



- LeetCode90子集 II
题目描述:
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例:
输入: [1,2,2]
输出:
[
[2],
[1],
[1,2,2],
[2,2],
[1,2],
[]
]
2. 代码实现
int comp(const void *a, const void *b)
{
return *(int*)a - *(int*)b;
}
int count(int num, int k) {
int count = 0;
for (int i = 0; i < k; i++) {
if(num & 1)
count++;
num >>= 1;
}
return count;
}
int** subsetsWithDup(int* nums, int numsSize, int* returnSize, int** returnColumnSizes){
qsort(nums, numsSize, sizeof(int), comp);//从小到大排序
int t = (int)pow(2, numsSize);
*returnSize = t;
int **result = (int**)malloc(t * sizeof(int*));
returnSize[0] = (int*)malloc(t * sizeof(int));
int k, size;
for (int i = 0; i < t; i++) {
returnColumnSizes[0][i] = count(i, numsSize);
result[i] = (int*)malloc(returnColumnSizes[0][i] * sizeof(int));
k = i;
size = 0;
for (int j = 0; j < numsSize; j++) {
if (k & 1)
result[i][size++] = nums[j];
k >>= 1;
}
}
return result;
}
3.报错信息
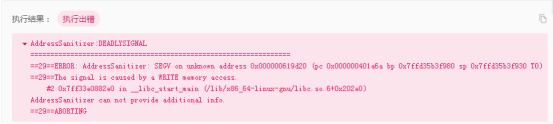
AddressSanitizer:DEADLYSIGNAL
=================================================================
==29==ERROR: AddressSanitizer: SEGV on unknown address 0x000000619d20 (pc 0x000000401a6a bp 0x7ffd35b3f980 sp 0x7ffd35b3f930 T0)
==29==The signal is caused by a WRITE memory access.
#2 0x7ff33e0882e0 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x202e0)
AddressSanitizer can not provide additional info.
==29==ABORTING
从报错信息看,是内存泄漏问题,和数组指针操作有关,通过排查发现是在代码行
returnSize[0] = (int*)malloc(t * sizeof(int));
实际改为
returnColumnSizes[0] = (int*)malloc(t * sizeof(int));
4.修改后正确代码
int comp(const void *a, const void *b)
{
return *(int*)a - *(int*)b;
}
int count(int num, int k) {
int count = 0;
for (int i = 0; i < k; i++) {
if(num & 1)
count++;
num >>= 1;
}
return count;
}
int** subsetsWithDup(int* nums, int numsSize, int* returnSize, int** returnColumnSizes){
qsort(nums, numsSize, sizeof(int), comp);//从小到大排序
int t = (int)pow(2, numsSize);
*returnSize = t;
int **result = (int**)malloc(t * sizeof(int*));
returnColumnSizes[0] = (int*)malloc(t * sizeof(int));
int k, size;
for (int i = 0; i < t; i++) {
returnColumnSizes[0][i] = count(i, numsSize);
result[i] = (int*)malloc(returnColumnSizes[0][i] * sizeof(int));
k = i;
size = 0;
for (int j = 0; j < numsSize; j++) {
if (k & 1)
result[i][size++] = nums[j];
k >>= 1;
}
}
return result;
}

















 7900
7900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









