






 这是一个简单的Java词法分析器,用于大作业。程序主要分为基础字符和识别转化两部分,通过UML图、主代码、工具类和字符类进行详细设计。分析器识别标识符、常数、保留字、运算符、界符,并处理非法字符。目前存在部分特殊情况未处理,如英文字母加分界符的情况。
这是一个简单的Java词法分析器,用于大作业。程序主要分为基础字符和识别转化两部分,通过UML图、主代码、工具类和字符类进行详细设计。分析器识别标识符、常数、保留字、运算符、界符,并处理非法字符。目前存在部分特殊情况未处理,如英文字母加分界符的情况。
Java_Lexical-Analyzer
简单java词法分析器,大作业
程序设计思路
大体两个部分:基础字符、识别转化
- 基础字符
父类:识别字符、添加字符、得到字符、字符编号(符号为自身编号)
-
识别转化
转为二维列表进行字符识别添加字符标识符
逻辑拼接
详细设计
- 标识符设计
用户输入动态添加
identifier
Arraylist[]
字符种类:1
- 常数
constant
Arraylist[]
字符种类:2
-
保留字
keyWords
Arraylist[]
字符种类:3
-
运算符
operator
Arraylist[]
字符种类:4
-
界符
delimiters
Arraylist[]
字符种类:5
-
非法字符
字符种类:0
-
英文字符
字符种类:6
中间临时使用
uml图
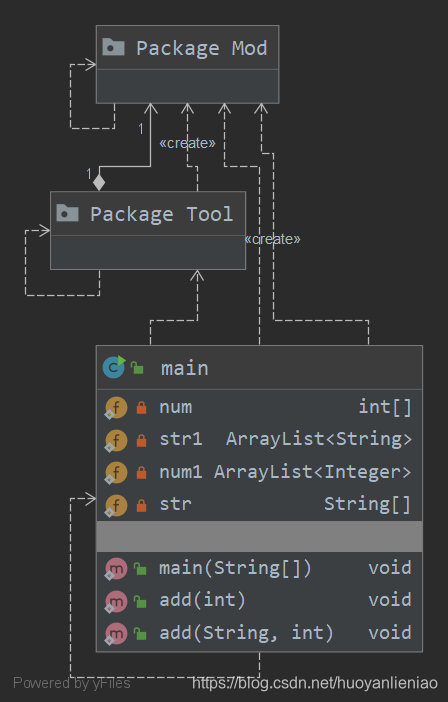
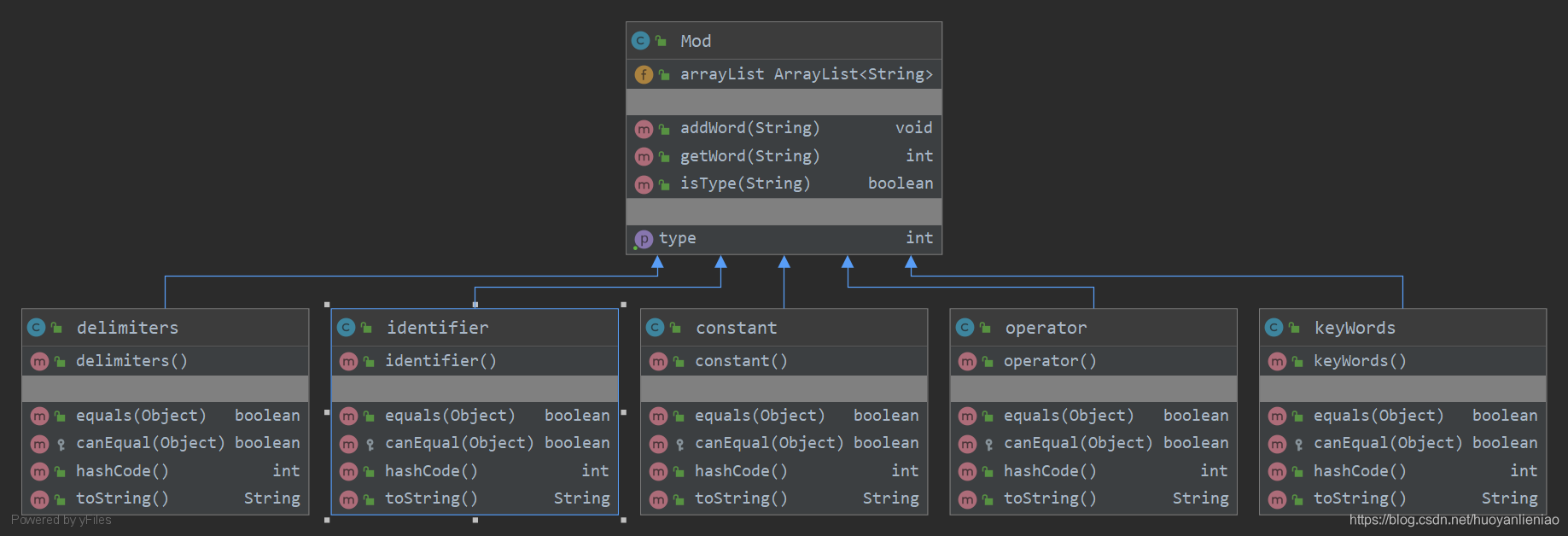
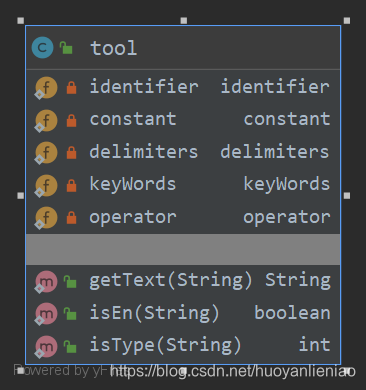
主代码
import Mod.*;
import Tool.tool;
import java.io.*;
import java.util.ArrayList;
public class main {
//第一遍临时保存
private static int[] num;
//最终输出
private static ArrayList<String> str1 = new ArrayList<>();
private static ArrayList<Integer> num1 = new ArrayList<Integer>();
//文件读取字符串
private static String[] str;
public static void main(String[] args) throws IOException {
identifier identifier = new identifier();
constant constant = new constant();
delimiters delimiters = new delimiters();
keyWords keyWords = new keyWords();
operator operator = new operator();
String filePath="src\\text";
str = tool.getText(filePath).split(" ");
num=new int[str.length];
//第一轮判断
for (int i = 0; i < str.length; i++) {
num[i]=tool.isType(str[i]);
}
//第二轮处理
for(int i=0;i<str.length;i++){
//去空
if(str[i].equals("")){
}else{
if(num[i]!=0){
if(num[i]==6){
//单独英文字符添加
num[i]=identifier.getType();
identifier.addWord(str[i]);
}
//可以直接识别字符,直接添加
add(i);
}else if(str[i].length()==1){
//如果是未识别的,长度为1
switch (tool.isType(str[i])){
case 2://constant
num[i]=constant.getType();
add(i);
break;
case 4://operator
num[i]=operator.getType();
add(i);
break;
case 5://delimiters
num[i]=operator.getType();
add(i);
break;
default://什么都不是,设为0
num[i]=0;
add(i);
break;
}
}else{
//长度不为1,字符串切割
String[] strings=str[i].split("");
for(int j=0;j<strings.length;j++){
String ss="";
