



 本文介绍了一种使用单一生成对抗网络进行多模态图像到图像翻译的方法,由南方科技大学计算机系研究者提出。该技术能将一类图片转换为另一类图片,如将普通马的图片转化为斑马图片,或实现图片去模糊处理。网络结构精简,仅使用一个生成器和判别器,提高了泛化性和简化了网络。
本文介绍了一种使用单一生成对抗网络进行多模态图像到图像翻译的方法,由南方科技大学计算机系研究者提出。该技术能将一类图片转换为另一类图片,如将普通马的图片转化为斑马图片,或实现图片去模糊处理。网络结构精简,仅使用一个生成器和判别器,提高了泛化性和简化了网络。
Multimodal Image-to-Image Translation via a Single Generative Adversarial Network
Shihua Huang, Cheng He, Ran Cheng
文章简介
三位作者均来自南方科技大学计算机系,这篇文章从哪里来的?我真不记得了,也就几天前的事吧,因为订阅了很多谷歌学者以及公众号,每天推送很多文章,实在想不起来在什么地方看到的这篇。谷歌了一下,目前也只是在arXiv上传了,估计是投了什么会议,还没有出结果吧。而且,我突然间发现,这篇文章居然就是旁边程然老师(南方科技大学计算机系教授)实验室的文章,哈哈哈,太巧了。
应用场景:Image-to-Image(I2I)
这个应用场景我是第一次接触,整个任务的目标是用某一类图片生成另一类或者另外几类图片,源域和目标域是不同的。比如根据一匹普通的马的图片,生成斑马的图片,或者输入一只狗的图片,生成猫、老虎等其他种类的图片,也可以是用来实现图片去模糊处理。

算法介绍
看完整篇文章,不难发现文章本身的创新点不足,用的结构也是别人提出过的,最大的创新点在于对别人的网络结构的精简,可能这也是文章目前还没有被会议接收的原因。
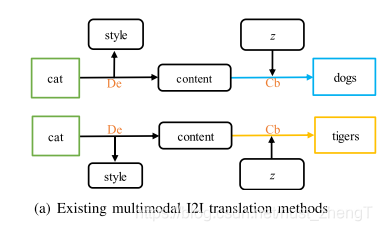
网络主要分为两个部分,第一部分是图片的隐藏层特征提取,分别用两个Encoder提取出图片的content和style,content包含的是图片本身的一些信息,包括纹理、边缘、物体特征等信息,style包含的就是图片中目标的类型,和lable的性质相似。
在提取完源图片的domain-invariant特征之后,就要进入生成部分。生成是在之前提取的content的基础之上进行的,相当于content是原图片和目标图片的相同部分,这是可以直接保留作为生成部分的seed,然后计入目标图片的lable以及隐藏变量,从而生成其他类型的图片。生成部分采用的是对抗生成模型。

整个网络结构和之前的人做的工作最大的区别在于,作者只用了一个generator和discriminator,即生成不同域的图片也是公用同一个GAN网络,这样网络泛化性更好,网络结构也更简单。
实验结果


















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









