提示UnicodeEncodeError,编码错误
比如美国人发明的程序,要想在欧洲发行,需要转化成欧洲的ISO8859-1,要对程序进行处理;要是发行到中国,就需要转化成JBK,这样的话跨平台性比较差。为解决频繁编码的问题,就出现了Unicode(),尤其是里面的Unicode(utf-8)被称为万国码,应用范围最广。如果要在url种使用中文字符,就要对中文字符进行处理,用到urllib.parse
* urllib.parse.urlencode() -->传的是字典格式的
* urllib.parse.quote() -->传的是字符串
- 第一种传字典的方式编码
import urllib.request
import urllib.parse
r ={"wd": "奥运会"}
res = urllib.parse.urlencode(r)
print(res)
print(f'https://www.baidu.com/s?{res}')
print('https://www.baidu.com/s?' + res)
程序运行的结果
wd=%E5%A5%A5%E8%BF%90%E4%BC%9A
https://www.baidu.com/s?wd=%E5%A5%A5%E8%BF%90%E4%BC%9A
https://www.baidu.com/s?wd=%E5%A5%A5%E8%BF%90%E4%BC%9A
跟从网站上复制的url一样,复制网址,打开奥运会的搜索页面
- 第二种传字符串的方式编码
import urllib.request
import urllib.parse
s = "奥运会"
res = urllib.parse.quote(s)
print(res)
print(f'https://www.baidu.com/s?wd={res}')
程序运行的结果是
%E5%A5%A5%E8%BF%90%E4%BC%9A
https://www.baidu.com/s?wd=%E5%A5%A5%E8%BF%90%E4%BC%9A
同样得到百度搜索“奥运会”的网站页面.
- 小拓展:解码
百度搜索“王者荣耀”,进入游戏壁纸,在高清壁纸图片上点右键,检查,在Elements里可以找到该图片8种尺寸大小的图片,从这里复制src=后面的url有可能打不开图片,因为有可能出现的不是完整的链接。
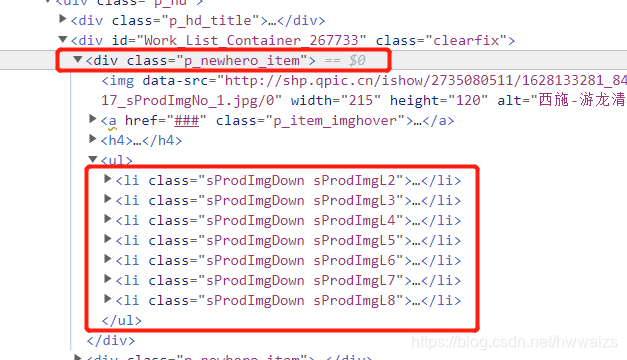
然后到Network里 刷新一下,选择All,左侧找到 worklist开头的文件,在Preview里可以找到这8张图片交互的信息
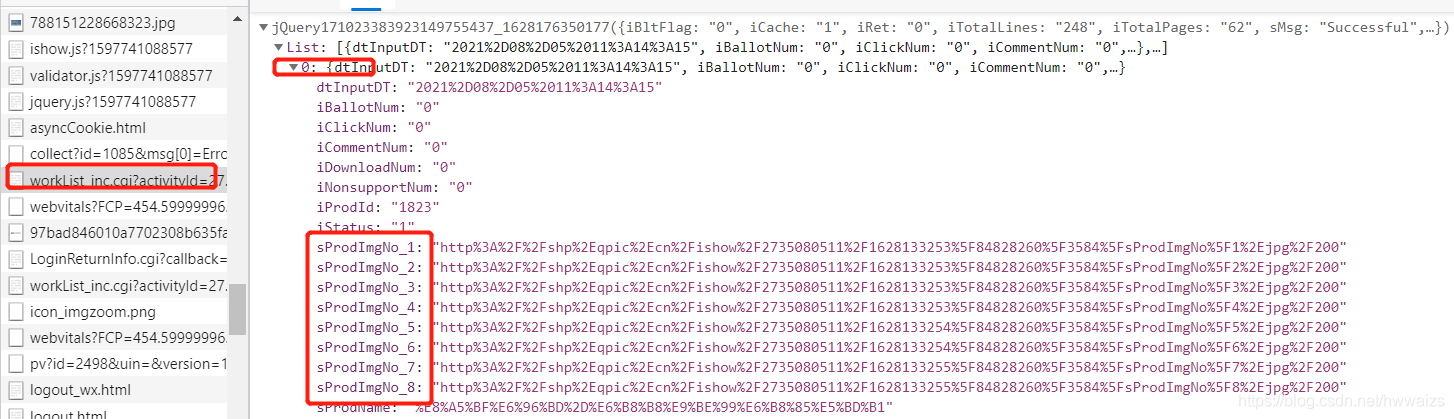
比如复制第二个后面的内容进行url解码
import urllib.request
import urllib.parse
st = "http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735080511%2F1628133253%5F84828260%5F3584%5FsProdImgNo%5F2%2Ejpg%2F200"
set = urllib.parse.unquote(st)
print(set)
运行的结果是
http://shp.qpic.cn/ishow/2735080511/1628133253_84828260_3584_sProdImgNo_2.jpg/200
复制运行后url,到网页地址栏打开之后是第二个图片,解码成功
- 总结:以后我们看到一些请求的目标url、图片的url等等 这些url里面有% + 十六进制的数据格式 我们就要想要urllib.parse
