




 本文介绍了一种简单的爬虫实践案例,利用Python的requests和beautifulsoup4库抓取中国天气网的城市天气数据,并通过数据分析找出全国最热的城市。文章详细介绍了爬虫的实现步骤及技巧。
本文介绍了一种简单的爬虫实践案例,利用Python的requests和beautifulsoup4库抓取中国天气网的城市天气数据,并通过数据分析找出全国最热的城市。文章详细介绍了爬虫的实现步骤及技巧。
哪个城市最热?
现如今,我大天朝举国上下都处于一种高温的状态。那么这里我们也来蹭一蹭热度,来写个小爬虫,看看全国哪个城市最热。东西虽然小,但是比起那些所谓“高大上”的教程来说,这篇文章比较脚踏实地,不玩虚的,你看完后一定可以学会的。
准备工作:
在做爬虫之前,首先对爬虫的解题路径做个简单概述。一个爬虫工作分为两步骤:
- 第一步:把你需要爬取的那个网页的数据全部拉下来。
- 第二步是把从网站上拉下来的数据进行过滤,把你需要的提取出来,把不需要的给过滤掉。这就是爬虫的工作原理。
我们要爬取的网站数据不是特别大,复杂度也不高。因此为降低大家学习爬虫的难度。我们不上那些很复杂的框架,比如
Scrapy,而是直接使用一个简单又好用的第三方库帮我们完成爬虫任务,那就是requests库。requests库是一个专门用来从网站上拉取数据的库,也就对应了我们爬虫工作的第一步——从网站上拉取数据。这个库的使用,后面我们会讲到,如果您还没有安装这个库,那么可以通过以下命令进行安装:pip install requests。如果您使用的是Linux或者Mac OS系统,那么最好在前面加上一个sudo pip install requests,不然很容易会因为权限问题而安装失败。在使用
requests库把数据拉取下来以后,接下来的工作就是对这些数据进行分析和过滤了。这时候我们使用的一个第三方库是beautifulsoup4。这个库是专门用来解析网页数据的。并且为了使接下效率更高,一般我们推荐使用lxml来作为解析的引擎。因此,要使用beautifulsoup库,要通过以下命令来安装:# 安装lxml pip install lxml # 安装beautifulsoup4 pip install bs4
中国天气网分析:
这里我们需要爬取的网站是:中国天气网http://www.weather.com.cn/textFC/hb.shtml#。我们做任何爬虫之前,都需要对这个网站进行详细的分析,一定要达到了如指掌的境地。不然后面很容易在数据过滤的时候会出现一个问题,这也是所有做爬虫需要注意的地方。我们这里就跟大家分析一下中国天气网的网站:
在以上这个中国天气网的页面中。我们可以看到,他是通过区域的方式把全国个大省份和城市进行区分的,有:华北、东北、华东、华中、华南、西北、西南、港澳台。在每个区域下面,都是通过表格的形式把属于该区域下的所有省份以及城市的天气信息列出来。因此我们要做的是,首先找到所有的区域的链接,然后再在每个区域的链接下把这个区域下的所有的城市天气信息爬出来就可以了。

1.png我们已经知道只要拿到了所有的区域链接,就可以在这个链接的网页中把这些城市拿到。那么如何去拿到这个区域下对应的所有城市以及他们对应的天气信息呢?这时候就需要去解析源代码了,我们点击这个页面任何一个地方,然后右键点击审查元素,打开控制台后,去寻找规则(因为这个寻找规则比较繁琐,这里就做个简单概述,如果对如何去找到相应的元素感兴趣,可以关注本公众号,会有一套详细的视频教程免费教大家查找)。我们可以看到,一个省份的城市及其天气信息,都是放在一个叫做
<div class='conMidtab2'>的盒子中。因此我们只要找到所有的conMidtab2盒子,就找到了所有的城市。但是这个地方需要注意的是,因为在一个页面中,展示了7天的数据,因此如果你按照class='conMidtab2'这个规则去寻找的话,会得到从今天往后延7天的所有数据。这时候我们就要换一个规则了,我们经过分析(具体分析过程可以看本教程视频内容)发现一天的天气信息,是放在一个class='conMidtab'的这样一个盒子中。因此我们只要把第一个conMidtab盒子拿到,就可以拿到今天的天气数据而把其他日期的数据给过滤掉。这里要给大家上一份源代码了:# find方法,只会返回第一个满足条件的元素,也即只把第一个conMidtab返回回来,把今天的数据返回回来 conMidtab = soup.find('div', class_='conMidtab') # 通过得到的这个conMidtab,我们再调用find_all方法,把这个conMidtab元素下的所有conMidtab2盒子找到,得到这一天中这个区域下所有的城市 conMidtab2_list = conMidtab.find_all('div', class_='conMidtab2')也上一份图片给大家分析一下:

