




Kafka 是由 LinkedIn 开发的一个分布式的消息系统,使用 Scala 编写,它以可水平扩展和高吞吐率而被广泛使用。Kafka 是一种分布式的,基于发布 / 订阅的消息系统。主要设计目标如下:
- 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条以上消息的传输。
- 支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
Kafka 架构如下所示:
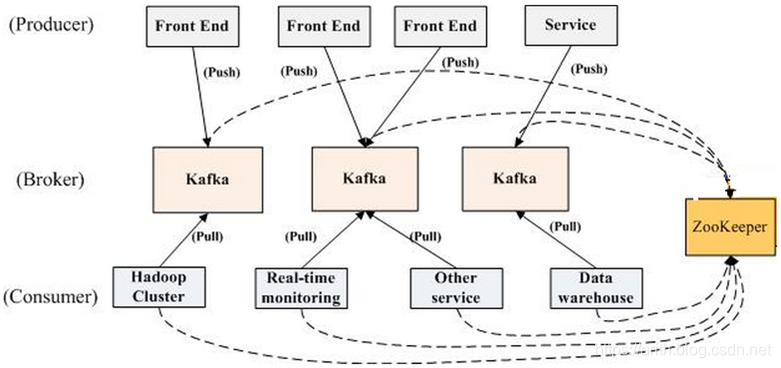
一个典型的 Kafka 集群中包含若干 Producer,若干 broker,若干 Consumer Group,以及一个 Zookeeper 集群。Kafka 通过 Zookeeper 管理集群配置,选举 leader,以及在 Consumer Group 发生变化时进行 rebalance。Producer 使用 push 模式将消息发布到 broker,Consumer 使用 pull 模式从 broker 订阅并消费消息,Consumer 使用 ZooKeeper 记录 partition 消费 offset。
为什么要使用消息系统呢?
- 解耦
- 消息格式相当于同步调用里的接口设计,在保证接口不变的基础上,生产者和消费者可以独立的扩展和修改。
- broker 负责管理生产者和消费者之间的映射关系,消费者的增加和减少不需要生产者做任何改动。
- 冗余:消息未处理完成之前,会一直保存在消息系统中,避免数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2013
2013





 到【灌水乐园】发言
到【灌水乐园】发言







