







某物APP的一道面试真题,B+树和B树的区别,为什么mysql的索引使用B+树也不是B数。
之前我们记录了一篇数据结构的的在线演示的网站,具体见这篇 ,接下来我们分析一下,为什么mysql使用B+树做索引。
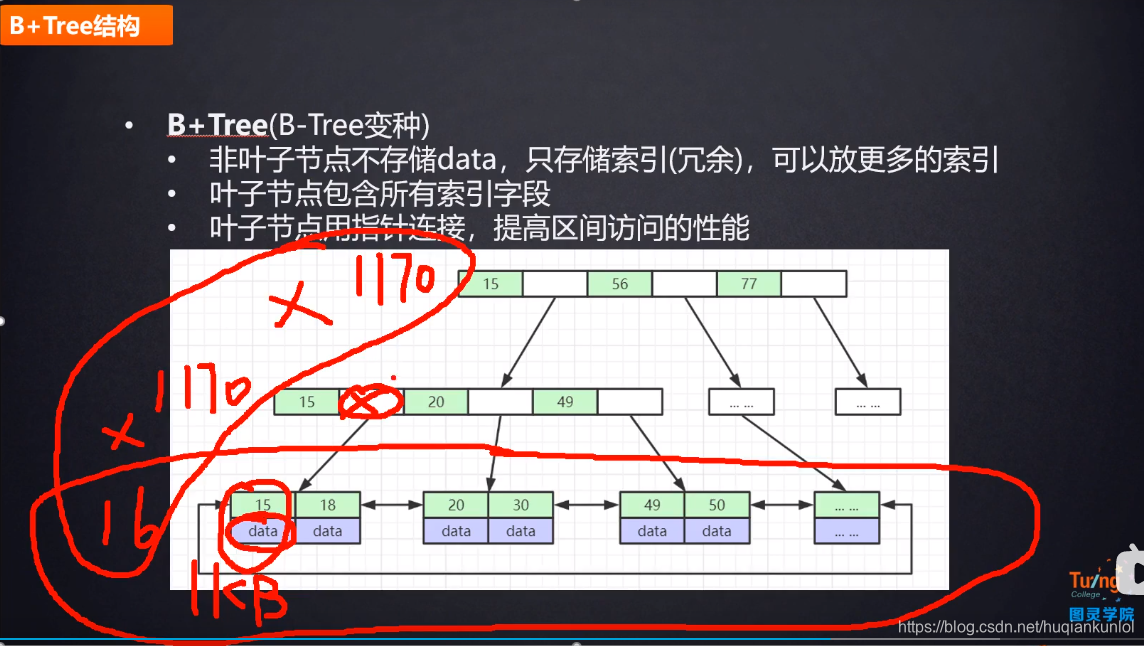
我们先看下B+数的数据结构,只有最下层的叶子节点,才有数据 ,上面的非叶子节点存储的都是索引

这里我们首先需要分析,mysql 一页可以存多少数据,一页默认 16K , 这里我们的主键是 bigint , 长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节
16x1024 / 14 约等于 1170 个索引 , 叶子节点上除了索引还是数据,这里假设估算一行数据占用1k,那么一页16k就是16行数据,一个三层索引的数,
大概能存 1170 X 1170 X 16 = 21902400 个索引,
所以千万级别的表,查询速度加索引和不加索引的区别就很很大
我们再看下B树索引的数据结构,非叶子节点也存在索引数据
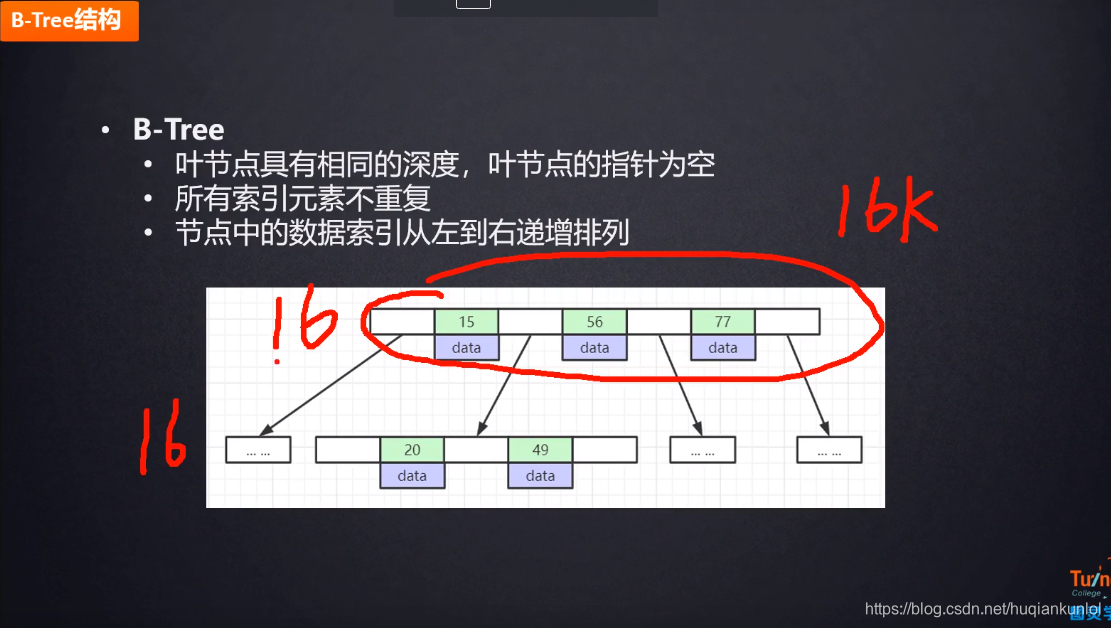
我们可以看到,在非叶子节点上也存在数据,那么根据上面的计算,一页16K,假设预计1行数据占用1K,那么这么一页存放的数据不到 16 个索引,假设能存16个索引,那么一个三层B+数可以存放两千多万个索引,如果是B树 则需要 16 的 n 次方 = 21902400 ,这个 n 肯定是大于 3 的,大概是 6点多。
根据上面我们的计算,可以出,在数据量大的情况下,使用B+树,可以减少IO的次数
(学习视频来自图灵学院)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









