







 这篇博客详细梳理了机器学习中逻辑回归的运用,特别提到了使用sklearn库的LogisticRegression模型。文章核心内容包括准确率、精确率、召回率、F1值以及ROC/AUC等关键评估指标的探讨。
这篇博客详细梳理了机器学习中逻辑回归的运用,特别提到了使用sklearn库的LogisticRegression模型。文章核心内容包括准确率、精确率、召回率、F1值以及ROC/AUC等关键评估指标的探讨。
重点
from sklearn.linear_model import LogisticRegression
sklearn对常用机器学习方法都进行了封装:包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn.metrics import classification_report # 模型评估
全部代码:
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn.metrics import classification_report # 模型评估
# ----------------- 线性逻辑回归 -----------------
# 加载数据
iris = datasets.load_iris()
x = iris.data
y = iris.target
x = x[y < 2, :2] # 使用前两个特征
y = y[y < 2]
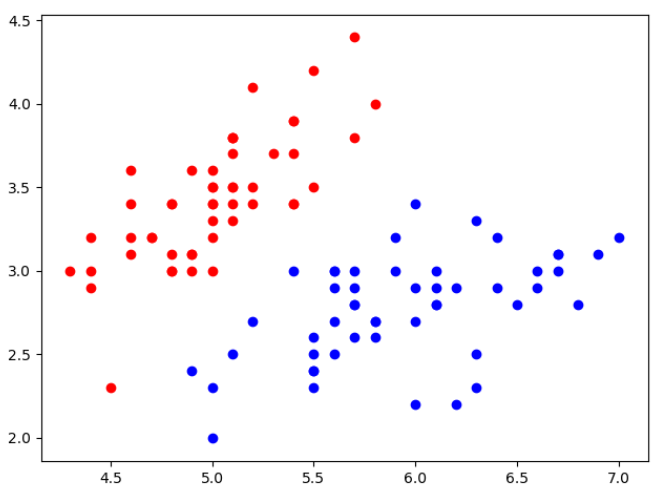
# 绘制图像
plt.scatter(x[y == 0, 0], x[y == 0, 1], color='red')
plt.scatter(x[y == 1, 0], x[y == 1, 1], color='blue')
plt.show()
# 切分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=666)
# 训练逻辑回归模型
logistic = linear_model.LogisticRegression()
logistic.fit(x_train, y_train)
# 预测
prepro = logistic.predict_proba(x_test)
acc = logistic.score(x_test, y_test) # 准确率
print("score is :%s" % acc)
print("actual prob is:")
print(prepro)
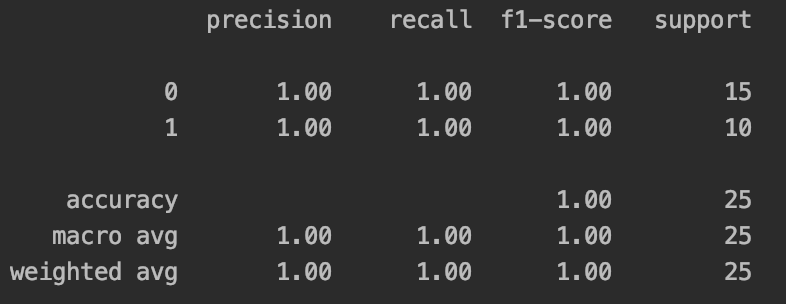
# 评估
prediction = logistic.predict(x_test)
print(classification_report(y_test, prediction))
# print(classification_report(y_test,prepro))
# ----------------- 非线性逻辑回归 -----------------
# ref:https://www.jb51.net/article/188355.htm
import numpy as np
from sklearn import linear_model
from sklearn.datasets import make_gaussian_quantiles
from sklearn.preprocessing import PolynomialFeatures
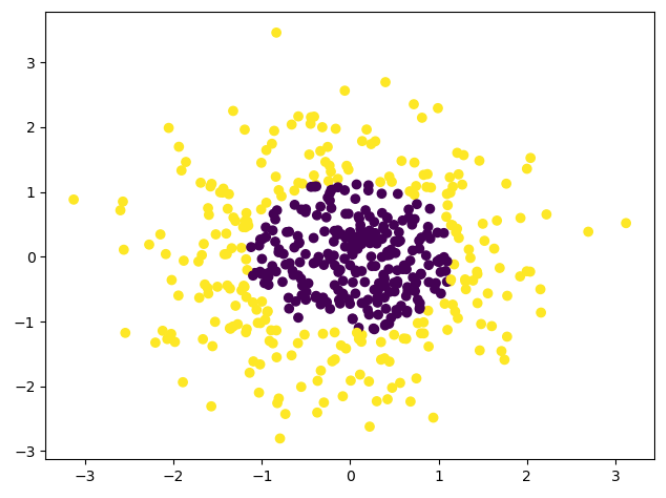
# 生成正太分布数据,500个样本,2个特征,2类
x_data, y_data = make_gaussian_quantiles(n_samples=500, n_features=2, n_classes=2)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
# 进行特征的构造
poly_reg = PolynomialFeatures(degree=5)
# 特征处理
x_poly = poly_reg.fit_transform(x_data)
# 逻辑回归模型
logistic = linear_model.LogisticRegression()
logistic.fit(x_poly, y_data)
acc = logistic.score(x_poly, y_data)
print("score is :%s" % acc)
prediction = logistic.predict(x_poly)
print(classification_report(y_data, prediction))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









