




What
Flink实现了各种类型的连接器(Connector)来实现数据在不同平台上的读写。使用Java和Scala编程支持Kafka、Twitter、RabbitMQ、ElasticSearch、Cassandra等各种组件和Flink的整合。Flink既可以把数据输出给Kafka,也可以接收从Kafka输入的数据。
How(Flink -> KAFKA)
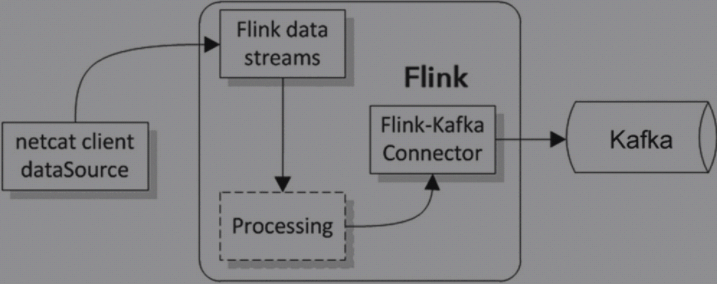
- 环境
a. KAFKA: Version2.13
b. Flink: Version1.11 - POM配置
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11.1</version>
</dependency>
- 代码
package com.xiaohei;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
public class Flink2Kafka {
public static void main(String[] args) throws Exception {
//创建执行环境
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
//创建Source
DataStream<String> lines = env.socketTextStream("xx.xx.xx.xx", 9090);
//创建Sink
FlinkKafkaProducer<String> myProducer = new FlinkKafkaProducer<String>(
"xx.xx.xx.xx:9092",
"my-topic",
new SimpleStringSchema()
);
//给Source添加Sink
lines.addSink(myProducer);
lines.print();
//执行Flink
env.execute("flink2kafka test");
}
}
How(KAFKA -> Flink)
- 环境
a. KAFKA: Version2.13
b. Flink: Version1.11 - POM配置
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11.1</version>
</dependency>
- 代码
package com.xiaohei;
import com.xiaohei.rep.PageCount;
import com.xiaohei.util.MapUtil;
import org 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









