






 本文详细介绍了Kafka的组件、搭建过程及关键特性,包括生产者、消费者、broker、Zookeeper和topic。强调了搭建时硬件配置的影响,以及分区和副本在确保负载均衡和容错性中的作用。此外,讨论了生产者发送消息的策略、消费者的消费模式以及部分核心原理,如数据删除和读取机制。
本文详细介绍了Kafka的组件、搭建过程及关键特性,包括生产者、消费者、broker、Zookeeper和topic。强调了搭建时硬件配置的影响,以及分区和副本在确保负载均衡和容错性中的作用。此外,讨论了生产者发送消息的策略、消费者的消费模式以及部分核心原理,如数据删除和读取机制。
看过太多次kafka的内容,每次看过都会忘记。这次详细记录下自己记得已经理解的东西。借鉴于<kafka权威指南>
1、kafka组成
kafka包括生产者、消费者、broker、zk、topic。
2、搭建kafka
影响到kafka效率的有网络的吞吐量、硬盘吞吐量(SSD)、CPU的性能、内存的大小。一台机器的内存只需要留一点点给系统用,其他的内存可以给kafka用来做页面缓存,所以不建议kafka和其他项目混合搭建在一套机器内。
多个broker就构成了kafka集群,节点需要奇数个,便于使用一致性算法进行选举等,但是也不能多于7个,会导致一致性算法耗时太久,耽误时间。搭建过程中,可以设置topic消息保存的时长以及多大的量,两个标准都符合就会进行清理。
kafka使用zk保存元数据和消费者信息 2.1.3
3、topic
生产者发送消息,消费者接受消息。新建topic的时候,设置partition数量,数量越大能够应付的消费者group就越多,有利于增加消息的处理速度,增加消费者的吞吐量。所有partition可以都在一个broker里面,如果有多个broker,就会均匀分到多个broker减少broker的处理压力。同时设置副本数量,此间所有的topic副本,每个分区的副本都在不同的broker里面。按照顺序或者轮询进行区分配。例如有3个brokerABC,topicA划分了6个partitionABCDEF,2个副本partitionA1A2,则分配可能是这样的:
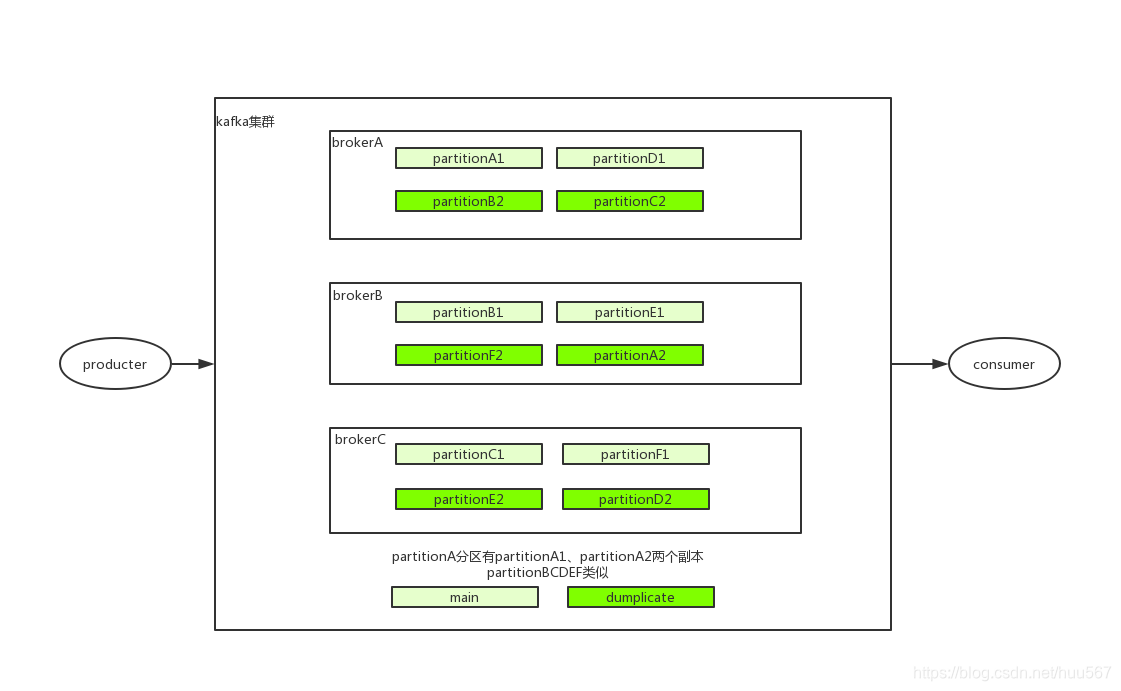
每个区的副本不在同一个borker上,防止broker挂了之后都挂了。这就是分区。topicA的分区个数必须要大于broker个数才能保证负载均衡。每当加入分区或者减少分区(禁止),都会导致rebalance
分区数无限制1-N都可以,但是分区副本数有限制,不能超过broker数量。还好此图副本只有两个,不然超过三个就大脸了。因为多了则会有至少2个副本在同一个broker上,如果挂了,就都挂了没有意义,所以kafka给禁止了。
Error while executing topic command : Replication factor: 20 larger than available brokers: 3.