switch (tool.isType(strings[j])){
case 2:
//判断数字,如果是数字则一直判断直到不是数字
while (j<strings.length&&constant.isType(strings[j])){
ss=ss+strings[j];
j++;
}
j--;
add(ss,2);
break;
case 6:
//ss,s0,s0s
//如果是英文则判断英文|数字
while (j<strings.length&&(tool.isEn(strings[j])||constant.isType(strings[j]))){
ss=ss+strings[j];
j++;
}
//这里最后一次多加了一次,所以需要减少一次
j--;
add(ss,1);
identifier.addWord(ss);
break;
case 4:
//运算符多判断后面一位
if((j+1<strings.length)&&(operator.isType(strings[j+1]))){
//如果下一个也是运算符则视为一个
ss=ss+strings[j]+strings[j+1];
add(ss,4);
j++;
}else{
//将本身添加进去
add(strings[j],4);
}
break;
case 5:
//分界符则
str1.add(strings[j]);
num1.add(delimiters.getType());
break;
default:
//默认则设为0
add(strings[j],0);
break;
}
}
}
}
}
//输出
for(int i=0;i<str1.size();i++){
switch (num1.get(i)){
case 1: System.out.println("(1,"+identifier.getWord(str1.get(i))+")");break;
case 2: System.out.println("(2,"+str1.get(i)+")");break;
case 3: System.out.println("(3,"+str1.get(i)+")");break;
case 4: System.out.println("(4,"+str1.get(i)+")");break;
case 5: System.out.println("(5,"+str1.get(i)+")");break;
case 0: System.out.println("(0,"+str1.get(i)+")");break;
}
}
}
/**
* Description str1,num1添加
* @param i
* @author sun
* @date 2021/4/12 13:26
*/
public static void add(int i){
str1.add(str[i]);
num1.add(num[i]);
}
/**
* Description str1,num1添加
* @param str
* @param i
* @author sun
* @date 2021/4/12 13:26
*/
public static void add(String str, int i){
str1.add(str);
num1.add(i);
}
}
工具类
package Tool;
import Mod.*;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
public class tool {
private static identifier identifier = new identifier();
private static constant constant = new constant();
private static delimiters delimiters = new delimiters();
private static keyWords keyWords = new keyWords();
private static operator operator = new operator();
/**
* @Description: 获取文件内容
* @Param: [filePath]
* @return: java.lang.String
* @Author: sun
* @Date: 2021/4/11
**/
public static String getText(String filePath) throws IOException {
File file = new File(filePath);
BufferedReader reader = null;
StringBuffer sbf = new StringBuffer();
