







方法
方法分为三个核心阶段:从简短的经验中学习,基于经验的评估,以及从自我指导的经验中再培训。初始阶段强调为模型配备基本的指令遵循能力。随后的阶段引入了一个新的度量来评估每个样本的指令遵循难度评分,该评分基于先前训练的先验模型。最后,在获得目标数据集中的难度分数后,选择樱桃样本来训练最终模型。
1. 从简短的经验中学习
先喂给模型一些目标数据集的子集,这一部分主要涉及到子集要如何选择。
假设我们的原始数据集有n对三元对x=(指令,输入,回答)。

这个公式的意思就是,把每一条数据的
Q
u
e
s
t
i
o
n
Question
Question部分输入
L
L
M
LLM
LLM,得到每个token的输出,然后对所有token取平均。
得到了每一条数据的 r e p r e s e n t a t i o n representation representation后,使用 K − m e a n s K-means K−means聚类,然后对每个聚类 s a m p l e sample sample,得到一个子集。
2. 基于经验的评估
首先是条件回答概率:

条件回答概率衡量了微调后的模型,在给定上下文的情况下,回答出标准答案的概率。
然后是直接回答概率:

给定一个大模型,没有上下文,给出这个回答的概率是多少。
最终的
I
F
D
IFD
IFD得分就是二者相除:

通常,由于下一个标记预测的内在性质,条件回答分数总是小于直接回答分数:有了给定的上下文,后一个标记的预测应该更容易。因此,如果IFD分数大于1,则条件回答分数甚至大于直接回答分数,这意味着给定的指令没有为预测反应提供有用的上下文。在这种情况下,我们认为指令和相应的响应之间存在不一致,剔除。
实验
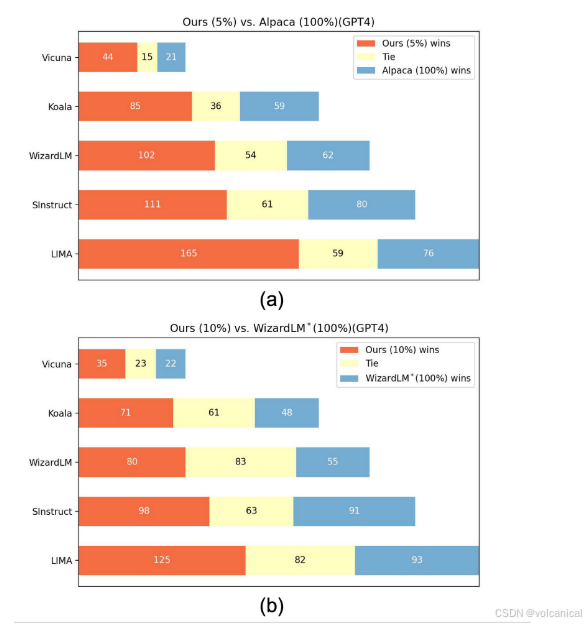
1. 对战实验
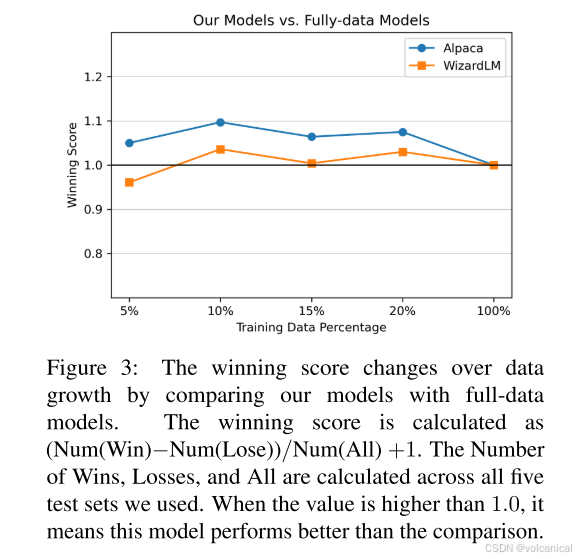
2. 不同数据比例下,胜率的变化
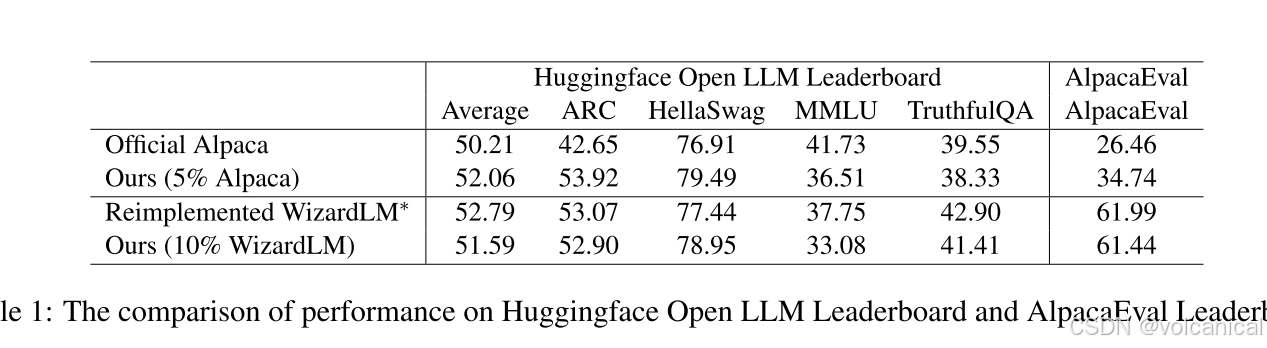
3. Leaderboard
消融
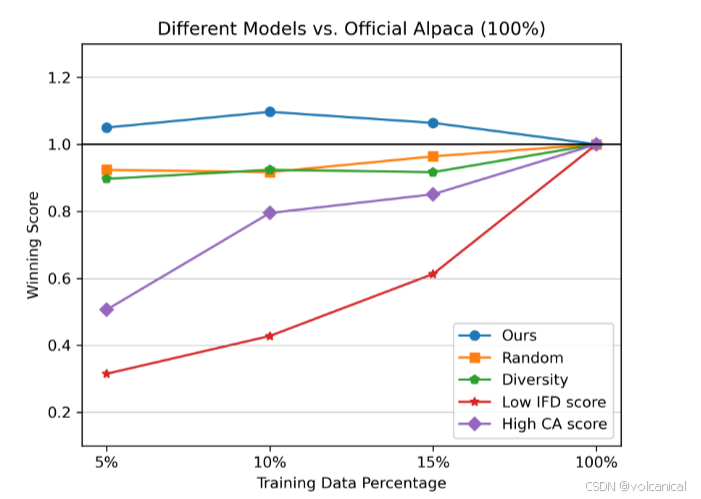
比较神奇的是,使用CA score(就是输入问题之后,对回答的困惑度),挑选困惑度高的数据,训练出来的解决居然更差,说明除以直接回答分数还是有用的。
Cherry数据的特点
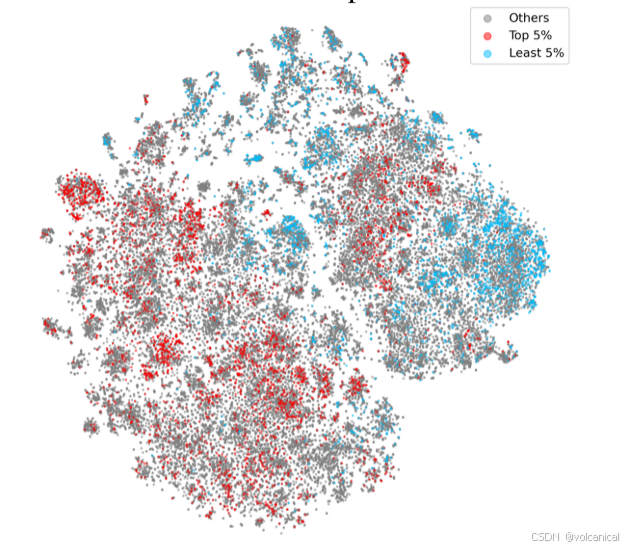
与传统观念相反,樱桃数据并不是均匀分散的。相反,高难度和低难度的样本之间存在明确的界限,挑战了先前的假设,即选择的数据应该跨越整个指令谱并最大化多样性。