2.png我们已经分析好了如何获取城市的盒子,那么接下来就是去获取城市的天气信息了。我们继续分析(具体分析过程可以看本视频教程)后发现,在
table中,前面两个tr是表头,知识用来解释数据的,我们不需要,那么真正有用的数据是从第三个tr开始的。并且第三个tr的第1个td展示的是该省或者直辖市的名称,从第二个td开始才是真正展示该省份下这个城市的详细天气情况了,这里上一张图片分析一下:
3.png并且,从第四个
tr开始,下面的td全部展示的就是这个城市的信息了,而不包括省份的信息了,这里也用一张图片来说明这个问题:
4.png所以综合以上的分析,我们就知道,省份名称是存储在
table下的第三个tr下的第0个td下,而城市名字则要进行判断,如果是第三个tr,那么就是在第二个td,如果是从第四个开始,那么就是存储在第0个td下。而最高气温也要区分,第三个tr,存储在第5个td下,从第四个tr开始,则存储在第4个td下,那么我们也可以上一份源代码,看看如何获取的:conMidtab = soup.find('div', class_='conMidtab') conMidtab2_list = conMidtab.find_all('div', class_='conMidtab2') for x in conMidtab2_list: tr_list = x.find_all('tr')[2:] province = '' for index, tr in enumerate(tr_list): # 如果是第0个tr标签,那么城市名和省份名是放在一起的 min = 0 if index == 0: td_list = tr.find_all('td') province = td_list[0].text.replace('\n', '') city = td_list[1].text.replace('\n', '') max = td_list[5].text.replace('\n', '') else: # 如果不是第0个tr标签,那么在这个tr标签中只存放城市名 td_list = tr.find_all('td') city = td_list[0].text.replace('\n', '') max = td_list[4].text.replace('\n', '') TEMPERATURE_LIST.append({ 'city': province+city, 'min': min })
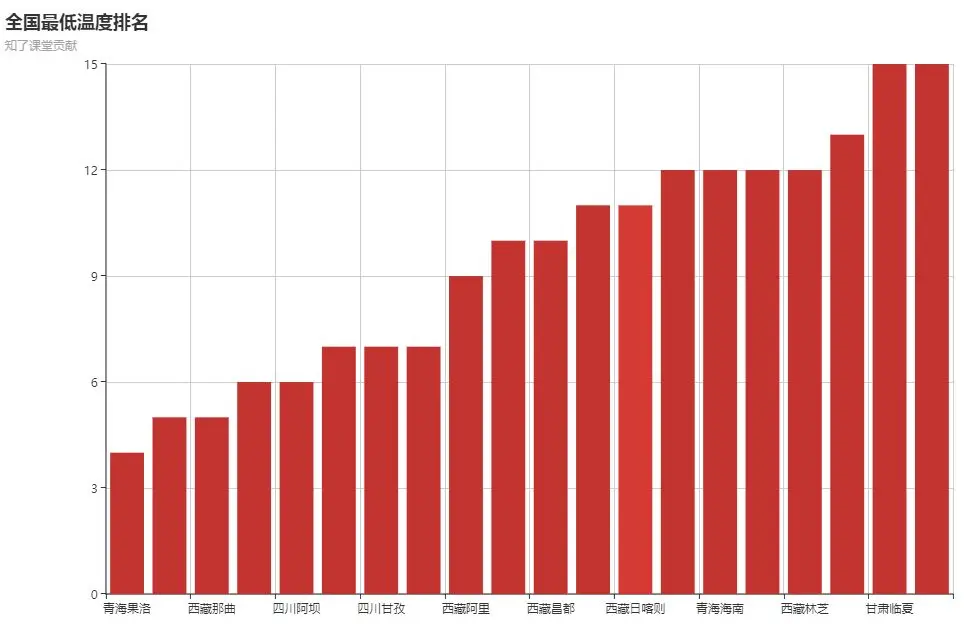
数据显示:
如果把所有数据都爬下来后,那么我们可以使用echarts-python把数据进行可视化,这部分内容比较简单,我就直接把我做的可视化的数据图给大家看下,具体的实现方式,大家可以观看我的视频教程,讲解非常详细:
写在最后:
以上是对中国天气网爬虫和数据可视化的分析,爬虫虽然简单,但也是五脏俱全,囊括了爬虫逻辑的方方面面,并且在最后还把爬取出来的数据进行了可视化,使我们爬取出来的数据有用武之地。另外,因为本教程是通过文字的形式进行传递的,要描述整个过程实在有点太难。如果还没看懂的或者是想进一步了解具体爬虫的细节的,可以看下以下课程:零基础:21天搞定Python分布式爬虫



















 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