reader = new BufferedReader(new FileReader(file));
String tempStr;
while ((tempStr = reader.readLine()) != null) {
sbf.append(tempStr);
}
return String.valueOf(sbf);
}
/**
* Description 判断英文字符
* @param str
* @return boolean
* @author sun
* @date 2021/4/12 13:22
*/
public static boolean isEn(String str) {
if(!str.equals("")){
char[] ch=str.toCharArray();
if(Character.isLowerCase(ch[0])||Character.isUpperCase(ch[0])){
return true;
}
}
return false;
}
/**
* Description isType封装;
* identifier 1
* constant 2
* keyword 3
* operator 4
* delimiters 5
* engilsh 6
* @param str
* @return int
* @author sun
* @date 2021/4/11 21:06
*/
public static int isType(String str) {
int result;
if (identifier.isType(str)) {
result = identifier.getType();
} else if (constant.isType(str)) {
result = constant.getType();
} else if (keyWords.isType(str)) {
result = keyWords.getType();
} else if (operator.isType(str)) {
result = operator.getType();
} else if (delimiters.isType(str)) {
result = delimiters.getType();
} else if (str.length() == 1 && isEn(str)) {
result = 6;
} else {
//不属于所有的则设为0
result = 0;
}
return result;
}
}
字符类
package Mod;
import javax.lang.model.util.Types;
import java.util.ArrayList;
import java.util.Arrays;
/**
* @ProjectName: Java_Lexical-Analyzer
* @Package: Mod
* @ClassName: Mod
* @Author: SUN
* @Description: father
* @Date: 2021/4/11 13:34
* @Version: 1.0
*/
public class Mod {
public int type;
public ArrayList<String> arrayList;
public void addWord(String s){
if(!arrayList.contains(s)){
arrayList.add(s);
}
}
public int getWord(String a){
return arrayList.indexOf(a);
}
public int getType(){
return type;
}
public boolean isType(String s){
if(arrayList.contains(s)){
return true;
}else {
return false;
}
}
}
字符子类继承父类,对type及arraylist进行赋值
package Mod;
import java.util.ArrayList;
import java.util.Arrays;
public class delimiters extends Mod {
public delimiters() {
super.type = 5;
super.arrayList = new ArrayList<>(Arrays.asList(";", ",",".","[","]","(",")","{","}"));
}
}
不足
部分情况并没有进行处理 :例如英文字母+分界符 num[],num[i]

















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