4、生产者
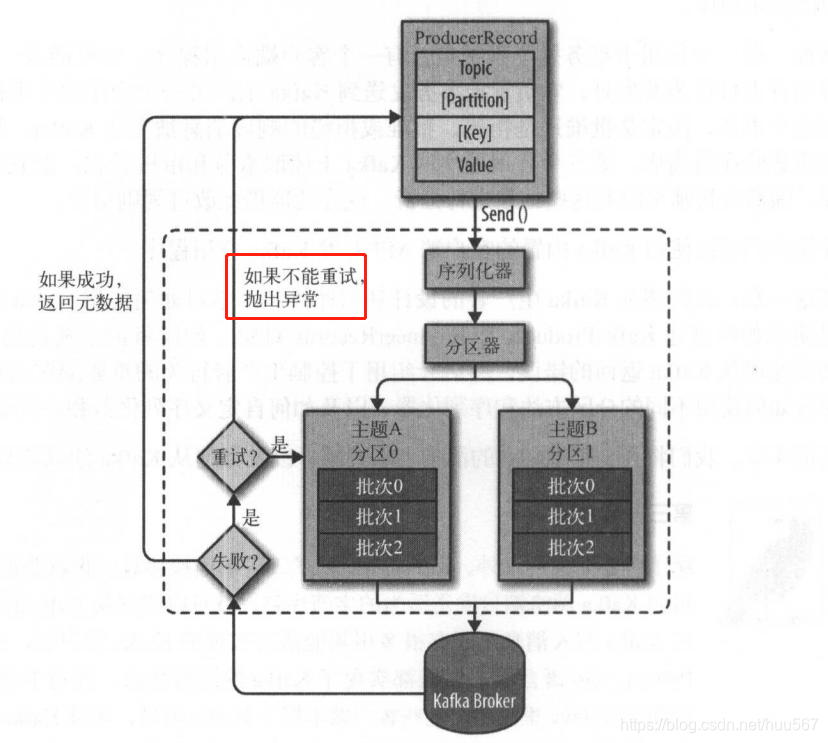
生产者发送内容为:主题、值、键。
消息都是均匀的分布到分区上,除非要指定分区。生产者发送数据可以指定要发送的区(带键),如果没指定(键为null),就会借助分区器判断去哪个区,并做好标记(键),同一个键的消息都是发往同一个区域的消息,可以设置累积多少个进行发送,或者达到什么时候进行发送,提高吞吐量,默认情况下某个时间点到了只有一个消息也会发送出去。
发送有三种方式:直接发送,扔出去就算了;同步发送,使用Feature的get方法进行等待;异步发送,使用回调函数接受broker返回的数据。接收到失败的数据,可以进行重试,不过要配置重试次数。
broker接受数据的准确性也有三种方式由ack参数确定:0接收到就行,1main确定接收到才行,all所有的副本都同步了才行。
发送需要序列化成byte数组才能发送哦。
5、消费者
消费者进行消息消费。消费者组内可以有多个消费者,组内每个消费者负责不同的分区,可能是1:1或者1:N,如果消费者数量大于分区数量,那就只能空闲在那里了。至于哪个消费者负责哪个(些)分区,由第一个加入组的消费者分配,它从“”群组协调器“”也就是某个broker获得组内消费者的信息,然后按照顺序或者轮询进行区分配。当组内加入或者减少消费者的时候,就会出现rebalance,区重新分配给消费者,会带来一定的延迟,和数据误差。消费者A可以加入一个群组,也可以不加入指定读哪个区,但是如果加入了分区,呵呵呵尴尬了,就会有新数据在别的区而漏掉了。
消费者每次读取分区里面,未被处理的一批消息,也就是偏移量以后的数据。
问题是,消费者提交给_consumer_offset 特殊主题的偏移消息,到底是先处理再提交还是先提交再处理?只有先处理再提交才会在rebalance之后出现重复处理的情况,后者不会出现。
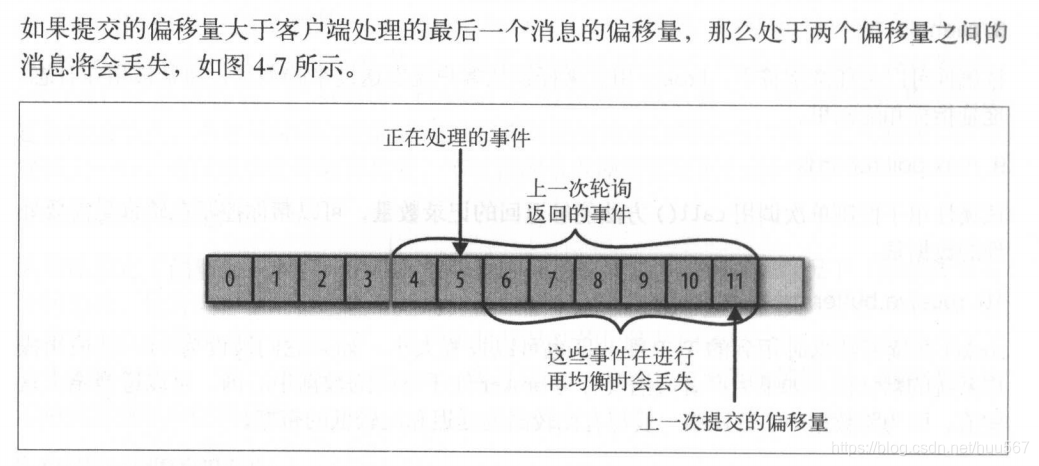
提交有几种方式:1是周期提交,在提交之前出现问题会导致重复处理;2程序同步提交,会导致代码阻塞,必需要知道结果并确定要不要重试,避免数据重复处理;3异步提交,如果出现了错误不会重复处理,可能有更大的偏移量被提交了,另外一次错误并不代表后续不会出现正确结果。4先异步,原因如3,出现了异常如rebalance等,再同步重试等,保证最后一次正常。
kafka有提供api来从特定的位置读取数据。也就是可以重复读取或者跳过某些记录。