urllib案例练习
爬取百度贴吧
目标
爬取贴吧数据
需求
1、输入要爬取的贴吧的名称
2、要做翻页的处理 指定起始页和终止页
3、把爬取下来的每一页保存到本地 命名为1.html 2.html
思路分析(非常重要)
1.页面分析
· 1)输入要爬取的贴吧的主题 input
· 2)翻页处理,这里认为的把复制url里面的%E5%A5%A5%E8%BF%90%E4%BC%9A改为了奥运会
https://tieba.baidu.com/f?ie=utf-8&kw=奥运会&fr=search 第一页-->去掉了=utf-8,
把第一页改为pn=0
https://tieba.baidu.com/f?kw=奥运会&pn=0 第一页 50*0(n-1)
https://tieba.baidu.com/f?kw=奥运会&pn=50 第二页 50*1
https://tieba.baidu.com/f?kw=奥运会&pn=100 第三页 50*2
https://tieba.baidu.com/f?kw=奥运会&pn=150 第四页
https://tieba.baidu.com/f?kw=奥运会&pn=200 第五页
规律:pn = (n-1) * 50
· 3)发送请求,获得相应,创造请求对象,发送请求
· 4)保存网站,把爬取的网页保存到本地,爬取到的网页跟网站一样,会有图片没有显示,因为网站上的图片是慢慢渲染出来的
2.实现步骤(代码)
1.代码01
import urllib.parse
import urllib.request #--> 导入两个模块
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
} #--> 写入请求头
title = input("请输入要爬取的关键字:") #--> 输入要爬取贴吧的主题
start = int(input("请输入开始页:")) #--> 指定搜索贴吧开始的页码
end = int(input("请输入结束页:")) #--> 指定搜索贴吧结束的页码
# https://tieba.baidu.com/f?kw=奥运会&pn=0 #--> 拼接url的示例
kw = {"kw": title} #--> 创建字典用于中文字符的编码
result = urllib.parse.urlencode(kw) #--> 对中文字符进行编码
for i in range(start, end+1):
pn = (i-1)*50 #--> 用i遍历起始页,获取pn的数值
# print(pn)
com = f"https://tieba.baidu.com/f?{result}&pn={pn}" #--> 拼接url
# print
# 发送请求,获取响应
req = urllib.request.Request(com, headers=headers) #--> 创建请求对象,构建UA
res = urllib.request.urlopen(req) #--> 获取响应对象 通过urlopen()
html = res.read().decode('utf-8') #--> 获取响应对象的内容
filename = f"第{i}页.html" #-->拼接保存的文件
# 写入数据
with open(filename, "w", encoding='utf-8') as f:
f.write(html)
print(f"正在爬取第{i}页")
print("爬取结束!")
程序运行的结果是
请输入要爬取的关键字:奥运会
请输入开始页:1
请输入结束页:3
正在爬取第1页
正在爬取第2页
正在爬取第3页
爬取结束!