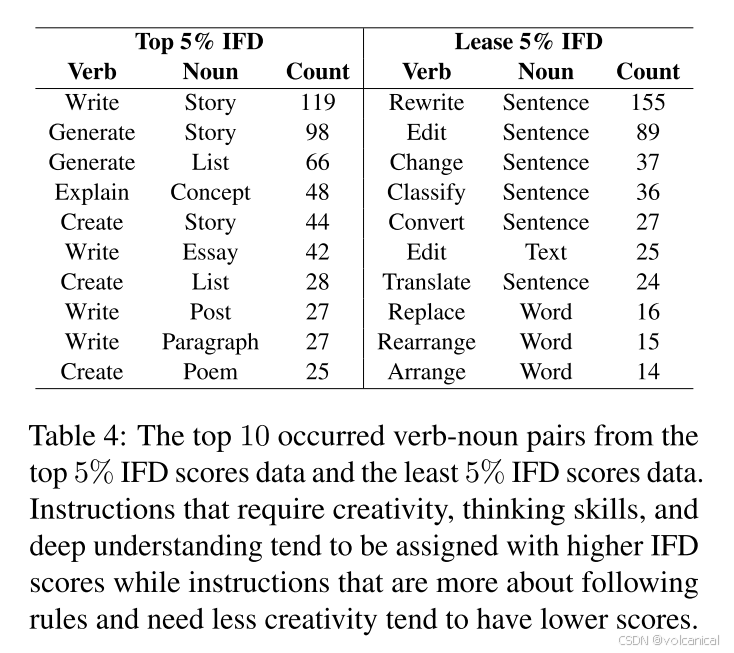
由低IFD分数样本主导的集群充满了编辑标点、单词或句子等基本任务。相比之下,IFD得分高的群体通常是更深入、更复杂的任务,比如讲故事或解释现象。
本实验揭示了高ifd数据与低ifd数据的模式特征存在明显差异。高ifd数据主要涉及创造性和复杂的指令,如“写故事”、“生成列表”、“解释概念”,这些指令需要大量的创造力、思维能力和深刻的理解。相反,低ifd数据更多的是遵循规则,需要较少的创造力,这表明不同任务对语言模型的思维和创造力的需求差异很大。因此,IFD之所以是数据过滤的有效指标,可以归结为它能够找到需要更多创造力和深入理解的指令。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











