







pyspider互动百科词条爬取
首页:
百科类网站在反爬方面一般不会很难,但是在数据完整度上面要求更加高,难度几乎都是在怎么才能拿到大量的完整数据,互动百科有1700万词条,想要拿到大部分数据,在爬取规则上面就要多想一点。
先看一下要爬取的一般词条网页信息:
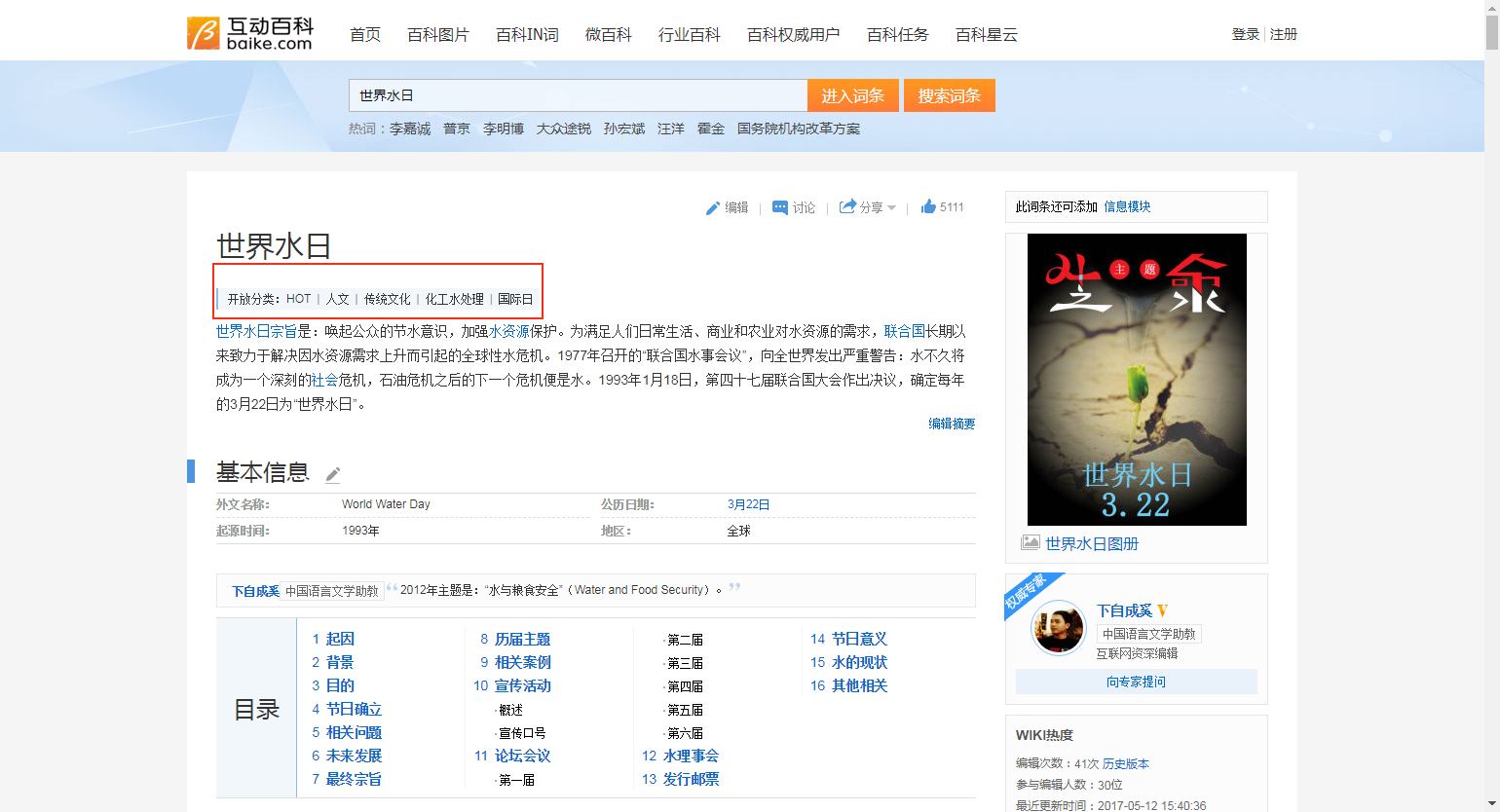
开始也走了一些弯路,因为爬取规则的问题,爬到的数据量太少,当然最后也找到了一条路。
先是找到了这么一个页面,当然依赖这个爬出来的数据也不全面。但这也给了我思路,依赖分类去爬取数据。
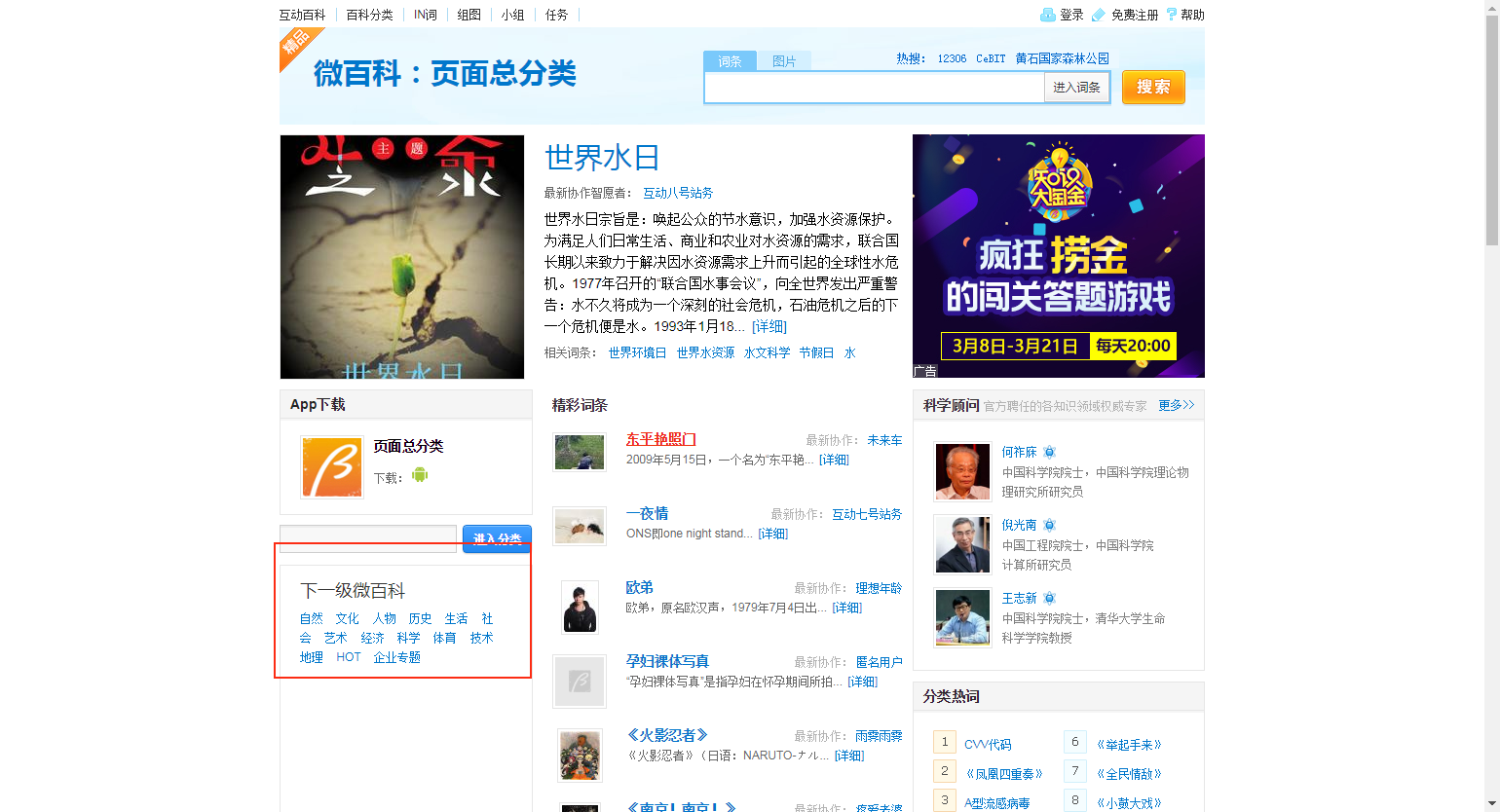
首先就是这个总分类界面能看到上面的大分类,我就依赖这个先进行广度+深度的分类内容的爬取。看到上图的其他内容,有类似“精彩词条,分类热词”的就是我需要的东西,当然这也不全面啊。
接着往下拉页面,又能看到这个“全部词条”,这个全部词条里面就是与这个分类有关的一些词条。现在数据就相对完整了。再往下拉界面,应该可以看到下图,“全部词条”里面的内容和这个分页所包含的差不多,所以就用“全部词条“里面的了。其实这分页也是反爬手段,最多给100页(我试过下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









