



B+树的存储容量取决于多个因素,包括树的阶(即每个节点的最大子节点数)、键的大小和每个节点的容量。计算一棵B+树能存储多少条数据,通常需要了解以下参数:
- 节点大小:一般情况下,节点大小等于数据库页大小(通常为4KB、8KB或16KB)。
- 键的大小:每个键的大小取决于索引列的数据类型。
- 指针大小:每个指针(指向子节点或数据记录)占用的空间,通常是固定大小的,比如8字节。
假设:
- 节点大小:8KB = 8192字节
- 键的大小:16字节(例如,一个整数键4字节,加上其他元数据)
- 指针大小:8字节
计算每个节点的阶
假设每个节点最多能存储 n 个键和 n+1 个指针。每个键加上一个指针占用的空间为:
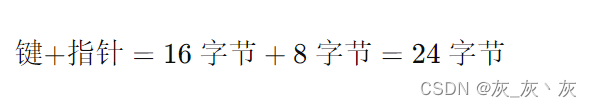
一个节点最多能存储的键数 n 可以通过以下公式计算:

对于一个8KB的节点:
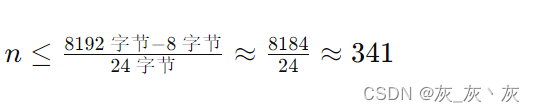
所以,每个节点最多可以存储341个键和342个指针。
计算B+树的存储容量
对于一棵高度为 h 的B+树(根节点高度为0),其最大存储容量 M(h) 可以通过递归公式计算:
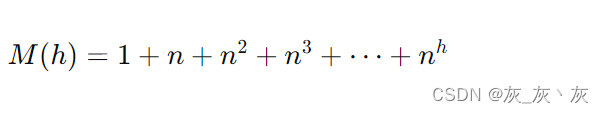
由于 B+树的节点是满的,所以可以近似为:

假设我们有一棵高度为3的B+树,其存储容量为:
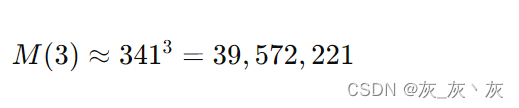
即,一棵高度为3的B+树大约能存储近4000万条记录。
实际应用中的考虑
- 页大小:不同数据库系统的页大小不同,常见的有4KB、8KB、16KB甚至更大。
- 键的大小:索引列的数据类型不同,键的大小也会不同。例如,字符串索引的键比整数索引的键大得多。
- 内部节点和叶子节点的不同:B+树的内部节点和叶子节点存储的数据不同,内部节点存储键和指针,叶子节点存储键和实际数据记录或指向数据记录的指针。
- 数据库实现的细节:不同的数据库系统对B+树的实现细节可能不同,影响其实际的存储容量。
总结
一棵B+树能存储的数据量取决于多种因素,包括节点大小、键的大小和树的高度。一般来说,随着B+树的高度增加,树的存储容量呈指数增长。在实际应用中,需要根据具体的数据库实现和数据特征来计算和优化B+树的存储容量。

















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









