







 本文详细介绍了PCIe(PeripheralComponentInterconnectExpress)的结构,包括其遵循的OSI模型、数据流方向,以及有效带宽计算方法。特别强调了TLP协议头对传输效率的影响,指出实际带宽受编码开销和特定要求制约。
本文详细介绍了PCIe(PeripheralComponentInterconnectExpress)的结构,包括其遵循的OSI模型、数据流方向,以及有效带宽计算方法。特别强调了TLP协议头对传输效率的影响,指出实际带宽受编码开销和特定要求制约。
1、什么是pcie
pcie是一种数组传输协议,它遵循开放系统互联网模型,自上而下分为事务层、链路层、物理层。把流向pcie组件方向的流量称为上游流量;把pcie流向网卡NIC的流量称为下游流量,如图所示:
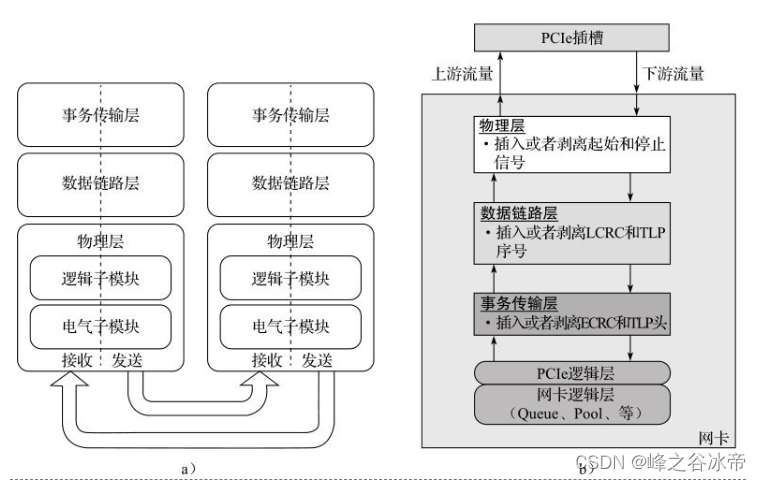
网卡和pcie插槽交互是通过pcie协议,由于它遵循开放系统互联网模型,所以网卡接收方向,是插入头的一个过程,依次增加物理层、数据链层、事务传输层。网卡发送方向是剥头的一个过程:依次剥离实物传输层、链路层、物理层。这些处理都是在硬件层次处理的。
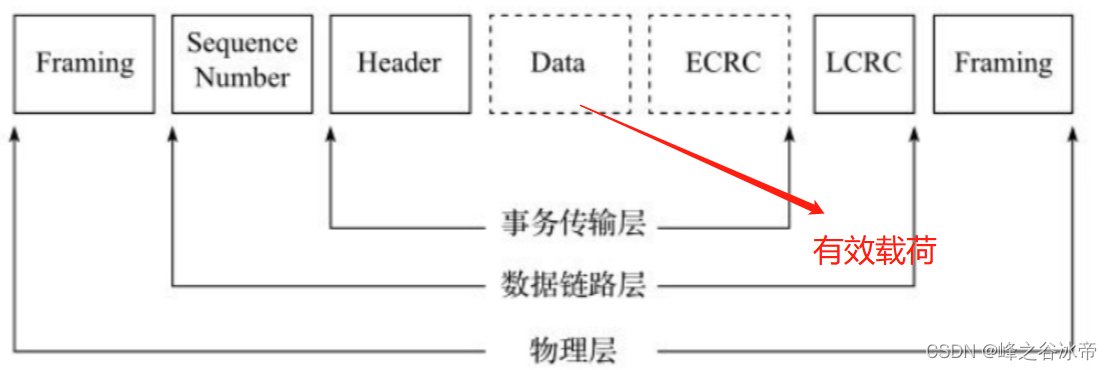 网卡从线路上接收的以太网包整个作为有效载荷在PCIe的事务传输层上进行内部传输。
网卡从线路上接收的以太网包整个作为有效载荷在PCIe的事务传输层上进行内部传输。
2、pcie有效带宽
以8b/10b编码为例,每10个比特传输8个比特(1个字节)的有效数据。以GEN2x8 5.0Gbit/s为例,500M*10b/s=500MB/s单向每路,对于8路就有4GB/s的理论带宽,这个结论是这样计算出来的:由于GEN2是以8b/10b编码,,那么单条Lane(线路)的理论最大传输速率为:
500 M * 10 bit/s / 8 = 62.5 MB/s
而对于PCIe x8配置,意味着有8条独立的Lane并行传输数据,因此8条Lane合并后的理论有效带宽为:
62.5 MB/s * 8 = 500 MB/s 或者 4 Gbps(千兆比特每秒)
注意:这里所说的带宽是指理论有效带宽,也就是扣除编码开销后,实际能够传输的有效数据量
3、pcie的传输能力
因为有些网卡的要求,每个TLP都要从lan0开始,并且从偶数时钟周期开始,这样在TLP协议头本身的开销外又增加了一些额外的开销,以64B数据纯写操作为例:
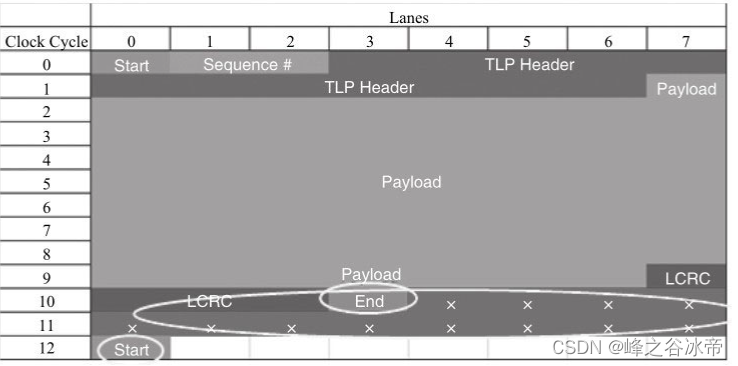
如上图所示,传输64字节,加上TLP协议头,以及偶数时钟开始等要求,最终需要96B,如果涉及真实的网卡转发流程,带宽还会进一步降低。

















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









