







数组特点是查找容易,插入删除困难;链表特点是查找困难,插入删除容易。而散列表可以取数组与链表的优点。
散列表就是把key通过一个固定算法函数(哈希函数)转换成一个整型数字,再将该数字对数组长度取余,取余的结果就当做数组下标,后将value存储在以该取余结果为下标的数组中。
公式: 存储位置 = f(关键字)
实例:
#include "stdafx.h"
#include <stdlib.h>
#define OK 1
#define ERROR 0
#define SUCCESS 1
#define UNSUCCESS 0
#define HASHSIZE 20
#define NULLKEY -111
int m = 0; // 散列表长度,全局变量
typedef struct
{
int *elem; // 元素基地址,动态分配数组
int count; // 数据元素个数
}HashTable;
// 初始化散列表
int InitHashTable(HashTable *h)
{
int i;
m = HASHSIZE;
h->elem = (int *)malloc(sizeof(int) * m);
if (NULL == h->elem)
{
fprintf(stderr, "malloc error!\n");
return ERROR;
}
for (i = 0; i < m; i++)
{
h->elem[i] = NULLKEY;
}
printf("初始化散列表%d个元素成功!\n", m);
return OK;
}
//散列函数
int Hash(int key)
{
printf("散列函数返回下标 %d!\n", (key % m));
return key % m; // 除留余数法
}
// 插入关键字进散列表
void InsertHash(HashTable *h, int key)
{
int addr = Hash(key); //求散列地址
while (h->elem[addr] != NULLKEY) //若不为空,则产生冲突
{
addr = (addr + 1) % m; //开放定址法的线性探测
}
h->elem[addr] = key; //将关键字插入
printf("插入关键字进散列表成功!\n");
}
// 散列表查找关键字
int SearchHash(HashTable h, int key)
{
int addr = Hash(key); // 求散列地址
while (h.elem[addr] != key) // 若所寻地址关键字不相等,则寻找下一个,直到找到为止
{
addr = (addr + 1) % m; // 开放定址的线性探测
if (NULLKEY == h.elem[addr] || addr == Hash(key))
{
// 若循环查找到原点
printf("查找失败, %d 不在Hash表中!\n", key);
return UNSUCCESS;
}
}
printf("查找成功, %d 在Hash表第 %d 个位置!\n", key, addr);
return SUCCESS;
}
int main(void)
{
int i,num = 0;
HashTable h;
printf("test begin\n");
//初始化散列表
InitHashTable(&h);
//未插入数据之前,打印Hash表
printf("未插入数据之前,Hash表中内容为:\n");
for (i = 0; i < HASHSIZE ; i++)
{
printf("%d ", h.elem[i]);
}
printf("\n");
//插入数据
printf("现在插入数据,请输入(c表示结束):\n");
while ((1 == scanf_s("%d", &i)) && (num < HASHSIZE))
{
if ('c' == i)
{
break;
}
num++;
InsertHash(&h, i);
if (num > HASHSIZE)
{
printf("插入数据超过Hash表大小!\n");
getchar();
return ERROR;
}
}
getchar();
// 打印插入数据后Hash表的内容
printf("插入数据后Hash表的内容: \n");
getchar();
for ( i = 0; i < HASHSIZE; i++)
{
printf("%d ", h.elem[i]);
}
printf("\n");
printf("现在进行查询。\n");
SearchHash(h, 18);
SearchHash(h, 190);
printf("test over\n");
getchar();
return 0;
}
输出: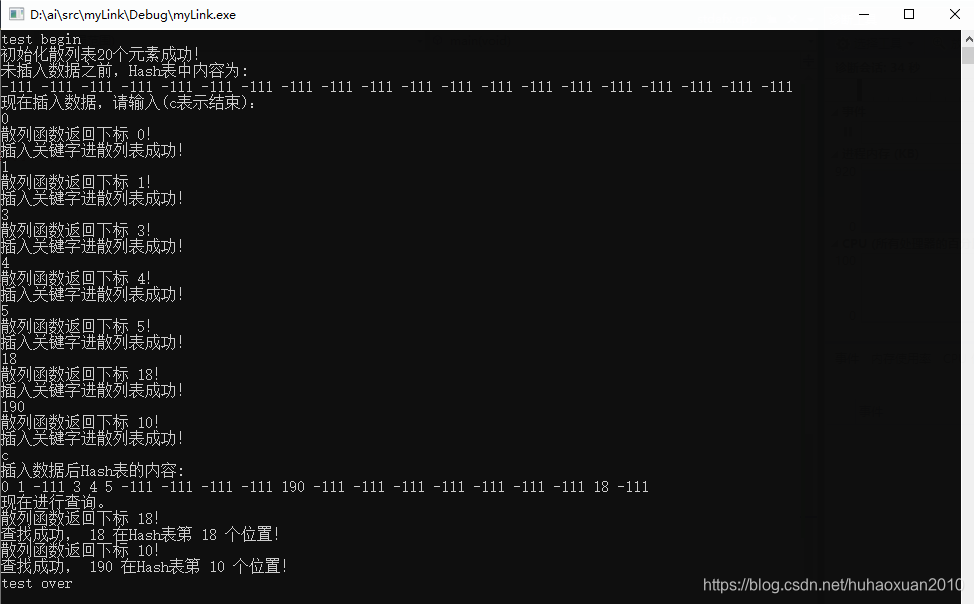
哈希函数有:
a. 除留余数法:
对散列表长度为m的散列函数有公式: f (key) = key mod p (p ≤ m) ; mod表示取余,这里关键是需要选择合适的p,若p没选好,容易产生碰撞。经验上若散列表的表长为m,一般p为小于或等于表长的最小质数或不包含小于20质因子的合数。该方法最常用。另外它的取余操作,还可经过折叠,平放取中后再取余。
b.折叠法:
将关键字从左到右分割成位数相等的几部分(最后一部分位数不够时可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
如关键字0123456789,散列表表长度为3位,可将它分为4组,012|345|678|9,再叠加求和:012 + 345 + 678 + 9 = 1044,再求后3位得到散列地址044。
折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况。
c.平方取中法:
假设关键字为123,则它的平方是15129,再抽取中间的3位就是512,用作散列表。平方取中法比较适合不知道关键字的分布,而位数又不是很大的情况。
d.直接定址法 --- 取关键字的某个线性函数值为散列地址(f(key) = a * key + b ; a, b为常数)
散列冲突:
一般正常情况每个关键字通过散列函数计算出来的地址是不一样的,但有时会碰到两个关键字key1和key2不相等,但是经过散列函数计算出来的索引地址却是一样的。出现这种情况说明散列冲突了。
散列冲突会导致查找错误,通过仔细设计散列函数能够将冲突尽可能减少,但是不能完全避免。
开放定址法:就是一旦发生冲突,再去寻找下一个空的散列地址,只要散列表足够大,总能够找到一个空的散列地址,并将记录存入其中,上面实例使用的就是这种方法。
还有其他散列冲突方法。
参考文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