读取数据的时候需要反序列化,但是需要和发送方的序列化方法一致,所以发送发最好不要自己瞎写,用现成的最保险。
消费者主动拉取数据的!告知broker 偏移、size、累积时间等。
6、部分原理
broker在zk上注册临时节点,第一个注册的就是控制器,控制器挂了之后后备的节点最小的作为新控制器,控制器似乎只用于分区分配??。副分区探测不到主分区,就会进行选举,找zk,先来的做主。
消费者所有的读与生产者所有的写都是在主分区之上,副分区只用来同步数据。
生产者和消费者客户端调用broker,他们知道自己关联的区在哪个broker上,可以发送元数据请求给所有broker,符合要求的自己发回来,但一般是通过元数据里面的分区、副本等直接发送到指定broker不用劳神费力,另外需要周期性的刷新元数据保证rebalance之后的分区信息是最新的。
消费者可以指定达到多少数据、达到多少时间就返回,前文有提及。注意水位线。
最常见的三个请求:元数据请求、发送数据请求、获取数据请求
以前偏移量保存在zk上,新版本都保存在特殊主题上,前文有提及。
broker进行数据删除和读取的时候,数据放在一个文件里操作起来会非常麻烦,所有会分为好几个片段。当片段达到预定的大小就会新开片段并创建新的index索引文件。broker通过index找到文件并发送给请求的consumer。老片段达到了时间(7天等)就可以清理了。
kafka通过0缓存、压缩打包等方式提高吞吐量,减少自己保存数据IO、序列化反序列化等操作。
主副本挂了之后选举有两种情况:
1完全首领选举:副本数据与主副本一致
2不完全首领选举:副本数据与主副本不一致。
1的情况满足ap,马上恢复可用,但是数据不一致。有的银行系统选择2满足cp,等着挂掉的broker恢复,情愿几个小时不进行业务处理
当broker给客户端返回失败,客户端需要稳健一点,进行重试。区别对待,有的错误就略过了,试了也是白搭。
文件:分区文件、索引文件
如何保证数据按照顺序被读取?写入同一个分区。
所有副本复制完毕才是真正的写入broker成功,consumer也只能读取isr都成功的数据
主分区节点挂了之后,备份分区节点顶上,如果备份分区不同步,要么强顶,要么等着主分区恢复,对数据要求高的如银行系统,可能会选择等待好几个小时来等主分区恢复。

















 1875
1875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