Process finished with exit code 0
运行结束后保存了3个html文件
2.代码改写—02函数
01代码是按照页面分析的逻辑,从上到下写的,封装性不是很好,不太好修改某个值,现在把普通式的编程方式改为函数式的编程方式。函数是python里面的一个对象
内置的模块:urllib re
函数式编程:
内置的对象:int str list --> 数值,字符串,列表,多次调用,function里存的是逻辑、代码,可以包含上述之外的元组,字典等,存放的代码非常灵活,把函数封装好后可以无限次的调用。
按照代码01的逻辑,改为函数式变成后可以分为几个部分
#读取页面
def read_page():
pass
#写入、保存文件
def save_page()
pass
#主函数,完成两个函数的调用,完成读写之外,拼接的逻辑放进去,两个函数没有实现的功能
def main()
pass
#判断,调用主函数
if __name__ == '__main__': #-->整个程序的入口,程序从这里执行
main()
完成的功能:获取源代码,解析数据,把数据保存下来
读取网页源码的函数,搭好架子,定义函数,用来获取网页源码
import urllib.parse
import urllib.request
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
#读取页面
def read_page(com):#-->读取页面的时候需要向URL传参数的,用函数传参的方式传递进去
req = urllib.request.Request(com, headers=headers) # --> 创建请求对象,构建UA
res = urllib.request.urlopen(req) # --> 获取响应对象 通过urlopen()
html = res.read().decode('utf-8') # --> 获取响应对象的内容
return html
#读取完页面后把获取的网页源代码,作为函数的返回值,返回给return
#写入、保存文件
def save_page(filename, html): #-->filename,html 都作为参数传递给函数
with open(filename, "w", encoding='utf-8') as f:
f.write(html)
#主函数,完成两个函数的调用,完成读写之外,拼接的逻辑放进去,两个函数没有实现的功能
def main():
title = input("请输入要爬取的关键字:") # --> 输入要爬取贴吧的主题
start = int(input("请输入开始页:")) # --> 指定搜索贴吧开始的页码
end = int(input("请输入结束页:")) # --> 指定搜索贴吧结束的页码
# https://tieba.baidu.com/f?kw=奥运会&pn=0 #--> 拼接url的示例
kw = {"kw": title} # --> 创建字典用于中文字符的编码
result = urllib.parse.urlencode(kw) # --> 对中文字符进行编码
for i in range(start, end + 1):
pn = (i - 1) * 50 # --> 用i遍历起始页,获取pn的数值
# print(pn)
com = f"https://tieba.baidu.com/f?{result}&pn={pn}" # --> 拼接url
html = read_page(com)
filename = f"第0{i}页.html" # -->拼接保存的文件
save_page(filename, html)
print(f"正在爬取第{i}页")
#判断,调用主函数
if __name__ == '__main__': #-->整个程序的入口,程序从这里执行
main()
运行的结果跟代码01一样,第一个函数获取网页源代码,二个函数保存网址
第三个是联系前两个函数,是链接前两个的桥梁
把每一部分代码封装好,调用函数,传递实际获取的参数。
3.代码改写—03面向对象
先创建好程序的的框架,在往每一个部分里填入相应的内容
class BaiduSpider(object):
def __init__(self): #——>初始化方法
pass
# 读取页面
def read_page(self):
pass
# 写入文件
def save_page(self):
pass
def main(self): #——>把剩下的没有写的逻辑放进去,调用两个函数
pass
if __name__ == '__main__':
spider = BaiduSpider() #——>实例化对象
spider.main()
导入函数,输入请求头,把读取页面,写入文件,主函数补充完整。
import urllib.parse
import urllib.request
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
class BaiduSpider(object):
def __init__(self): #——>初始化方法
pass
# 读取页面
def read_page(self, com):
req = urllib.request.Request(com, headers=headers) # --> 创建请求对象,构建UA
res = urllib.request.urlopen(req) # --> 获取响应对象 通过urlopen()
html = res.read().decode('utf-8') # --> 获取响应对象的内容
return html
# 写入文件
def save_page(self, filename, html):
with open(filename, "w", encoding='utf-8') as f:
f.write(html)
def main(self): #——>把剩下的没有写的逻辑放进去,调用两个函数
title = input("请输入要爬取的关键字:") # --> 输入要爬取贴吧的主题
start = int(input("请输入开始页:")) # --> 指定搜索贴吧开始的页码
end = int(input("请输入结束页:")) # --> 指定搜索贴吧结束的页码
# https://tieba.baidu.com/f?kw=奥运会&pn=0 #--> 拼接url的示例
kw = {"kw": title} # --> 创建字典用于中文字符的编码
result = urllib.parse.urlencode(kw) # --> 对中文字符进行编码
for i in range(start, end + 1):
pn = (i - 1) * 50 # --> 用i遍历起始页,获取pn的数值
# print(pn)
com = f"https://tieba.baidu.com/f?{result}&pn={pn}" # --> 拼接url
html = self.read_page(com)
filename = f"第0{i}页.html" # -->拼接保存的文件
self.save_page(filename, html)
print(f"正在爬取第{i}页")
if __name__ == '__main__':
spider = BaiduSpider() #——>实例化对象
spider.main()
requests模块
快捷键
Ctrl + D 复制选定的区域或行
Ctrl + Y 删除选定的行
Ctrl + Alt + L 代码格式化
Ctrl + Alt + O 优化导入(去掉用不到的包导入)
Ctrl + 鼠标 简介/进入代码定义
Ctrl + / 行注释 、取消注释
Ctrl + 左方括号 快速跳到代码开头
Ctrl + 右方括号 快速跳到代码末尾


















 2382
2382




 到【灌水乐园】发言
到【灌水乐园】发言







